Hadoop(22)-Hadoop数据压缩
1.压缩概述

2.压缩策略和原则

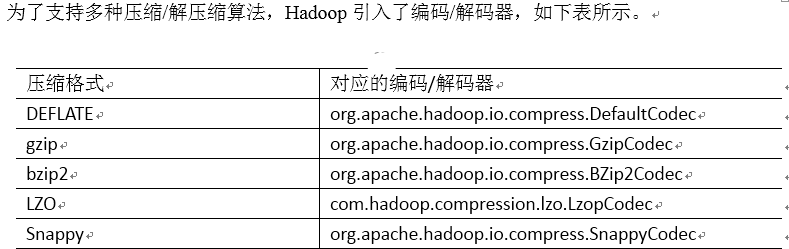
3.MapReduce支持的压缩编码
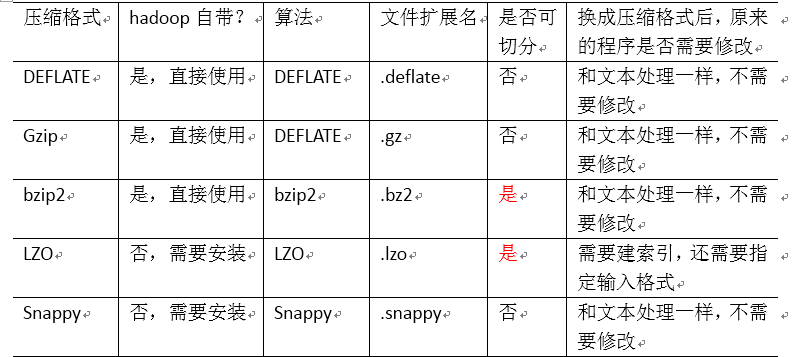

64位系统下的单核i7,Snappy的压缩速率可以达到至少250MB/S,解压缩速率可以达到至少500MB/S
4.压缩方式选择
1) Gzip

2) Bzip2

3) Lzo

4) Snappy

4. 压缩位置选择
压缩可以在MapReduce作用的任意阶段启用

5. 压缩参数配置
|
参数 |
默认值 |
阶段 |
建议 |
|
io.compression.codecs (在core-site.xml中配置) |
org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec |
输入压缩 |
Hadoop使用文件扩展名判断是否支持某种编解码器 |
|
mapreduce.map.output.compress(在mapred-site.xml中配置) |
false |
mapper输出 |
这个参数设为true启用压缩 |
|
mapreduce.map.output.compress.codec(在mapred-site.xml中配置) |
org.apache.hadoop.io.compress.DefaultCodec |
mapper输出 |
企业多使用LZO或Snappy编解码器在此阶段压缩数据 |
|
mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) |
false |
reducer输出 |
这个参数设为true启用压缩 |
|
mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置) |
org.apache.hadoop.io.compress. DefaultCodec |
reducer输出 |
使用标准工具或者编解码器,如gzip和bzip2 |
|
mapreduce.output.fileoutputformat.compress.type(在mapred-site.xml中配置) |
RECORD |
reducer输出 |
SequenceFile输出使用的压缩类型:NONE和BLOCK |
Hadoop(22)-Hadoop数据压缩的更多相关文章
- [Linux][Hadoop] 将hadoop跑起来
前面安装过程待补充,安装完成hadoop安装之后,开始执行相关命令,让hadoop跑起来 使用命令启动所有服务: hadoop@ubuntu:/usr/local/gz/hadoop-$ ./sb ...
- Hadoop:搭建hadoop集群
操作系统环境准备: 准备几台服务器(我这里是三台虚拟机): linux ubuntu 14.04 server x64(下载地址:http://releases.ubuntu.com/14.04.2/ ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
- 【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型
忘的差不多了, 先补概念, 然后开始搭建集群实战 ... . 一 Hadoop版本 和 生态圈 1. Hadoop版本 (1) Apache Hadoop版本介绍 Apache的开源项目开发流程 : ...
- hadoop之 hadoop日志存放路径
环境:[root@hadp-master hadoop-2.7.4]# hadoop versionHadoop 2.7.4 Hadoop的日志大致可以分为两类: (1).Hadoop系统服务输出的日 ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- 五十九.大数据、Hadoop 、 Hadoop安装与配置 、 HDFS
1.安装Hadoop 单机模式安装Hadoop 安装JAVA环境 设置环境变量,启动运行 1.1 环境准备 1)配置主机名为nn01,ip为192.168.1.21,配置yum源(系统源) 备 ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
随机推荐
- 夜色的 cocos2d-x 开发笔记 01
现在我们来实现在屏幕上出现一只飞机的效果. 首先我们要建立一个场景,显示在屏幕上,创建一个类,RunScence,现在你的项目目录应该是这个样子的. 之前没学过C++,.h文件我理解就是一个声明文件, ...
- IOS APP 瘦身
只保留其中一宗编译环境包 lipo -thin armv7 XXAPP -output XXAPP.armv7
- spring security基于数据库表进行认证
我们从研究org.springframework.security.core.userdetails.jdbc.JdbcDaoImpl.class的源码开始 public class JdbcDaoI ...
- Anaconda中spyder 安装tensorflow
关于Anaconda的安装就不介绍了,本文主要介绍spyder中安装 tensorflow.废话少说 直接重点: 1.安装好Anaconda之后,找到spyder图标 点击install,等待安装完成 ...
- oracle_set_autocommit
preface 1.centos operating system. 2.database is oracle 11g. 3.oracle account is scott. step 1.e ...
- python:包与异常处理
一.包 1,什么是包? 把解决一类问题的模块放在同一个文件夹里-----包 2,包是一种通过使用‘.模块名’来组织python模块名称空间的方式. 1. 无论是import形式还是from...imp ...
- BZOJ3262:陌上花开(CDQ分治)
Description 有n朵花,每朵花有三个属性:花形(s).颜色(c).气味(m),用三个整数表示. 现在要对每朵花评级,一朵花的级别是它拥有的美丽能超过的花的数量. 定义一朵花A比另一朵花B要美 ...
- ACM-ICPC 2018 徐州赛区网络预赛 G. Trace【树状数组维护区间最大值】
任意门:https://nanti.jisuanke.com/t/31459 There's a beach in the first quadrant. And from time to time, ...
- Linux 进程状态标识 Process State Definition
From : http://www.linfo.org/process_state.html 译者:李秋豪 进程状态标识是指在进程描述符中状态位的值. 进程,也可被称为任务,是指一个程序运行的实例. ...
- javascript之正则表达式基础知识小结
javascript之正则表达式基础知识小结,对于学习正则表达式的朋友是个不错的基础入门资料. 元字符 ^ $ . * + ? = ! : | \ / ( ) [ ] { } 在使用这些符号时需要 ...