MLR算法[Paper笔记]
介绍
MLR算法是alibaba在2012年提出并使用的广告点击率预估模型,2017年发表出来。
如下图,LR不能拟合非线性数据,MLR可以拟合非线性数据,因为划分-训练模式。
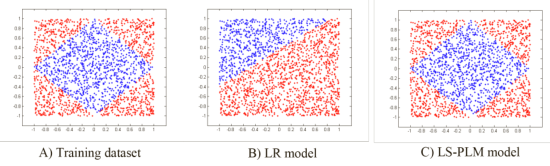
讨论,非线性拟合能力:
数据划分规则如下公式,特征分片数m=1时,退化为LR;上图MLR中m=4。m越大,模型的拟合能力越强,一般m=12。

基础知识
优化方法:
1)剃度下降:
大小:一阶导数,方向:导数负方向。由目标函数的泰勒一阶展开式求得
2)牛顿法:
大小:一阶导数,方向:-海信矩阵的逆。由目标函数的泰勒二阶展开式求
3)拟牛顿法(LBFGS):牛顿方向通过约等替换,每个样本保存下面三个参数:delta x ,delta剃度 和p:
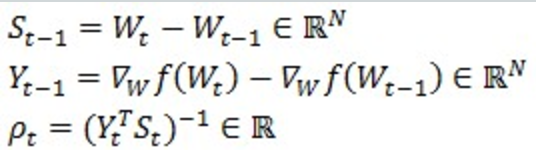
增量替换,计算牛顿方向D

LBFGS方法通过一阶导数中值定理,避免了计算海信矩阵(复杂度太大)。但是L1范数不能求导,所以需要OWLQN方法。
4)OWLQN:
(1)次梯度定义如下,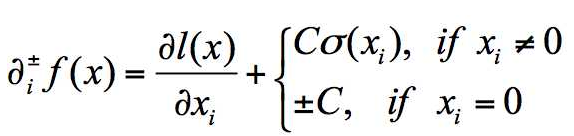
(2)不可导点取左or右次梯度,如下 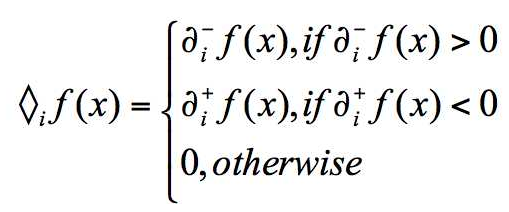
直观解释,当你打算用左偏导时,说明是在负象限,因此要加上一个负值,使得更新之后参数更往负象限前进,这样就避免了跨象限;当打算用右偏导数时,说明在正象限,一次要加上一个正值,使得更新之后参数更往正象限前进,从而避免跨象限;否则,只能直接设置subgradient为0。
(3)象限搜索line search: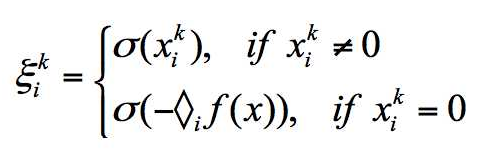
x不在0点时,line search在x_i所在象限搜索;如果模型参数在0点,就要在(2)次梯度约束的象限内进行line search.
MLR算法

算法公式如下:
0计算边界下降方向d:
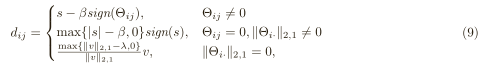
1计算梯度大小:theta在0处不可导,取sign符号函数dij。

2计算最终下降方向p:
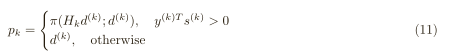
3象限内梯度下降,同OWLQN,line search:

paper介绍,MLR与LBFGS有三点不同:
1)OWLQN需要计算次梯度,MLR需要计算方向导数;
2)计算最终下降方向p时,MLR也要进行象限约束;
3)象限搜索line search,与OWLQN相似。
分布式框架实现
分布式
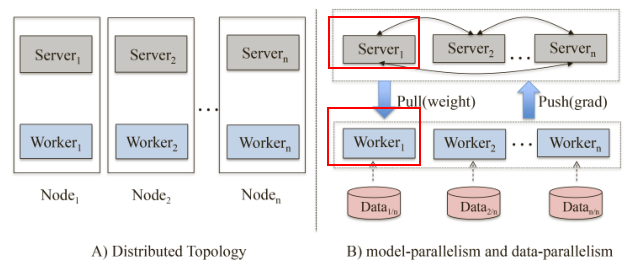
User特征共享
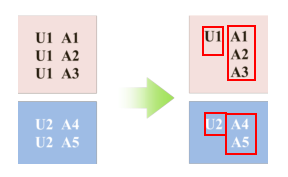
个人理解是为了加快运算速度,具体特征划分如下所示。其中,c是用户特征,nc是非用户特征。

实验结果
实验截图略,具体图表可以查看参考paper
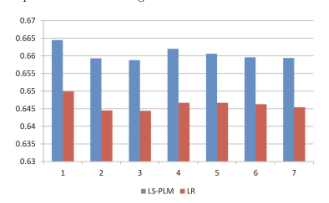
纵坐标是内存使用率,特征共享技巧使速度提高了三倍。
参考paper:Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction
MLR算法[Paper笔记]的更多相关文章
- 读paper笔记[Learning to rank]
读paper笔记[Learning to rank] by Jiawang 选读paper: [1] Ranking by calibrated AdaBoost, R. Busa-Fekete, B ...
- C / C++算法学习笔记(8)-SHELL排序
原始地址:C / C++算法学习笔记(8)-SHELL排序 基本思想 先取一个小于n的整数d1作为第一个增量(gap),把文件的全部记录分成d1个组.所有距离为dl的倍数的记录放在同一个组中.先在各组 ...
- Manacher算法学习笔记 | LeetCode#5
Manacher算法学习笔记 DECLARATION 引用来源:https://www.cnblogs.com/grandyang/p/4475985.html CONTENT 用途:寻找一个字符串的 ...
- 《Algorithms算法》笔记:元素排序(4)——凸包问题
<Algorithms算法>笔记:元素排序(4)——凸包问题 Algorithms算法笔记元素排序4凸包问题 凸包问题 凸包问题的应用 凸包的几何性质 Graham 扫描算法 代码 凸包问 ...
- 《Algorithms算法》笔记:元素排序(3)——洗牌算法
<Algorithms算法>笔记:元素排序(3)——洗牌算法 Algorithms算法笔记元素排序3洗牌算法 洗牌算法 排序洗牌 Knuth洗牌 Knuth洗牌代码 洗牌算法 洗牌的思想很 ...
- 《Algorithm算法》笔记:元素排序(2)——希尔排序
<Algorithm算法>笔记:元素排序(2)——希尔排序 Algorithm算法笔记元素排序2希尔排序 希尔排序思想 为什么是插入排序 h的确定方法 希尔排序的特点 代码 有关排序的介绍 ...
- MIT算法导论笔记
详细MIT算法导论笔记 (网络链接) 第一讲:课程简介及算法分析 (Sheridan) 第二讲:渐近符号.递归及解法 (Sheridan) 第三讲:分治法(1)(Sheridan) 第四讲:快排及随 ...
- Johnson算法学习笔记
\(Johnson\)算法学习笔记. 在最短路的学习中,我们曾学习了三种最短路的算法,\(Bellman-Ford\)算法及其队列优化\(SPFA\)算法,\(Dijkstra\)算法.这些算法可以快 ...
- 某科学的PID算法学习笔记
最近,在某社团的要求下,自学了PID算法.学完后,深切地感受到PID算法之强大.PID算法应用广泛,比如加热器.平衡车.无人机等等,是自动控制理论中比较容易理解但十分重要的算法. 下面是博主学习过程中 ...
随机推荐
- PHP的取整函数
PHP的取整函数有四个,分别是ceil.floor.round和intval,下面对它们进行一一介绍: 1. ceil(x):向上舍入为最接近的整数. 返回不小于 x 的下一个整数,x 如果有小数部分 ...
- Hbuilder中添加Babel自动编译
Hbuilder是一个不错的H5开发IDE. Babel是EMCAScript最新标准的编译器,很多ES的最新特性都可以在Babel中尝试. 如果可以有办法在Hbuilder中直接使用ES6,并通过B ...
- 一起来学linux:NFS服务器搭建
p { margin-bottom: 0.25cm; line-height: 120% } a:link { } nfs是network file system的缩写,作用在于让不同的网络,不同的机 ...
- 关于EsayUI中datagrid重复提交后台查询数据的问题
直接上代码: <table id="XXXX" style="width:100%;height:100%;" class="easyui-da ...
- JS框架设计读书笔记之-异步
setTimeout/setInterval 1. 如果回调执行时间大于间隔时间,真正的间隔时间会大一些. 2. 存在一个最小的时间间隔,即使seTimeout(fn,0),在IE6-IE8中大概为1 ...
- poj2635The Embarrassed Cryptographer(同余膜定理)
The Embarrassed Cryptographer Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 15069 A ...
- hive的简单理解--笔记
Hive的理解 数据仓库的工具 Hive仅仅是在hadoop上面包装了SQL: Hive的数据存储在hadoop上 Hive的计算由MR进行 Hive批量处理数据 Hive的特点 1 可扩展性(h ...
- CSS浮动(Float)
定义 浮动会使元素向左或向右移动,其周围的元素也会重新排列: 浮动直到它的外边缘碰到包含框或者另一个浮动框才停止: 浮动之后的元素将围绕它,浮动之前的元素不变: 由于浮动框不在文档的普通流中,所以文档 ...
- 线程UI同步
只用一次: this.Invoke(new MethodInvoker(() => { this.btnGo.Enabled = true; MessageBox.Show("Yeah ...
- C#保留小数位数的方法
1.System.Globalization.NumberFormatInfo provider = new System.Globalization.NumberFormatInfo();provi ...