【Python】【Pandas】使用concat添加行
添加行
t = pd.DataFrame(columns=["姓名","平均分"])
t = t.append({"姓名":"小红","平均分":M1},ignore_index=True)
t = t.append({"姓名":"张明","平均分":M2},ignore_index=True)
t = t.append({"姓名":"小江","平均分":M3},ignore_index=True)
t = t.append({"姓名":"小李","平均分":M4},ignore_index=True)
print(t)
使用append的时候发出警告如下:
FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
于是我就按它提示的来。
concat是将两个DataFrame拼接起来
td = pd.DataFrame([
{"姓名":"小红","平均分":"%.2f"%M1},
{"姓名":"张明","平均分":"%.2f"%M2},
{"姓名":"小江","平均分":"%.2f"%M3},
{"姓名":"小李","平均分":"%.2f"%M4}],
index=["M1","M2","M3","M4"],)
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)
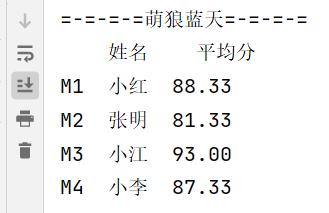
这样子写的话,都不用设置表头了
你也可以这样写:
# 写法2
td1 = pd.DataFrame({"姓名":"小红","平均分":"%.2f"%M1},index=["M1"])
td2 = pd.DataFrame({"姓名":"张明","平均分":"%.2f"%M2},index=["M2"])
td3 = pd.DataFrame({"姓名":"小江","平均分":"%.2f"%M3},index=["M3"])
td4 = pd.DataFrame({"姓名":"小李","平均分":"%.2f"%M4},index=["M4"])
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td1,td2,td3,td4],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)
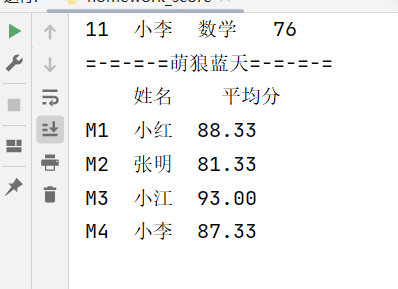
如果你也要测试的话
1.将下面内容保存在名为homework1.txt
姓名,科目,成绩
小红,语文,100
小红,英语,90
小红,数学,75
张明,语文,80
张明,英语,76
张明,数学,88
小江,语文,79
小江,数学,120
小江,英语,80
小李,英语,87
小李,语文,99
小李,数学,76
2.Python源码
import pandas as pd
data = pd.read_table("homework1.txt",sep=",")
print(data)
pd1= data.loc[data["姓名"]=="小红",:]
M1=pd1["成绩"].mean()
pd2= data.loc[data["姓名"]=="张明",:]
M2=pd2["成绩"].mean()
pd3= data.loc[data["姓名"]=="小江",:]
M3=pd3["成绩"].mean()
pd4= data.loc[data["姓名"]=="小李",:]
M4=pd4["成绩"].mean()
# 旧版本操作
# t = pd.DataFrame(columns=["姓名","平均分"])
# t = t.append({"姓名":"小红","平均分":M1},ignore_index=True)
# t = t.append({"姓名":"张明","平均分":M2},ignore_index=True)
# t = t.append({"姓名":"小江","平均分":M3},ignore_index=True)
# t = t.append({"姓名":"小李","平均分":M4},ignore_index=True)
# print(t)
# 新版本操作
# tt = pd.DataFrame(columns=["姓名","平均分"])
# # "%.2f"% 保留小数点后两位
# td = pd.DataFrame([
# {"姓名":"小红","平均分":"%.2f"%M1},
# {"姓名":"张明","平均分":"%.2f"%M2},
# {"姓名":"小江","平均分":"%.2f"%M3},
# {"姓名":"小李","平均分":"%.2f"%M4}],
# index=["M1","M2","M3","M4"],)
# # 如果不设置index,下面的ignore_index设置为True
# result = pd.concat([td],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
# print("=-=-=-=萌狼蓝天=-=-=-=")
# print(result)
# 写法2
td1 = pd.DataFrame({"姓名":"小红","平均分":"%.2f"%M1},index=["M1"])
td2 = pd.DataFrame({"姓名":"张明","平均分":"%.2f"%M2},index=["M2"])
td3 = pd.DataFrame({"姓名":"小江","平均分":"%.2f"%M3},index=["M3"])
td4 = pd.DataFrame({"姓名":"小李","平均分":"%.2f"%M4},index=["M4"])
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td1,td2,td3,td4],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)
【Python】【Pandas】使用concat添加行的更多相关文章
- Python pandas快速入门
Python pandas快速入门2017年03月14日 17:17:52 青盏 阅读数:14292 标签: python numpy 数据分析 更多 个人分类: machine learning 来 ...
- Python pandas & numpy 笔记
记性不好,多记录些常用的东西,真·持续更新中::先列出一些常用的网址: 参考了的 莫烦python pandas DOC numpy DOC matplotlib 常用 习惯上我们如此导入: impo ...
- 使用Python Pandas处理亿级数据
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择. ...
- python merge、concat合并数据集
数据规整化:合并.清理.过滤 pandas和python标准库提供了一整套高级.灵活的.高效的核心函数和算法将数据规整化为你想要的形式! 本篇博客主要介绍: 合并数据集:.merge()..conca ...
- python pandas合并多个excel(xls和xlsx)文件(弹窗选择文件夹和保存文件)
# python pandas合并多个excel(xls和xlsx)文件(弹窗选择文件夹和保存文件) import tkinter as tk from tkinter import filedial ...
- python & pandas链接mysql数据库
Python&pandas与mysql连接 1.python 与mysql 连接及操作,直接上代码,简单直接高效: import MySQLdb try: conn = MySQLdb.con ...
- Python pandas ERROR 2006 (HY000): MySQL server has gone away
之前在做python pandas大数据分析的时候,在将分析后的数据存入mysql的时候报ERROR 2006 (HY000): MySQL server has gone away 原因分析:在对百 ...
- Python+Pandas 读取Oracle数据库
Python+Pandas 读取Oracle数据库 import pandas as pd from sqlalchemy import create_engine import cx_Oracle ...
- 看到篇博文,用python pandas改写了下
看到篇博文,https://blog.csdn.net/young2415/article/details/82795688 需求是需要统计部门礼品数量,自己简单绘制了个表格,如下: 大意是,每个部门 ...
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
随机推荐
- [rCore学习笔记 028] Rust 中的动态内存分配
引言 想起我们之前在学习C的时候,总是提到malloc,总是提起,使用malloc现场申请的内存是属于堆,而直接定义的变量内存属于栈. 还记得当初学习STM32的时候CubeIDE要设置stack 和 ...
- Java日期时间API系列20-----Jdk8中java.time包中的新的日期时间API类,ZoneId时区ID大全等。
Java日期时间API系列19-----Jdk8中java.time包中的新的日期时间API类,ZonedDateTime与ZoneId和LocalDateTime的关系,ZonedDateTime格 ...
- .NET使用Graphql的演示
Graphql是什么?先来一段AI给的回答: GraphQL是一种为API设计的查询语言,与REST相比,它提供了更高效.强大和灵活的方法来与数据交互.GraphQL由Facebook于2012年开发 ...
- Kubernetes 新型容器逃逸漏洞预警
作者:米开朗基杨,KubeSphere 布道师,云原生重度感染者 2022 年 1 月 18 日,Linux 维护人员和供应商在 Linux 内核(5.1-rc1+)文件系统上下文功能的 legacy ...
- KubeSphere 社区双周报 | KubeKey v3.0.0 发布 | 2022-11-10
KubeSphere 从诞生的第一天起便秉持着开源.开放的理念,并且以社区的方式成长,如今 KubeSphere 已经成为全球最受欢迎的开源容器平台之一.这些都离不开社区小伙伴的共同努力,你们为 Ku ...
- Java跳出当前的多重嵌套循环的3种解决方法
Java跳出当前的多重嵌套循环的3种解决方法(以双重嵌套为例) 方法一:使用一个布尔型的标记变量flag 1 public static void method1() { 2 boolean flag ...
- linux 基础(9)背景工作管理
前景和背景工作管理 在 linux 中,进程以调用顺序构成一棵树,系统的初始程序是 systemd,然后一个程序又调用另一个程序.当你在 bash 里输入其他指令,这些指令就作为当前shell 的子进 ...
- C++ 简易消息循环
前言 本文将向大家介绍如何使用 C++ 的标准库实现一个异步和并发编程中都非常重要的编程模式:消息循环(Event Loop).尽管市面上存在不少库也提供了同样的功能,但有时候出于一些原因,我们并不想 ...
- ESP8266+ MQTT+SG90(舵机) platformio
ESP8266 + MQTT + SG90(舵机) platformio 连线 ESP8266 MG90S(舵机) GND 棕色 VCC 红色 模拟引脚 橙色 源代码 https://gitee.co ...
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
二.Spring Security默认认证流程及其优缺点 1.Spring Security默认认证流程总结 四.Spring Boot集成Spring Security之认证流程详细介绍了认证流程, ...