Elasticsearch JAVA api搞定groupBy聚合
本文给出如何使用Elasticsearch的Java API做类似SQL的group by聚合。
为了简单起见,只给出一级groupby即group by field1(而不涉及到多级,例如group by field1, field2, ...);如果你需要多级的groupby,在实现上可能需要拆分的更加细致。
即将给出的方法,适用于如下的场景:
场景1:找出分组中的所有桶,例如,select group_name from index_name group by group_name;
场景2:灵活添加一个或者多个聚合函数,例如,select group_name, max(count), avg(count) group by group_name;
1、用法
GroupBy类是我们的实现。
1)测试用例
public static void main(String[] args) {
/*
* 初始化es客户端
* */
ESClient esClient = new ESClient(
"dqa-cluster",
"10.93.21.21:9300,10.93.18.34:9300,10.93.18.35:9300,100.90.62.33:9300,100.90.61.14:9300",
false);
/*
* 为了演示, 构造了一个距离查询, 相当于where子句.
* */
GeoDistanceRangeQueryBuilder queryBuilder = QueryBuilders.geoDistanceRangeQuery("location")
.point(39.971424, 116.398251)
.from("0m")
.to(String.format("%fm", 500.0))
.includeLower(true)
.includeUpper(true)
.optimizeBbox("memory")
.geoDistance(GeoDistance.SLOPPY_ARC);
SearchRequestBuilder search = esClient.getClient().prepareSearch("moon").setTypes("bj")
.setSearchType(SearchType.DFS_QUERY_AND_FETCH)
.setQuery(queryBuilder);
/*
* GroupBy类就是我们的实现, 初始化的时候传入的参数依次是, search, 桶命名, 分桶字段, 排序asc
* select date as date_group from index group by date;
* */
GroupBy groupBy = new GroupBy(search, "date_group", "date", true);
/*
* 添加各种分组函数
* 这里我实现了10种, 下面是其中的6种
* */
groupBy.addSumAgg("pre_total_fee_sum", "pre_total_fee");
groupBy.addAvgAgg("pre_total_fee_avg", "pre_total_fee");
groupBy.addPercentilesAgg("pre_total_fee_percent", "pre_total_fee");
groupBy.addPercentileRanksAgg("pre_total_fee_percentRank", "pre_total_fee", new double[]{13, 16, 20});
groupBy.addStatsAgg("pre_total_fee_stats", "pre_total_fee");
groupBy.addCardinalityAgg("type_card", "type");
/*
* 获取groupBy聚合的结果
* 结果是两级Map, 这里的实现是TreeMap因为要保护桶的排序
* */
Map<String, Object> groupbyResponse = groupBy.getGroupbyResponse();
for (Map.Entry<String, Object> entry : groupbyResponse.entrySet()) {
String bucketKey = entry.getKey();
Map<String, String> subAggMap = (Map<String, String>) entry.getValue();
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_sum", subAggMap.get("pre_total_fee_sum")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_avg", subAggMap.get("pre_total_fee_avg")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_percent", subAggMap.get("pre_total_fee_percent")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_percentRank", subAggMap.get("pre_total_fee_percentRank")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_stats", subAggMap.get("pre_total_fee_stats")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "type_card", subAggMap.get("type_card")));
}
}
2)初始化
初始化的时候,相当于构造了这样一个SQL:select date as date_group from index group by date;
传入search对象,相当于where子句
传入分桶命名, 相当于 as date_group
传入分桶字段,相当于date
传入排序,asc=true
3)初始化完成后,可以添加各种聚合函数,也就是场景2。
GroupBy类里实现了10种聚合函数
4)读取结果
结果的返回是两级Map,为了保护分桶的排序,实现中使用了TreeMap。
这里需要注意的是,有些聚合函数的返回,并不是一个值,而是一组值,如Percentiles、Stats等等,这里我们把这一组值压缩成JSONString了。
5)打印输出
我们以日期进行了分桶,同一个分桶中的聚合结果,sum、avg、cardinality都是单个的值。而percentiles、percentileRanks、stats是压缩的jsonstring。
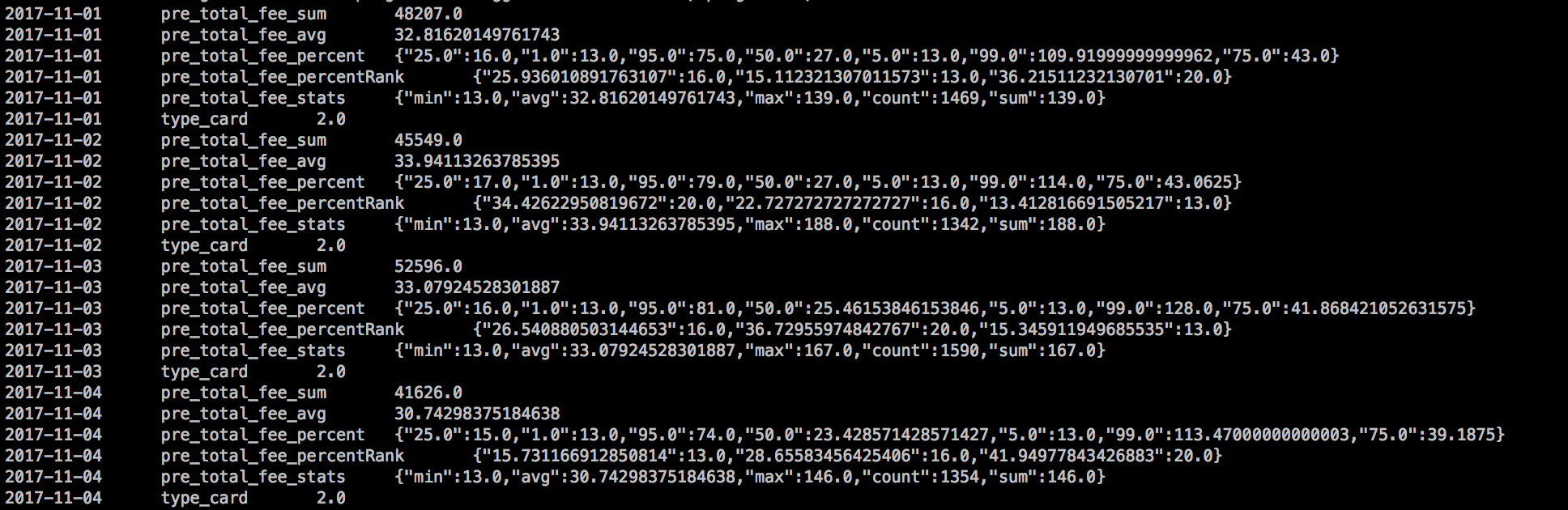
2、实现
先上代码,然后在后面进行讲解。
public class GroupBy {
private SearchRequestBuilder search;
private String termsName;
private TermsBuilder termsBuilder;
private List<Map<String, Object>> subAggList = new ArrayList<Map<String, Object>>();
public GroupBy(SearchRequestBuilder search, String termsName, String fieldName, boolean asc) {
this.search = search;
this.termsName = termsName;
termsBuilder = AggregationBuilders.terms(termsName).field(fieldName).order(Terms.Order.term(asc)).size(0);
}
private void addSubAggList(String aggName, MetricsAggregationBuilder aggBuilder) {
Map<String, Object> subAgg = new HashMap<String, Object>();
subAgg.put("aggName", aggName);
subAgg.put("aggBuilder", aggBuilder);
subAggList.add(subAgg);
}
public void addSumAgg(String aggName, String fieldName) {
SumBuilder builder = AggregationBuilders.sum(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketSumAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof SumBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addCountAgg(String aggName, String fieldName) {
ValueCountBuilder builder = AggregationBuilders.count(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketCountAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof ValueCountBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addAvgAgg(String aggName, String fieldName) {
AvgBuilder builder = AggregationBuilders.avg(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketAvgAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof AvgBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addMinAgg(String aggName, String fieldName) {
MinBuilder builder = AggregationBuilders.min(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketMinAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof MinBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addMaxAgg(String aggName, String fieldName) {
MaxBuilder builder = AggregationBuilders.max(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketMaxAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof MaxBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addStatsAgg(String aggName, String fieldName) {
StatsBuilder builder = AggregationBuilders.stats(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketStatsAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof StatsBuilder) {
Stats stats = bucket.getAggregations().get(aggName);
JSONObject jsonObject = new JSONObject();
jsonObject.put("min", stats.getMin());
jsonObject.put("max", stats.getMax());
jsonObject.put("sum", stats.getMax());
jsonObject.put("count", stats.getCount());
jsonObject.put("avg", stats.getAvg());
tmpMap.put(aggName, jsonObject.toJSONString());
return true;
} else {
return false;
}
}
public void addExtendedStatsAgg(String aggName, String fieldName) {
ExtendedStatsBuilder builder = AggregationBuilders.extendedStats(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketExtendedStatsAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof ExtendedStatsBuilder) {
ExtendedStats extendedStats = bucket.getAggregations().get(aggName);
JSONObject jsonObject = new JSONObject();
jsonObject.put("min", extendedStats.getMin());
jsonObject.put("max", extendedStats.getMax());
jsonObject.put("sum", extendedStats.getMax());
jsonObject.put("count", extendedStats.getCount());
jsonObject.put("avg", extendedStats.getAvg());
jsonObject.put("stdDeviation", extendedStats.getStdDeviation());
jsonObject.put("sumOfSquares", extendedStats.getSumOfSquares());
jsonObject.put("variance", extendedStats.getVariance());
tmpMap.put(aggName, jsonObject.toJSONString());
return true;
} else {
return false;
}
}
public void addPercentilesAgg(String aggName, String fieldName) {
PercentilesBuilder builder = AggregationBuilders.percentiles(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public void addPercentilesAgg(String aggName, String fieldName, double[] percentiles) {
PercentilesBuilder builder = AggregationBuilders.percentiles(aggName).field(fieldName).percentiles(percentiles);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketPercentilesAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof PercentilesBuilder) {
Percentiles percentiles = bucket.getAggregations().get(aggName);
JSONObject jsonObject = new JSONObject();
for (Percentile percentile : percentiles) {
jsonObject.put(String.valueOf(percentile.getPercent()), percentile.getValue());
}
tmpMap.put(aggName, jsonObject.toJSONString());
return true;
} else {
return false;
}
}
public void addPercentileRanksAgg(String aggName, String fieldName, double[] percentiles) {
PercentileRanksBuilder builder = AggregationBuilders.percentileRanks(aggName).field(fieldName).percentiles(percentiles);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketPercentileRanksAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof PercentileRanksBuilder) {
PercentileRanks percentileRanks = bucket.getAggregations().get(aggName);
JSONObject jsonObject = new JSONObject();
for (Percentile percentile : percentileRanks) {
jsonObject.put(String.valueOf(percentile.getPercent()), percentile.getValue());
}
tmpMap.put(aggName, jsonObject.toJSONString());
return true;
} else {
return false;
}
}
public void addCardinalityAgg(String aggName, String fieldName) {
CardinalityBuilder builder = AggregationBuilders.cardinality(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketCardinalityAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof CardinalityBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public List<Terms.Bucket> getTermsBucket() {
search.addAggregation(termsBuilder);
Terms termsGroup = search.get().getAggregations().get(termsName);
return termsGroup.getBuckets();
}
public Map<String, Object> getGroupbyResponse() {
Map<String, Object> aggResponseMap = new TreeMap<String, Object>();
for (Terms.Bucket bucket : getTermsBucket()) {
String bucketKeyAsString = bucket.getKeyAsString();
Map<String, String> tmpMap = new TreeMap<String, String>();
for (Map<String, Object> subAgg : subAggList) {
String subAggName = subAgg.get("aggName").toString();
MetricsAggregationBuilder subAggBuilder = (MetricsAggregationBuilder) subAgg.get("aggBuilder");
if (bucketAvgAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketMaxAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketMinAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketSumAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketCountAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketCardinalityAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketPercentileRanksAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketPercentilesAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketExtendedStatsAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketStatsAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
}
aggResponseMap.put(bucketKeyAsString, tmpMap);
}
return aggResponseMap;
}
}
1)构造函数
构造函数中,核心逻辑是termsBuilder = AggregationBuilders.terms(termsName).field(fieldName).order(Terms.Order.term(asc)).size(0);
实例化了termsBuilder也就是分桶。
后面调用add...函数簇添加聚合函数的时候,都是通过termsBuilder.subAggregation(builder)在分桶的基础上添加了子聚合。
最后在获取结果的时候search.addAggregation(termsBuilder);将termsBuilder添加到查询上,进行聚合查询。
2)添加聚合函数add...函数簇
以sum函数为例
public void addSumAgg(String aggName, String fieldName) {
SumBuilder builder = AggregationBuilders.sum(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
a)初始化了一个SumBuilder聚合操作,然后作为termsBuilder的子聚合。
b)addSubAggList方法在subAggList属性(subAggList属性是一个List<Map<String, Object>>)上保存了所有添加了的子聚合的名字和builder。这样做是为了在解析结果的时候,知道是哪种type的聚合(instanceof),以便使用不同的逻辑去解析。
private void addSubAggList(String aggName, MetricsAggregationBuilder aggBuilder) {
Map<String, Object> subAgg = new HashMap<String, Object>();
subAgg.put("aggName", aggName);
subAgg.put("aggBuilder", aggBuilder);
subAggList.add(subAgg);
}
3)按类型获取结果
还是以sum函数为例
public boolean bucketSumAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof SumBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
a)这里先判断了aggBuilder是哪种类型的(instanceof),如果是SumBuilder类型的,就按照sum的结果类型去读取返回结果。
b)sum的返回结果就是一个值,当遇到percentiles这种类型的,返回结果不是一个值,此时为了简单,我将结果压缩成了jsonstring,也相当于一个值,可以自行参看代码。
c)后面依赖return true实现了一个逻辑,一旦命中了类型,就不再继续判断了,提升效率。
d)tmpMap是外部传入的一个全局接收器,用来存储结果。
4)解析所有的子聚合结果
public Map<String, Object> getGroupbyResponse() {
Map<String, Object> aggResponseMap = new TreeMap<String, Object>();
for (Terms.Bucket bucket : getTermsBucket()) {
String bucketKeyAsString = bucket.getKeyAsString();
Map<String, String> tmpMap = new TreeMap<String, String>();
for (Map<String, Object> subAgg : subAggList) {
String subAggName = subAgg.get("aggName").toString();
MetricsAggregationBuilder subAggBuilder = (MetricsAggregationBuilder) subAgg.get("aggBuilder");
if (bucketAvgAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketMaxAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketMinAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketSumAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketCountAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketCardinalityAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketPercentileRanksAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketPercentilesAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketExtendedStatsAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketStatsAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
}
aggResponseMap.put(bucketKeyAsString, tmpMap);
}
return aggResponseMap;
}
这里是解析结果的代码。tmpMap定义为全局接收器。
a)通过遍历subAggList存储的所有子聚合函数,获取所有的子聚合结果,并保存成两级TreeMap。
b)对每个迭代,调用所有的bucket...函数簇,这里通过if判断是否命中类型,如果命中了,就通过continue不再继续检查。
c) aggResponseMap使用treeMap是为了保持bucket的有序。
3、十种聚合函数
最后列出我们实现的十种聚合函数,你可以根据自己的需求继续添加。
1)返回单个值:sum、avg、min、max、count、cardinality(有误差)
2)percentiles:分位数查询,传入分位数,获取分位数上的值;percentileRanks,分位数排名查询,传入值,返回对应的分位数;互为逆向操作。
3)stats和extendedStats,extended聚合更详细的信息max、min、avg、sum、平方和、标准差等。
Elasticsearch JAVA api搞定groupBy聚合的更多相关文章
- Elasticsearch JAVA api轻松搞定groupBy聚合
本文给出如何使用Elasticsearch的Java API做类似SQL的group by聚合. 为了简单起见,只给出一级groupby即group by field1(而不涉及到多级,例如group ...
- 第08章 ElasticSearch Java API
本章内容 使用客户端对象(client object)连接到本地或远程ElasticSearch集群. 逐条或批量索引文档. 更新文档内容. 使用各种ElasticSearch支持的查询方式. 处理E ...
- Elasticsearch Java API 很全的整理
Elasticsearch 的API 分为 REST Client API(http请求形式)以及 transportClient API两种.相比来说transportClient API效率更高, ...
- [搜索]ElasticSearch Java Api(一) -添加数据创建索引
转载:http://blog.csdn.net/napoay/article/details/51707023 ElasticSearch JAVA API官网文档:https://www.elast ...
- Elasticsearch java api 基本搜索部分详解
文档是结合几个博客整理出来的,内容大部分为转载内容.在使用过程中,对一些疑问点进行了整理与解析. Elasticsearch java api 基本搜索部分详解 ElasticSearch 常用的查询 ...
- Elasticsearch java api 常用查询方法QueryBuilder构造举例
转载:http://m.blog.csdn.net/u012546526/article/details/74184769 Elasticsearch java api 常用查询方法QueryBuil ...
- 零java基础搞定微信Server
自从打通了微信client到BLE设备端的通道.我的工作就转移到了server端了.微信的BlueDemoServer是以java编写,而本尊仅仅懂得嵌入式,对JavaWeb一窍不通. 本尊贵为IOT ...
- Elasticsearch Java API深入详解
0.题记 之前Elasticsearch的应用比较多,但大多集中在关系型.非关系型数据库与Elasticsearch之间的同步.以上内容完成了Elasticsearch所需要的基础数据量的供给.但想要 ...
- 【API进阶之路】逆袭!用关键词抽取API搞定用户需求洞察
摘要: 老大说,我这份用关键词抽取API搞定的用户需求洞察报告,简直比比市场调研的科班人士做得还好. 最近这半个月的午饭,那可是相当不错,市场老大天天请吃饭,不是外面下馆子,就是从家带饺子.说是感谢我 ...
随机推荐
- 直方图均衡化C++实现
直方图均衡化在图像增强方面有着很重要的应用.一些拍摄得到的图片,我们从其直方图可以看出,它的分布是集中于某些灰度区间,这导致人在视觉上感觉这张图的对比度不高.所以,对于这类图像,我们可以通过直方图均衡 ...
- web实现数据交互的几种常见方式
前言 在当今社会,作为一名前端程序猿,并不是一昧的去制作静态页面就可以满足滴:你说你会制作网页,好吧,只能说你算是一个前端程序猿.但这是你作为一个程序猿最基本的能力,并不会为你进行加分: 我们都明白, ...
- 颜色框架Hue相关使用方法
Hue地址 cocoapods安装Hue pod "Hue" 导入框架 import Hue 将十六进制数字变成对应的颜色值 let color = UIColor.init(he ...
- SSH框架的多表查询和增删查改 (方法一)中
原创作品,允许转载,转载时请务必标明作者信息和声明本文章==>http://www.cnblogs.com/zhu520/p/7774144.html 这边文章是接的刚刚前一遍的基础上敲的 ...
- 【译】Asp.Net Identity Cookies 格式化-中英对照版
原文出处 Trailmax Tech Max Vasilyev: ASP.Net MVC development in Aberdeen, Scotland I've been reached out ...
- Lucene全文检索学习笔记
全文索引 介绍Lucene的作者:Lucene的贡献者Doug Cutting是 一位资深全文索引/检索专家,曾经是V-Twin搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后 ...
- 《天书夜读:从汇编语言到windows内核编程》三 练习反汇编C语言程序
1) Debug版本算法反汇编,现有如下3×3矩阵相乘的程序: #define SIZE 3 int MyFunction(int a[SIZE][SIZE],int b[SIZE][SIZE],in ...
- linux操作系统基础篇(一)
1.什么是linux? Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户.多任务.支持多线程和多CPU的操作系统.它能运行主要的UNIX工具软件.应用程序 ...
- File I/O
File I/O Introduction We'll start our discussion of the UNIX System by describing the functions ...
- RabbitMQ和SpringBoot的简单整合列子
一 思路总结 1 主要用spring-boot-starter-amqp来整合RabbitMQ和SpringBoot 2 使用spring-boot-starter-test来进行单元测试 3编写配置 ...