【Python】【Pandas】使用concat添加行
添加行
t = pd.DataFrame(columns=["姓名","平均分"])
t = t.append({"姓名":"小红","平均分":M1},ignore_index=True)
t = t.append({"姓名":"张明","平均分":M2},ignore_index=True)
t = t.append({"姓名":"小江","平均分":M3},ignore_index=True)
t = t.append({"姓名":"小李","平均分":M4},ignore_index=True)
print(t)
使用append的时候发出警告如下:
FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
于是我就按它提示的来。
concat是将两个DataFrame拼接起来
td = pd.DataFrame([
{"姓名":"小红","平均分":"%.2f"%M1},
{"姓名":"张明","平均分":"%.2f"%M2},
{"姓名":"小江","平均分":"%.2f"%M3},
{"姓名":"小李","平均分":"%.2f"%M4}],
index=["M1","M2","M3","M4"],)
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)
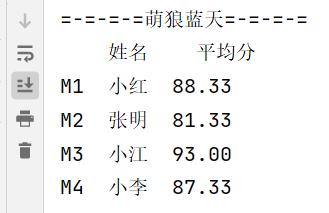
这样子写的话,都不用设置表头了
你也可以这样写:
# 写法2
td1 = pd.DataFrame({"姓名":"小红","平均分":"%.2f"%M1},index=["M1"])
td2 = pd.DataFrame({"姓名":"张明","平均分":"%.2f"%M2},index=["M2"])
td3 = pd.DataFrame({"姓名":"小江","平均分":"%.2f"%M3},index=["M3"])
td4 = pd.DataFrame({"姓名":"小李","平均分":"%.2f"%M4},index=["M4"])
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td1,td2,td3,td4],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)
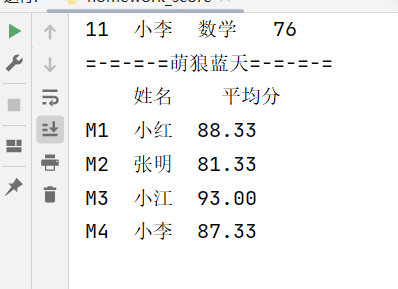
如果你也要测试的话
1.将下面内容保存在名为homework1.txt
姓名,科目,成绩
小红,语文,100
小红,英语,90
小红,数学,75
张明,语文,80
张明,英语,76
张明,数学,88
小江,语文,79
小江,数学,120
小江,英语,80
小李,英语,87
小李,语文,99
小李,数学,76
2.Python源码
import pandas as pd
data = pd.read_table("homework1.txt",sep=",")
print(data)
pd1= data.loc[data["姓名"]=="小红",:]
M1=pd1["成绩"].mean()
pd2= data.loc[data["姓名"]=="张明",:]
M2=pd2["成绩"].mean()
pd3= data.loc[data["姓名"]=="小江",:]
M3=pd3["成绩"].mean()
pd4= data.loc[data["姓名"]=="小李",:]
M4=pd4["成绩"].mean()
# 旧版本操作
# t = pd.DataFrame(columns=["姓名","平均分"])
# t = t.append({"姓名":"小红","平均分":M1},ignore_index=True)
# t = t.append({"姓名":"张明","平均分":M2},ignore_index=True)
# t = t.append({"姓名":"小江","平均分":M3},ignore_index=True)
# t = t.append({"姓名":"小李","平均分":M4},ignore_index=True)
# print(t)
# 新版本操作
# tt = pd.DataFrame(columns=["姓名","平均分"])
# # "%.2f"% 保留小数点后两位
# td = pd.DataFrame([
# {"姓名":"小红","平均分":"%.2f"%M1},
# {"姓名":"张明","平均分":"%.2f"%M2},
# {"姓名":"小江","平均分":"%.2f"%M3},
# {"姓名":"小李","平均分":"%.2f"%M4}],
# index=["M1","M2","M3","M4"],)
# # 如果不设置index,下面的ignore_index设置为True
# result = pd.concat([td],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
# print("=-=-=-=萌狼蓝天=-=-=-=")
# print(result)
# 写法2
td1 = pd.DataFrame({"姓名":"小红","平均分":"%.2f"%M1},index=["M1"])
td2 = pd.DataFrame({"姓名":"张明","平均分":"%.2f"%M2},index=["M2"])
td3 = pd.DataFrame({"姓名":"小江","平均分":"%.2f"%M3},index=["M3"])
td4 = pd.DataFrame({"姓名":"小李","平均分":"%.2f"%M4},index=["M4"])
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td1,td2,td3,td4],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)
【Python】【Pandas】使用concat添加行的更多相关文章
- Python pandas快速入门
Python pandas快速入门2017年03月14日 17:17:52 青盏 阅读数:14292 标签: python numpy 数据分析 更多 个人分类: machine learning 来 ...
- Python pandas & numpy 笔记
记性不好,多记录些常用的东西,真·持续更新中::先列出一些常用的网址: 参考了的 莫烦python pandas DOC numpy DOC matplotlib 常用 习惯上我们如此导入: impo ...
- 使用Python Pandas处理亿级数据
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择. ...
- python merge、concat合并数据集
数据规整化:合并.清理.过滤 pandas和python标准库提供了一整套高级.灵活的.高效的核心函数和算法将数据规整化为你想要的形式! 本篇博客主要介绍: 合并数据集:.merge()..conca ...
- python pandas合并多个excel(xls和xlsx)文件(弹窗选择文件夹和保存文件)
# python pandas合并多个excel(xls和xlsx)文件(弹窗选择文件夹和保存文件) import tkinter as tk from tkinter import filedial ...
- python & pandas链接mysql数据库
Python&pandas与mysql连接 1.python 与mysql 连接及操作,直接上代码,简单直接高效: import MySQLdb try: conn = MySQLdb.con ...
- Python pandas ERROR 2006 (HY000): MySQL server has gone away
之前在做python pandas大数据分析的时候,在将分析后的数据存入mysql的时候报ERROR 2006 (HY000): MySQL server has gone away 原因分析:在对百 ...
- Python+Pandas 读取Oracle数据库
Python+Pandas 读取Oracle数据库 import pandas as pd from sqlalchemy import create_engine import cx_Oracle ...
- 看到篇博文,用python pandas改写了下
看到篇博文,https://blog.csdn.net/young2415/article/details/82795688 需求是需要统计部门礼品数量,自己简单绘制了个表格,如下: 大意是,每个部门 ...
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
随机推荐
- std::variant快速上手
std::variant 是 C++17 引入的一种类型安全的联合体,用来存储多个可能类型中的一种值,且保证使用时的类型安全.相比于传统的 union,std::variant 不仅能够存储不同类型的 ...
- Android libusb
一.环境:配置NDK环境 1.下载libusb源码: https://github.com/libusb/libusb/releases,如下图所示 2.删除一些和Android平台无关的文件,删除后 ...
- 利用cv2.dilate对图像进行膨胀
cv2.getStructuringElement(cv2.MORPH_RECT, (7,7))介绍,请看这个博客.我简要说一下cv2.getStructuringElement,可用于构造一个特定大 ...
- 28. 找出字符串中第一个匹配项的下标 Golang实现
题目描述: 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始).如果 needle 不是 hay ...
- 66.有没有碰到过数组响应丢失(问的是ref和reactive的用法,什么情况下用)
由于vue3使用proxy,对于对象和数组都不能直接整个赋值. 直接赋值丢失了响应性 只有push或者根据索引遍历赋值才可以保留reactive数组的响应性 : 可以使用 toRefs 解决这个问 ...
- 61.null和undefined的区别
null 是空指针,用来保存准备使用的对象,但是现在还没有,用来占位 : undefined 是未定义,是声明了变量但是没有初始化 :
- How To Delete Reservations Using Standard API INV_RESERVATION_PUB.Delete_Reservation (Doc ID 2219367.1)
Solution Summary: The reservation API INV_RESERVATION_PUB.Delete_Reservation will delete reservation ...
- 使用Spectre.Console定制.NET控制台输出样式演示
创建一个控制台项目,引用包Spectre.Console.或者如果需要定制控制台cli命令,也可以引用 Spectre.Console.Cli ,里面自带包含了Spectre.Console ...
- 利用 Kubernetes 内置 PodTemplate 管理 Jenkins 构建节点
作者:Rick Jenkins 可以很好地与 Kubernetes 集成,不管是控制器(controller)还是构建节点(agent),都能以 Pod 的形式运行在 Kubernetes 上. 熟悉 ...
- Web渗透02_信息搜集
以两个测试工具官方给出的用于工具实践的网站.一定不要拿在运营的网站做测试. http://testfire.net http://vulnweb.com DNS信息搜集 关注域名注册商,管理员的邮箱电 ...