scrapy的 安装 及 流程 转
安装
linux 和 mac 直接 pip install scrapy 就行
windows 安装步骤
a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl d. pip3 install scrapy e. 下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
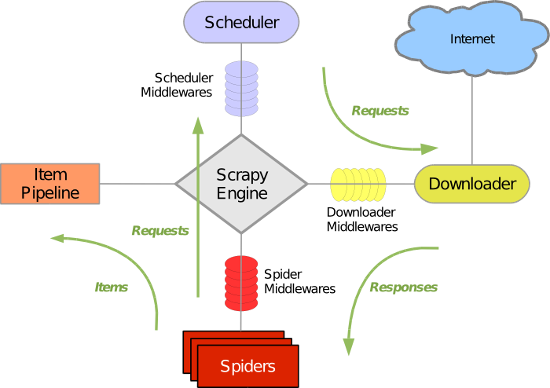
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
1. 基本命令
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
1. scrapy startproject 项目名称 - 在当前目录中创建中创建一个项目文件(类似于Django)2. scrapy genspider [-t template] <name> <domain> - 创建爬虫应用 如: scrapy gensipider -t basic oldboy oldboy.com scrapy gensipider -t xmlfeed autohome autohome.com.cn PS: 查看所有命令:scrapy gensipider -l 查看模板命令:scrapy gensipider -d 模板名称3. scrapy list - 展示爬虫应用列表4. scrapy crawl 爬虫应用名称 - 运行单独爬虫应用 |
scrapy的 安装 及 流程 转的更多相关文章
- Scrapy简单上手 —— 安装与流程
一.安装scrapy 由于scrapy依赖较多,建议使用虚拟环境 windows下pip安装(不推荐) 1.安装virtualenv pip install virtualenv 2.在你开始项目的文 ...
- Scrapy的安装和基本使用方法
Scrapy的安装 1. Windows下安装流程: 方法一: 命令行执行pip install scrapy 安装scrapy 注意:如果有anaconda,也可以打开“Anaconda promp ...
- scrapy windows 安装
windows 7 系统下参照官网安装总是会提示出错,现在整理一下安装的流程 1.安装 python 2.7,添加环境变量 C:\Python27\;C:\Python27\Scripts\; 在 C ...
- 4.1. Scrapy配置安装
Scrapy的安装介绍 Scrapy框架官方网址:http://doc.scrapy.org/en/latest Scrapy中文维护站点:http://scrapy-chs.readthedocs. ...
- Scrapy框架安装与使用(基于windows系统)
"人生苦短,我用python".最近了解到一个很好的Spider框架--Scrapy,自己就按着官方文档装了一下,出了些问题,在这里记录一下,免得忘记. Scrapy的安装是基于T ...
- Python 爬虫6——Scrapy的安装和使用
前面我们简述了使用Python自带的urllib和urllib2库完成的一下爬取网页数据的操作,但其实能完成的功能都很简单,假如要进行复制的数据匹配和高效的操作,可以引入第三方的框架,例如Scrapy ...
- 在Centos上安装RabbitMQ流程(转)
在Centos上安装RabbitMQ流程------------------------ 1. 需求 由于项目中要用到消息队列,经过ActiveMQ与RabbitMQ的比较,最终选择了RabbbitM ...
- OpenStack Keystone安装部署流程
之前介绍了OpenStack Swift的安装部署,采用的都是tempauth认证模式,今天就来介绍一个新的组件,名为Keystone. 1. 简介 本文将详细描述Keystone的安装部署流程,并给 ...
- 利用cocoapods管理开源项目,支持 pod install安装整个流程记录(github公有库)
利用cocoapods管理开源项目,支持 pod install安装整个流程记录(github公有库),完成预期的任务,大致有下面几步: 1.代码提交到github平台 2.创建.podspec 3. ...
随机推荐
- interface vs abstract
[interface vs abstract] 1.interface中的方法不能用public.abstract修饰,interface中的方法只包括signature. 2.一个类只能继承一个ab ...
- 用户“*****”不具有所需的权限。请验证授予了足够的权限并且解决了 Windows 用户帐户控制(UAC)限制问题。
错误: 用户“ts\***”不具有所需的权限.请验证授予了足够的权限并且解决了 Windows 用户帐户控制(UAC)限制问题. 解决: 当从客户端用IE连接http://xxx.xxx.xxx.xx ...
- Python04 range()方法的使用、turtle.textinput()方法和write()的使用、turtle.numinput()的使用
1 range() 方法的使用 1.1 range方法介绍 range方法会返回一个range类型的对象,该对象会根据range方法的参数产生一些列整型数据 技巧01:range方法有三个参数,第一个 ...
- 605. Can Place Flowers零一间隔种花
[抄题]: Suppose you have a long flowerbed in which some of the plots are planted and some are not. How ...
- Docker学习笔记_安装和使用Apache
一.准备 1.宿主机OS:Win10 64位 2.虚拟机OS:Ubuntu18.04 3.账号:docker 二.安装 1.搜索镜像 ...
- CentOS集群自动同步时间的一种方法
CentOS集群自动同步时间的一种方法 之前有篇日志是手动同步时间的 http://www.ahlinux.com/os/201304/202456.html 之所以这么干,是因为我们实验室的局域网只 ...
- c语言学习笔记 switch case语句为什么要加break
先来看一个没有break的例子: int main() { int a = 1; switch (a) { case 1: printf("1"); case 2: printf( ...
- 数字图像处理实验(15):PROJECT 06-02,Pseudo-Color Image Processing 标签: 图像处理MATLAB 2017-05-27 20:53
实验要求: 上面的实验要求中Objective(实验目的)部分是错误的. 然而在我拿到的大纲中就是这么写的,所以请忽视那部分,其余部分是没有问题的. 本实验是使用伪彩色强调突出我们感兴趣的灰度范围,在 ...
- 36.LEN() 函数
LEN() 函数 LEN 函数返回文本字段中值的长度. SQL LEN() 语法 SELECT LEN(column_name) FROM table_name SQL LEN() 实例 我们拥有下面 ...
- Visual Studio 2010调试本地 IIS 站点
点击vs的Debug-Attach to Process选中 w3wp.exe,然后点击Attach, vs便进入debug模式.