推荐系统 LFM 算法的简单理解,感觉比大部分网上抄来抄去的文章好理解
本文主要是基于《推荐系统实践》这本书的读书笔记,还没有实践这些算法。
LFM算法是属于隐含语义模型的算法,不同于基于邻域的推荐算法。
隐含语义模型有:LFM,LDA,Topic Model
这本书里介绍的LFM算法。书中内容介绍的很详细,不过我也是看了一天才看明白的。
开始一直没想明白,隐类的类别是咋来的,后来仔细读才发现是一个设置的参数。
下面开始进入正文:
对于基于邻域的机器学习算法来说,如果要给一个用户推荐商品,那么有两种方式。
一种是基于物品的,另一种是基于用户的。
基于物品的是,从该用户之前的购买商品中,推荐给他相似的商品。
基于用户的是,找出于该用户相似的用户,然后推荐给他相似用户购买的商品。
但是,推荐系统除了这两种之外,还有其他的方式。例如如果知道该用户的兴趣分类,可以给他推荐该类别的商品。
为了实现这一功能,我们需要根据用户的行为数据得到用户对于不同分类的兴趣,以及不同商品的类别归属。
先说类别归属:
对于一本书来说,获取书的类别可以通过它在货架上的类别,比如该一本书被归类为计算机,或者数学。但是一本书也可能属于多个类别,
比如《史记》可以归为历史,也可以归为古典文学。至于《史记》属于哪一类别多,应当根据用户行为来判定更加合理。
也就是说大部分用户读《史记》,是把它作为史料来读,还是古典文学来读。(反正我也不看,觉得没区别)。
一言以蔽之,根据用户行为来划分每件商品的归属类别。该方式还有一个好处是,一个商品可以分别属于不同类别,只是在各个类别中的权重不一样。
再说用户对于各个类别的喜爱程度:
用户对于不同的类别的喜好程度也不同,该算法可以根据用户的行为数据推测出用户对不同的类别的喜好。
下面开始介绍算法的内容:
首先是数据的处理,由于使用的是隐性数据集,只有正样本,例如用户点击了某件商品,没有负样本。
数据处理主要是选出数据集的负样本。
负样本的选取策略主要有以下要点:
(1)正负样本要均衡,基本保证正负样本的比例1:1
(2)负样本需要选择用户没有行为的热门商品。
选取完成之后,计算用户对于某件商品的喜爱程度,例如喜欢是1,不喜欢是0
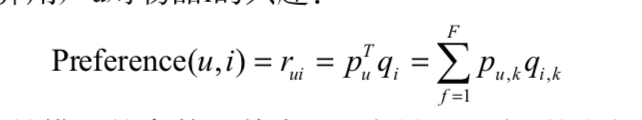
用户u对于商品i的喜爱程度等于,用户u对于类别k的喜爱程度 乘以 商品i在类别k的比重
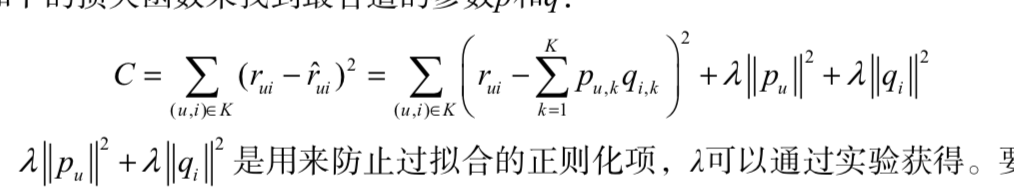
这是代价函数。
然后根据用户行为数据使用随机提督下降法训练。
该模型的参数有:

推荐系统 LFM 算法的简单理解,感觉比大部分网上抄来抄去的文章好理解的更多相关文章
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
- 使用C语言实现二维,三维绘图算法(3)-简单的二维分形
使用C语言实现二维,三维绘图算法(3)-简单的二维分形 ---- 引言---- 每次使用OpenGL或DirectX写三维程序的时候, 都有一种隔靴搔痒的感觉, 对于内部的三维算法的实现不甚了解. 其 ...
- 1101: 零起点学算法08——简单的输入和计算(a+b)
1101: 零起点学算法08--简单的输入和计算(a+b) Time Limit: 1 Sec Memory Limit: 128 MB 64bit IO Format: %lldSubmitt ...
- java程序员到底该不该了解一点算法(一个简单的递归计算斐波那契数列的案例说明算法对程序的重要性)
为什么说 “算法是程序的灵魂这句话一点也不为过”,递归计算斐波那契数列的第50项是多少? 方案一:只是单纯的使用递归,递归的那个方法被执行了250多亿次,耗时1分钟还要多. 方案二:用一个map去存储 ...
- C语言排序算法之简单交换法排序,直接选择排序,冒泡排序
C语言排序算法之简单交换法排序,直接选择排序,冒泡排序,最近考试要用到,网上也有很多例子,我觉得还是自己写的看得懂一些. 简单交换法排序 /*简单交换法排序 根据序列中两个记录键值的比较结果来对换这两 ...
- 冒泡排序算法和简单选择排序算法的js实现
之前已经介绍过冒泡排序算法和简单选择排序算法和原理,现在有Js实现. 冒泡排序算法 let dat=[5, 8, 10, 3, 2, 18, 17, 9]; function bubbleSort(d ...
- 个性化召回算法实践(二)——LFM算法
LFM算法核心思想是通过隐含特征(latent factor)联系用户兴趣和物品,找出潜在的主题和分类.LFM(latent factor model)通过如下公式计算用户u对物品i的兴趣: \[ P ...
- C#冒泡排序算法(简单好理解)
我对冒泡排序算法的理解: 把最大的往后,从最后一个与前一个对比,然后互换位置,直到全部换好. 目标:从小到大排序 源代码如下: namespace net冒泡排序{ class Program { s ...
随机推荐
- POST和GET有什么区别?
1. GET主要用于从服务器查询数据,POST用于向服务器提交数据 2. GET通过URL传递数据,POST通过http请求体传递数据 3. GET传输数据量有限制,不能大于2kb,POST传递的数据 ...
- Dynamics CRM可以设置会话超时和非活动超时吗?
本人微信和易信公众号: 微软动态CRM专家罗勇 ,回复266或者20171213可方便获取本文,同时可以在第一间得到我发布的最新的博文信息,follow me!我的网站是 www.luoyong.me ...
- 利用纯CSS美化checkbox和radio和滑动按钮的实现
W3C提供的CheckBox和radio的原始样式非常的丑,而且在不同的额浏览器表现还不一样,使用常规的方法添加样式没法进行修改样式 一, 单选按钮 <html> <head> ...
- 阿里安全潘多拉实验室首先完美越狱苹果iOS 11.2
苹果官方对iOS 11的评价是"为iPhone带来巨大进步,让iPad实现里程碑式飞跃."但为了不断修复Bug,苹果于12月2日推出最新的iOS 11.2,修复了Google安全人 ...
- Ali RocketMQ与Kafka对照
淘宝内部的交易系统使用了淘宝自主研发的Notify消息中间件,使用Mysql作为消息存储媒介.可全然水平扩容,为了进一步减少成本.我们觉得存储部分能够进一步优化,2011年初,Linkin开源了Kaf ...
- 错误代码: 1054 Unknown column 't.createUsrId' in 'group statement'
1.错误描写叙述 1 queries executed, 0 success, 1 errors, 0 warnings 查询:select count(t.id),t.`createUserId` ...
- 联通假4G欺骗消费者!
之前预约了联通4G升级,官网说从4月18日開始到5月1月生效.4月18日到5月1日之间10010会联系预约用户更改套餐.24号收到联通业务员打来电话,明白告知:联通4G仅仅是套餐是4G的.网络还是3G ...
- kotlin web开发教程【一】从零搭建kotlin与spring boot开发环境
IDEA中文输入法的智能提示框不会跟随光标的问题 我用的开发工具是IDEA 这个版本的IDEA有一个问题: 就是中文输入法的智能提示框不会跟随光标 解决这个问题的办法很简单,只有在安装目录下把JRE文 ...
- xml基本语法(2)
本节要点: 了解XML的文档声明 了解XML的元素.命名规则.属性.元素内容.处理指令等概念 1 XML文档声明 表示该文档是一个XML文档,以及遵循哪个XML版本的规范. 规范:<?xml 版 ...
- 【转】Win10下 python3和python2同时安装并解决pip共存问题
1.下载python3和python2 进入python官网,链接https://www.python.org/ 选择Downloads--->Windows,点击进入就可以看到寻找想要的pyt ...