Datenode无法启动
执行start-dfs.sh后,或者执行datenode没有启动。很大一部分原因是因为在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令
这时主节点namenode的clusterID会重新生成,而从节点datanode的clusterID 保持不变导致的。
解决方法:
1.查看路径:
配置hadoop-2.6.4的各项文件(注意:路径不同,命令也不一样)
cd
cd hadoop/hadoop-2.6.4
cd etc/hadoop
gedit hdfs-site.xml //修改代码
找到如下代码:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/tianjiale/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/tianjiale/hadoop/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<value> 里面的路径需要注意
2.查看namenode和datanode的clusterID是否相同。
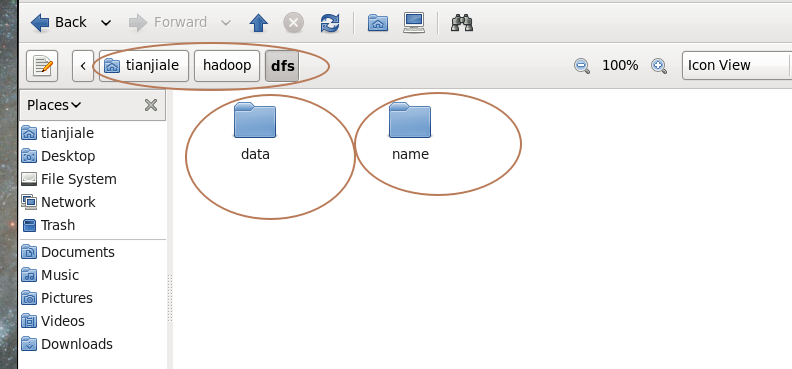
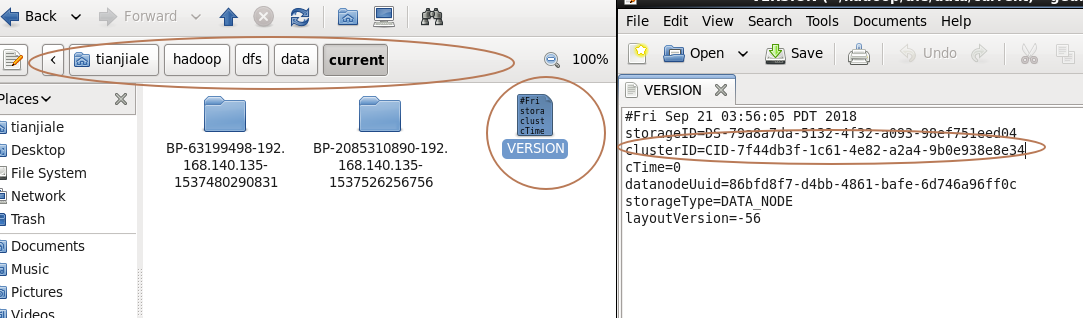

如果clusterID不相同,则将namenode的clusterID赋值给datanode的clusterID。
然后重新运行脚本start-dfs.sh.
最后jps查询看看。

Datenode无法启动的更多相关文章
- 执行start-dfs.sh后,datenode没有启动的解决办法
执行start-dfs.sh后,datenode没有启动,很大一部分原因是因为在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format) ...
- hadoop集群之Datenode无法启动解决办法
hadoop集群之Datenode无法启动解决办法 我们在启动hadoop集群的时候,通过jps查看进程,发现namenode RM和Secondary NameNode都有,但datanode没有启 ...
- 执行start-dfs.sh后,datenode没有启动
Hadoop2.2.0启动异常 – Incompatible clusterIDs 2014年08月29日 ⁄ 综合 ⁄ 共 2399字 ⁄ 字号 小 中 大 ⁄ 评论关闭 今天启动Hadoop2.2 ...
- 安装hadoop2.4.0遇到的问题
一.执行start-dfs.sh后,datenode没有启动 查看日志如下: 2014-06-18 20:34:59,622 FATAL org.apache.hadoop.hdfs.server.d ...
- Hadoop安装错误总结
Master的NodeManager/DateNode未启动 日志中未出现任何错误 正常现象,如需在Master中启动可在slave文件中 slaves localhost slave01 slave ...
- Hadoop、Spark 集群环境搭建问题汇总
Hadoop 问题1: Hadoop Slave节点 NodeManager 无法启动 解决方法: yarn-site.xml reducer取数据的方式是mapreduce_shuffle 问题2: ...
- Hadoop中的控制脚本
1.提出问题 在上篇博文中,提到了为什么要配置ssh免密码登录,说是Hadoop控制脚本依赖SSH来执行针对整个集群的操作,那么Hadoop中控制脚本都是什么东西呢?具体是如何通过SSH来针对整个集群 ...
- dateNode 启动不了
dateNode 启动不了 进去路径中找到 name和data文件夹,current下面分别有 一个 version文件,打开发现两个clusterId都不一样 把name和data文件里面的ver ...
- hadoop集群之HDFS和YARN启动和停止命令
假如我们只有3台linux虚拟机,主机名分别为hadoop01.hadoop02和hadoop03,在这3台机器上,hadoop集群的部署情况如下: hadoop01:1个namenode,1个dat ...
随机推荐
- 【luogu P1726 上白泽慧音】 题解
题目链接:https://www.luogu.org/problemnew/show/P1726 菜 #include <stack> #include <cstdio> #i ...
- scala性能测试
主要对比scala 的for, while循环,以及和java for while循环作对比 scala代码 object TestScalaClass { var maxindex = 100000 ...
- EF执行SQL语句
使用上下文中的Database.SqlQuery<对应的表名>(sql语句) var data = dbcenter.Database.SqlQuery<CcBusiFormview ...
- mui 的多图片上传
pickHead(){ var _this = this; plus.gallery.pick(function(path){ _this.headImage=path; var files = [{ ...
- Python使用dict和set
dict Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也成为map,使用键-值(key-value)存储,具有极快的查找速度. 假设要根据同学的名字查找对应的 ...
- mysql快速导入导出数据
--导入 select * from inhos_genoperation(表名) where UPLOAD_ORG_CODE='***' into outfile '/tmp/inhos_genop ...
- shardedJedisPool工具类
这里使用的是ShardedJedisPool,而不是RedisTemplate 1.配置文件 <?xml version="1.0" encoding="UTF-8 ...
- java 时间转换去杠
public static String minusHyphen(String dateParam){ if(dateParam ==null) return null; if(dateParam.i ...
- 【ospf-stub区域配置】
根据项目需求搭建好如下拓扑图 配置rt1的环回口地址及g0/0/0和g0/0/1的ip地址 配rt1的ospf 配置rt2的环回口地址和g0/0/0和g0/0/1 配置rt2的ospf 配置rt3的环 ...
- 华为机试 求int型数据在内存中存储时1的个数
题目描述 输入一个int型的正整数,计算出该int型数据在内存中存储时1的个数. 输入描述: 输入一个整数(int类型) 输出描述: 这个数转换成2进制后,输出1的个数 输入 5 输出 2 普通运算方 ...