pytorch入门 - VGG16神经网络
1. VGG16背景介绍
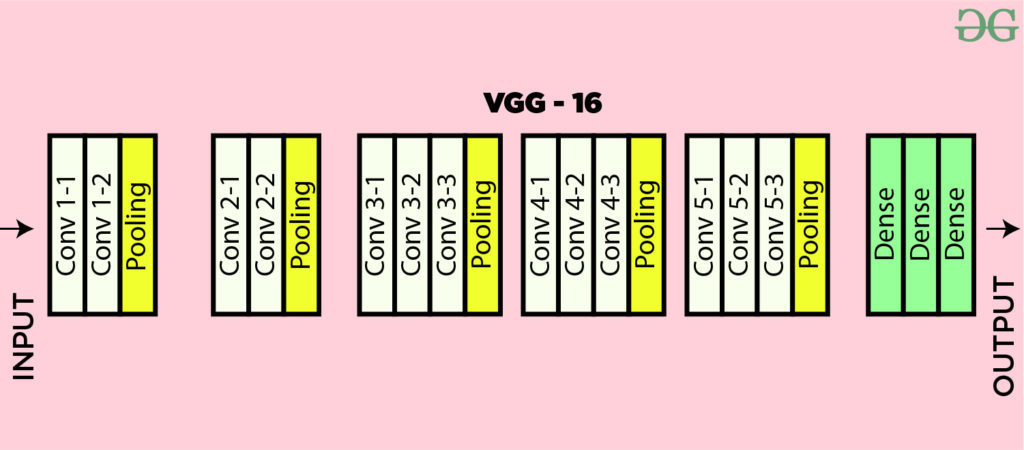
VGG-16是由牛津大学Visual Geometry Group(VGG)在2014年提出的深度卷积神经网络模型,它在当年的ImageNet大规模视觉识别挑战赛(ILSVRC)中取得了优异的成绩。
VGG-16的主要贡献在于展示了通过使用更小的卷积核(3×3)和增加网络深度可以显著提升模型性能。
VGG网络系列包括VGG-11、VGG-13、VGG-16和VGG-19等不同深度的变体,其中VGG-16是最为流行的一个版本。"16"表示网络中包含权重参数的层数(13个卷积层和3个全连接层)。
VGG网络的主要特点包括:
- 全部使用3×3的小卷积核
- 通过堆叠多个卷积层增加网络深度
- 每经过一个池化层,特征图数量翻倍
- 简单而统一的架构设计
2. VGG16架构详解

VGG-16的网络架构可以分为两个主要部分:卷积层部分和全连接层部分。
卷积层部分
VGG-16包含5个卷积块,每个块后接一个最大池化层:
- Block1: 2个卷积层(64通道) + 最大池化
- Block2: 2个卷积层(128通道) + 最大池化
- Block3: 3个卷积层(256通道) + 最大池化
- Block4: 3个卷积层(512通道) + 最大池化
- Block5: 3个卷积层(512通道) + 最大池化
所有卷积层都使用3×3的卷积核,padding=1保持空间尺寸不变,激活函数使用ReLU。池化层使用2×2的窗口,stride=2,将特征图尺寸减半。
全连接层部分
卷积层后接3个全连接层:
- 第一个全连接层:4096个神经元
- 第二个全连接层:4096个神经元
- 第三个全连接层:1000个神经元(对应ImageNet的1000类)
在训练时,全连接层使用了Dropout(0.5)来防止过拟合。
3. 每层参数计算详解
让我们详细计算VGG16各层的参数数量。假设输入为224×224×3的RGB图像。
卷积层参数计算
卷积层的参数数量计算公式为:
参数数量 = (卷积核宽度 × 卷积核高度 × 输入通道数 + 1) × 输出通道数
(其中+1是偏置项)
以Block1的第一个卷积层为例:
- 输入通道:3
- 输出通道:64
- 卷积核:3×3
参数数量 = (3×3×3 + 1)×64 = 28×64 = 1,792
全连接层参数计算
全连接层的参数数量计算公式为:
参数数量 = (输入特征数 + 1) × 输出特征数
以第一个全连接层为例:
- 输入特征数:512×7×7 = 25,088
- 输出特征数:4096
参数数量 = (25,088 + 1)×4,096 = 102,764,544
VGG16总参数
整个VGG16网络约有1.38亿参数,其中大部分(约1.24亿)来自第一个全连接层。
4. 代码实现详解
以下是完整的VGG16实现代码,我们将逐部分解释:
模型定义 (models.py)
import os
import sys
sys.path.append(os.getcwd())
import torch
from torch import nn
from torchsummary import summary
class VGG16(nn.Module):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# Block1: 2个卷积层(64通道) + 最大池化
self.block1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# Block2: 2个卷积层(128通道) + 最大池化
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# Block3: 3个卷积层(256通道) + 最大池化
self.block3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# Block4: 3个卷积层(512通道) + 最大池化
self.block4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# Block5: 3个卷积层(512通道) + 最大池化
self.block5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 全连接层部分
self.block6 = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=512 * 7 * 7, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 10),
)
# 权重初始化
for m in self.modules():
print(m)
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
return x
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VGG16().to(device=device)
print(model)
summary(model, input_size=(1, 224, 224), device=str(device))训练代码 (train.py)
import os
import sys
sys.path.append(os.getcwd())
import time
from torchvision.datasets import FashionMNIST
from torchvision import transforms
from torch.utils.data import DataLoader, random_split
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn, optim
import copy
import pandas as pd
from VGG16_model.model import VGG16
def train_val_date_load():
train_dataset = FashionMNIST(
root="./data",
train=True,
download=True,
transform=transforms.Compose(
[
transforms.Resize(size=224),
transforms.ToTensor(),
]
),
)
train_date, val_data = random_split(
train_dataset,
[
int(len(train_dataset) * 0.8),
len(train_dataset) - int(len(train_dataset) * 0.8),
],
)
train_loader = DataLoader(
dataset=train_date, batch_size=16, shuffle=True, num_workers=1
)
val_loader = DataLoader(
dataset=val_data, batch_size=16, shuffle=True, num_workers=1
)
return train_loader, val_loader
def train_model_process(model, train_loader, val_loader, epochs=10):
device = "cuda" if torch.cuda.is_available() else "cpu"
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
model.to(device)
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
train_loss_all = []
val_loss_all = []
train_acc_all = []
val_acc_all = []
since = time.time()
for epoch in range(epochs):
print(f"Epoch {epoch + 1}/{epochs}")
train_loss = 0.0
train_correct = 0
val_loss = 0.0
val_correct = 0
train_num = 0
val_num = 0
for step, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
model.train()
outputs = model(images)
pre_lab = torch.argmax(outputs, dim=1)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * images.size(0)
train_correct += torch.sum(pre_lab == labels.data)
train_num += labels.size(0)
print(
"Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}, Acc:{:.4f}".format(
epoch + 1,
epochs,
step + 1,
len(train_loader),
loss.item(),
torch.sum(pre_lab == labels.data),
)
)
for step, (images, labels) in enumerate(val_loader):
images = images.to(device)
labels = labels.to(device)
model.eval()
with torch.no_grad():
outputs = model(images)
pre_lab = torch.argmax(outputs, dim=1)
loss = criterion(outputs, labels)
val_loss += loss.item() * images.size(0)
val_correct += torch.sum(pre_lab == labels.data)
val_num += labels.size(0)
print(
"Epoch [{}/{}], Step [{}/{}], Val Loss: {:.4f}, Acc:{:.4f}".format(
epoch + 1,
epochs,
step + 1,
len(val_loader),
loss.item(),
torch.sum(pre_lab == labels.data),
)
)
train_loss_all.append(train_loss / train_num)
val_loss_all.append(val_loss / val_num)
train_acc = train_correct.double() / train_num
val_acc = val_correct.double() / val_num
train_acc_all.append(train_acc.item())
val_acc_all.append(val_acc.item())
print(
f"Train Loss: {train_loss / train_num:.4f}, Train Acc: {train_acc:.4f}, "
f"Val Loss: {val_loss / val_num:.4f}, Val Acc: {val_acc:.4f}"
)
if val_acc_all[-1] > best_acc:
best_acc = val_acc_all[-1]
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print(
f"Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s\n"
f"Best val Acc: {best_acc:.4f}"
)
torch.save(model.state_dict(), "./models/vgg16_net_best_model.pth")
train_process = pd.DataFrame(
data={
"epoch": range(1, epochs + 1),
"train_loss_all": train_loss_all,
"val_loss_all": val_loss_all,
"train_acc_all": train_acc_all,
"val_acc_all": val_acc_all,
}
)
return train_process
def matplot_acc_loss(train_process):
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_process["epoch"], train_process["train_loss_all"], label="Train Loss")
plt.plot(train_process["epoch"], train_process["val_loss_all"], label="Val Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Loss vs Epoch")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_process["epoch"], train_process["train_acc_all"], label="Train Acc")
plt.plot(train_process["epoch"], train_process["val_acc_all"], label="Val Acc")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("Accuracy vs Epoch")
plt.legend()
plt.tight_layout()
plt.ion()
plt.show()
plt.savefig("./models/vgg16_net_output.png")
if __name__ == "__main__":
traindatam, valdata = train_val_date_load()
result = train_model_process(VGG16(), traindatam, valdata, 10)
matplot_acc_loss(result)测试代码 (test.py)
import os
import sys
sys.path.append(os.getcwd())
import torch
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
from torchvision.datasets import FashionMNIST
from VGG16_model.model import VGG16
def test_data_load():
test_dataset = FashionMNIST(
root="./data",
train=False,
download=True,
transform=transforms.Compose(
[
transforms.Resize(size=224),
transforms.ToTensor(),
]
),
)
test_loader = DataLoader(
dataset=test_dataset, batch_size=16, shuffle=True, num_workers=1
)
return test_loader
print(test_data_load())
def test_model_process(model, test_loader):
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += torch.sum(predicted == labels.data)
accuracy = correct / total * 100
print(f"Test Accuracy: {accuracy:.2f}%")
if __name__ == "__main__":
test_loader = test_data_load()
model = VGG16()
model.load_state_dict(torch.load("./models/vgg16_net_best_model.pth"))
test_model_process(model, test_loader)5. 代码实现关键点解析
模型定义关键点
卷积块设计:每个卷积块包含多个卷积层,使用3×3卷积核和ReLU激活函数,最后接一个2×2的最大池化层。
权重初始化:使用Kaiming初始化方法初始化卷积层权重,使用正态分布初始化全连接层权重。
输入适配:原始VGG16设计用于224×224×3的输入,这里调整为224×224×1以适应FashionMNIST数据集。
训练过程关键点
数据加载:使用FashionMNIST数据集,调整大小为224×224以适应VGG16。
训练循环:包含完整的训练和验证过程,记录每轮的损失和准确率。
模型保存:保存验证集上表现最好的模型参数。
可视化:绘制训练和验证的损失及准确率曲线。
测试过程关键点
模型加载:从保存的文件加载最佳模型参数。
评估模式:使用
model.eval()和torch.no_grad()确保评估过程不计算梯度。准确率计算:统计所有测试样本的预测准确率。
6. 总结
VGG-16是一个经典的深度卷积神经网络,其主要特点包括:
简单统一的设计:全部使用3×3卷积核和2×2池化层,结构清晰。
深度优势:通过增加网络深度提高了特征提取能力。
小卷积核优势:多个小卷积核堆叠可以模拟大感受野,同时减少参数数量。
广泛应用:虽然现在有更高效的网络,但VGG16仍广泛用于特征提取和迁移学习。
pytorch入门 - VGG16神经网络的更多相关文章
- Pytorch入门随手记
Pytorch入门随手记 什么是Pytorch? Pytorch是Torch到Python上的移植(Torch原本是用Lua语言编写的) 是一个动态的过程,数据和图是一起建立的. tensor.dot ...
- pytorch 入门指南
两类深度学习框架的优缺点 动态图(PyTorch) 计算图的进行与代码的运行时同时进行的. 静态图(Tensorflow <2.0) 自建命名体系 自建时序控制 难以介入 使用深度学习框架的优点 ...
- 超简单!pytorch入门教程(五):训练和测试CNN
我们按照超简单!pytorch入门教程(四):准备图片数据集准备好了图片数据以后,就来训练一下识别这10类图片的cnn神经网络吧. 按照超简单!pytorch入门教程(三):构造一个小型CNN构建好一 ...
- pytorch入门2.0构建回归模型初体验(数据生成)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- pytorch入门2.1构建回归模型初体验(模型构建)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- Pytorch入门——手把手教你MNIST手写数字识别
MNIST手写数字识别教程 要开始带组内的小朋友了,特意出一个Pytorch教程来指导一下 [!] 这里是实战教程,默认读者已经学会了部分深度学习原理,若有不懂的地方可以先停下来查查资料 目录 MNI ...
- Pytorch入门上 —— Dataset、Tensorboard、Transforms、Dataloader
本节内容参照小土堆的pytorch入门视频教程.学习时建议多读源码,通过源码中的注释可以快速弄清楚类或函数的作用以及输入输出类型. Dataset 借用Dataset可以快速访问深度学习需要的数据,例 ...
- Pytorch入门中 —— 搭建网络模型
本节内容参照小土堆的pytorch入门视频教程,主要通过查询文档的方式讲解如何搭建卷积神经网络.学习时要学会查询文档,这样会比直接搜索良莠不齐的博客更快.更可靠.讲解的内容主要是pytorch核心包中 ...
- Pytorch入门下 —— 其他
本节内容参照小土堆的pytorch入门视频教程. 现有模型使用和修改 pytorch框架提供了很多现有模型,其中torchvision.models包中有很多关于视觉(图像)领域的模型,如下图: 下面 ...
- 第一章:PyTorch 入门
第一章:PyTorch 入门 1.1 Pytorch 简介 1.1.1 PyTorch的由来 1.1.2 Torch是什么? 1.1.3 重新介绍 PyTorch 1.1.4 对比PyTorch和Te ...
随机推荐
- laravel-echo-server 启动报错 [ioredis] Unhandled error event: ReplyError: NOAUTH Authentication required.
可以在 .env 文件加上以下配置 LARAVEL_ECHO_SERVER_REDIS_HOST= LARAVEL_ECHO_SERVER_REDIS_PASSWORD= LARAVEL_ECHO_S ...
- WebSocket 的产生
HTTP 不断轮询 怎么样才能在用户不做任何操作的情况下,网页能收到消息并发生变更. 最常见的解决方案是,网页的前端代码里不断定时发 HTTP 请求到服务器,服务器收到请求后给客户端响应消息. 这种方 ...
- HTTP/1.1、HTTP/2、HTTP/3
HTTP/1.1 相比 HTTP/1.0 性能上的改进: 使用长连接的方式改善了 HTTP/1.0 短连接造成的性能开销. 支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来, ...
- oracle数据库体系架构详解
在学习oracle中,体系结构是重中之重,一开始从宏观上掌握它的物理组成.文件组成和各种文件组成.掌握的越深入越好.在实际工作遇到疑难问题,其实都可以归结到体系结构中来解释.体系结构是对一个系统的框架 ...
- 基于Docker+DeepSeek+Dify:搭建企业级本地私有化知识库超详细教程
在当今信息爆炸的时代,如何高效地管理和利用知识成为了企业竞争力的关键.为了帮助企业构建专属的知识库,本文将详细介绍如何使用Docker.DeepSeek和Dify来搭建一个企业级本地私有化知识库. 1 ...
- CI/CD 概念简介
〇.前言 CI/CD 是现代软件开发的核心实践,通过自动化和协作,显著提升交付效率和质量. 本文将对 CI 和 CD 这两个概念进行简要介绍,供参考. 一.CI/CD 的核心概念 CI/CD 是 De ...
- VBA_LoadPicture报错:子过程或子函数未定义
需要增加如下引用: While in the VBE select Tools>References>find and check "OLE Automation" 参 ...
- 网鼎杯-phpweb
找了一些php读取文件的函数尝试读取源码,试了一个readfile就成功了 <?php $disable_fun = array("exec","shell_exe ...
- SpringCloud动态更新(加载)nacos配置
nacos端 nacos中配置文件中增加属性 app: version: 1.0.0 SpringCloud端 增加读取配置的代码 @Service @RefreshScope public clas ...
- Java编程--多例设计模式
多例设计模式 多例设计模式(Multiton Pattern),有时也被称为对象池(Object Pool)模式,是一种创建型设计模式.与单例模式不同,多例模式允许创建并管理多个实例,每个实例都有一个 ...