推荐系统 LFM 算法的简单理解,感觉比大部分网上抄来抄去的文章好理解
本文主要是基于《推荐系统实践》这本书的读书笔记,还没有实践这些算法。
LFM算法是属于隐含语义模型的算法,不同于基于邻域的推荐算法。
隐含语义模型有:LFM,LDA,Topic Model
这本书里介绍的LFM算法。书中内容介绍的很详细,不过我也是看了一天才看明白的。
开始一直没想明白,隐类的类别是咋来的,后来仔细读才发现是一个设置的参数。
下面开始进入正文:
对于基于邻域的机器学习算法来说,如果要给一个用户推荐商品,那么有两种方式。
一种是基于物品的,另一种是基于用户的。
基于物品的是,从该用户之前的购买商品中,推荐给他相似的商品。
基于用户的是,找出于该用户相似的用户,然后推荐给他相似用户购买的商品。
但是,推荐系统除了这两种之外,还有其他的方式。例如如果知道该用户的兴趣分类,可以给他推荐该类别的商品。
为了实现这一功能,我们需要根据用户的行为数据得到用户对于不同分类的兴趣,以及不同商品的类别归属。
先说类别归属:
对于一本书来说,获取书的类别可以通过它在货架上的类别,比如该一本书被归类为计算机,或者数学。但是一本书也可能属于多个类别,
比如《史记》可以归为历史,也可以归为古典文学。至于《史记》属于哪一类别多,应当根据用户行为来判定更加合理。
也就是说大部分用户读《史记》,是把它作为史料来读,还是古典文学来读。(反正我也不看,觉得没区别)。
一言以蔽之,根据用户行为来划分每件商品的归属类别。该方式还有一个好处是,一个商品可以分别属于不同类别,只是在各个类别中的权重不一样。
再说用户对于各个类别的喜爱程度:
用户对于不同的类别的喜好程度也不同,该算法可以根据用户的行为数据推测出用户对不同的类别的喜好。
下面开始介绍算法的内容:
首先是数据的处理,由于使用的是隐性数据集,只有正样本,例如用户点击了某件商品,没有负样本。
数据处理主要是选出数据集的负样本。
负样本的选取策略主要有以下要点:
(1)正负样本要均衡,基本保证正负样本的比例1:1
(2)负样本需要选择用户没有行为的热门商品。
选取完成之后,计算用户对于某件商品的喜爱程度,例如喜欢是1,不喜欢是0
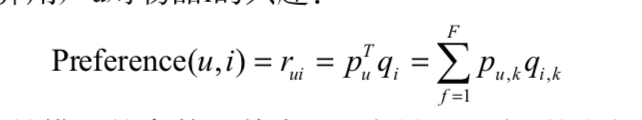
用户u对于商品i的喜爱程度等于,用户u对于类别k的喜爱程度 乘以 商品i在类别k的比重
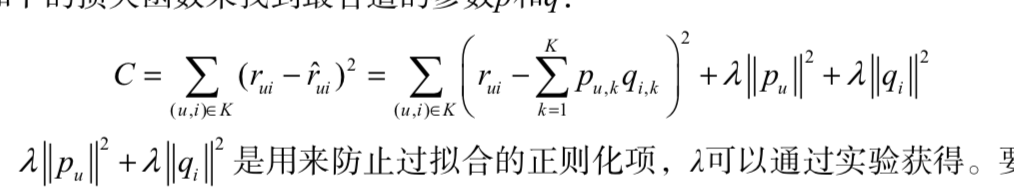
这是代价函数。
然后根据用户行为数据使用随机提督下降法训练。
该模型的参数有:

推荐系统 LFM 算法的简单理解,感觉比大部分网上抄来抄去的文章好理解的更多相关文章
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
- 使用C语言实现二维,三维绘图算法(3)-简单的二维分形
使用C语言实现二维,三维绘图算法(3)-简单的二维分形 ---- 引言---- 每次使用OpenGL或DirectX写三维程序的时候, 都有一种隔靴搔痒的感觉, 对于内部的三维算法的实现不甚了解. 其 ...
- 1101: 零起点学算法08——简单的输入和计算(a+b)
1101: 零起点学算法08--简单的输入和计算(a+b) Time Limit: 1 Sec Memory Limit: 128 MB 64bit IO Format: %lldSubmitt ...
- java程序员到底该不该了解一点算法(一个简单的递归计算斐波那契数列的案例说明算法对程序的重要性)
为什么说 “算法是程序的灵魂这句话一点也不为过”,递归计算斐波那契数列的第50项是多少? 方案一:只是单纯的使用递归,递归的那个方法被执行了250多亿次,耗时1分钟还要多. 方案二:用一个map去存储 ...
- C语言排序算法之简单交换法排序,直接选择排序,冒泡排序
C语言排序算法之简单交换法排序,直接选择排序,冒泡排序,最近考试要用到,网上也有很多例子,我觉得还是自己写的看得懂一些. 简单交换法排序 /*简单交换法排序 根据序列中两个记录键值的比较结果来对换这两 ...
- 冒泡排序算法和简单选择排序算法的js实现
之前已经介绍过冒泡排序算法和简单选择排序算法和原理,现在有Js实现. 冒泡排序算法 let dat=[5, 8, 10, 3, 2, 18, 17, 9]; function bubbleSort(d ...
- 个性化召回算法实践(二)——LFM算法
LFM算法核心思想是通过隐含特征(latent factor)联系用户兴趣和物品,找出潜在的主题和分类.LFM(latent factor model)通过如下公式计算用户u对物品i的兴趣: \[ P ...
- C#冒泡排序算法(简单好理解)
我对冒泡排序算法的理解: 把最大的往后,从最后一个与前一个对比,然后互换位置,直到全部换好. 目标:从小到大排序 源代码如下: namespace net冒泡排序{ class Program { s ...
随机推荐
- 为并发而生的 ConcurrentHashMap(Java 8)
HashMap 是我们日常最常见的一种容器,它以键值对的形式完成对数据的存储,但众所周知,它在高并发的情境下是不安全的.尤其是在 jdk 1.8 之前,rehash 的过程中采用头插法转移结点,高并发 ...
- 基于UDP协议的socket编程
UDP协议特点: 1.无连接.服务端与客户端传输数据之前不需要进行连接,且没有超时重发等机制,只是把数据通过网络发送出去.也正是因为此特点,所以基于UDP协议的socket的客户端在启动之前不需要先启 ...
- python-02 数据类型、字符编码、文件处理
标准数据类型 Python3 中有六个标准的数据类型: Number(数字) String(字符串) List(列表) Tuple(元组) Sets(集合) Dictionary(字典) 数字 #整型 ...
- CSS的常见问题
1.css的编码风格 多行式:可读性越强,但是CSS文件的行数过多,影响开发速度,增大CSS文件的大小 一行式:可读性稍差,有效减少CSS文件的行数,有利于提高开发速度,减小CSS文件的大小 2.id ...
- 分布式服务Dubbo+Zookeeper安全认证
前言 由于之前的服务都是在内网,Zookeeper集群配置都是走的内网IP,外网不开放相关端口.最近由于业务升级,购置了阿里云的服务,需要对外开放Zookeeper服务. 问题 Zookeeper+d ...
- Linux 进程间通信(包含一个经典的生产者消费者实例代码)
前言:编写多进程程序时,有时不可避免的需要在多个进程之间传递数据,我们知道,进程的用户的地址空间是独立,父进程中对数据的修改并不会反映到子进程中,但内核是共享的,大多数进程间通信方式都是在内核中建立一 ...
- 深入浅出了解frame和bounds
frame frame的官方解释如下: The frame rectangle, which describes the view's location and size in its supervi ...
- 机器学习笔记1 - Hello World In Machine Learning
前言 Alpha Go在16年以4:1的战绩打败了李世石,17年又以3:0的战绩战胜了中国围棋天才柯洁,这真是科技界振奋人心的进步.伴随着媒体的大量宣传,此事变成了妇孺皆知的大事件.大家又开始激烈的讨 ...
- Python - 首字母大写(capwords) 和 创建转换表(maketrans) 具体解释
首字母大写(capwords) 和 创建转换表(maketrans) 具体解释 本文地址: http://blog.csdn.net/caroline_wendy/article/details/27 ...
- day01_使用Android Studio创建第一个Android项目
使用Android Studio开发Android项目如此简单 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize ...