K均值聚类和代码实现
K均值聚类是一种无监督学习分类算法。
介绍
对于$n$个$m$维特征的样本,K均值聚类是求解最优化问题:
$\displaystyle C^*=\text{arg}\min\limits_{C}\sum\limits_{l = 1}^K\sum\limits_{x\in C_l}||x-x_l||^2$
其中$C$表示某种样本的划分方式,$x\in C_l$表示被划分在第$l$类的样本,$x_l$表示被划分在第$l$类的所有样本的中心,也就是均值。所以上式表示最小化所有类别内样本到其对应的类别样本均值的距离之和。最优化这个问题是NP难问题,所以现实采用类似贪心的迭代算法来逼近最优解(不一定最优)。具体流程如下(每个样本只能属于一个类别):
0、初始化$K$个类的均值为随机$m$维向量。
1、将每个样本划分到与之距离最小的类别均值对应的类别中。
2、根据划分进的样本,每个类别重新计算类别均值,并记录。
3、比较连续两次的类别均值,如果差别小于一定阈值就结束,否则回到1。
通过计算可以知道时间复杂度是$O(mnk)$。
代码实现
Numpy手动实现
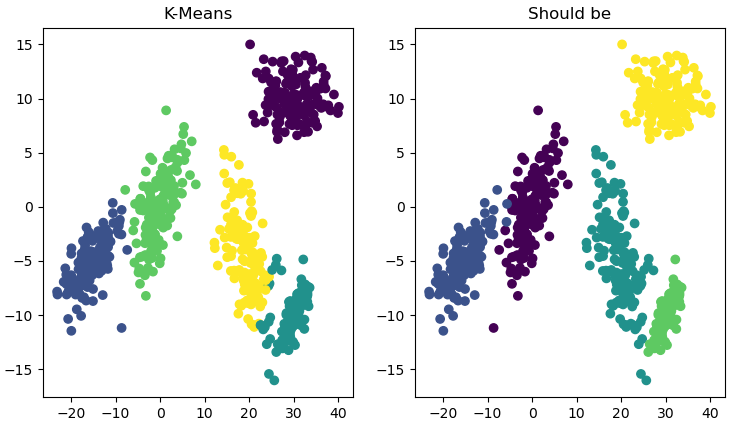
首先使用由正态分布生成的两簇点集来实验,每个簇各200个点。可能由于这两个点集比较靠近,所以分类完全错误,如图:

重新生成5簇正态分布点集,这次每个集合之间相对较远,除了少数没有正确聚类外(两类交汇处),表现不错:

代码如下:
#%%获取数据
import matplotlib.pyplot as plt
import numpy as np
import xlrd table = xlrd.open_workbook('test.xlsx').sheets()[0]#读取Excel数据
data = []
for i in range(0,table.nrows):#假设第一行是表头不读入
data.append(table.row_values(i))
data = np.array(data)
#%%聚类
def distance(a,b):
d = a-b
return np.dot(d,d)
def clusterize(data,class_m):#关于类均值对样本分类
for i in data:
min_dis = np.inf
for j in range(len(class_m)):
t = distance(i[:-1],class_m[j])
if t<min_dis:
min_dis=t
i[-1]=j def calc_mean(data,class_m):#以类中样本计算均值
class_m -= class_m
num = np.zeros([len(class_m)])
for i in data:
num[int(i[-1])]+=1
class_m[int(i[-1])]+=i[:-1]
for i in range(len(class_m)):
class_m[i]/=num[i]
def updated_mean(dif):#计算前后两次更新的均值距离,传入前后差值
sum_ = 0
for i in dif:
sum_ += np.dot(i,i)
return sum_
def k_means_cluster(data,K):
class_mean = data[0:K,:-1]
class_mean_old = -class_mean
t = updated_mean(class_mean-class_mean_old)
ii = 0
while t>0.0001:
class_mean_old = class_mean.copy()
clusterize(data,class_mean)
print(class_mean)
print(class_mean_old)
calc_mean(data,class_mean)
print(class_mean)
print(class_mean_old)
t = updated_mean(class_mean-class_mean_old)
print(t)
ii+=1
print(ii)
data1 = data.copy()
np.random.shuffle(data1)
k_means_cluster(data1,5) #要分几类直接这里设置################################## #%%绘制结果
import matplotlib.pyplot as plt fig = plt.figure()
ax1 = fig.add_subplot(121)
ax2 = fig.add_subplot(122)
ax1.scatter(data1[:,0],data1[:,1],c = data1[:,-1])
ax1.set_title("K-Means")
ax2.scatter(data[:,0],data[:,1],c = data[:,-1])
ax2.set_title("Should be")
plt.show()
Sklearn
使用封装好的Sklearn,代码如下:
#%%获取数据
import matplotlib.pyplot as plt
import numpy as np
import xlrd table = xlrd.open_workbook('test.xlsx').sheets()[0]#读取Excel数据
data = []
for i in range(0,table.nrows):#假设第一行是表头不读入
data.append(table.row_values(i))
data = np.array(data)
#%%聚类
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=5)
kmeans.fit(data[:,:-1])
y = kmeans.predict(data[:,:-1])
fig = plt.figure()
ax1 = fig.add_subplot(121)
ax1.scatter(data[:,0],data[:,1],c = y)
ax1.set_title("K-Means")
ax2 = fig.add_subplot(122)
ax2.scatter(data[:,0],data[:,1],c=data[:,-1])
ax2.set_title("Should be")
plt.show()
结果图:
K均值聚类和代码实现的更多相关文章
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=> ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- SciPy k均值聚类
章节 SciPy 介绍 SciPy 安装 SciPy 基础功能 SciPy 特殊函数 SciPy k均值聚类 SciPy 常量 SciPy fftpack(傅里叶变换) SciPy 积分 SciPy ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
随机推荐
- Docker容器常用操作命令(镜像的上传、下载、导入、导出、创建、删除、修改、启动等)详解
1.docker镜像下载 docker pull [options] name [:tag@digest] name后边可以跟镜像标签或者镜像摘要(其实就是镜像的版本),如果不加任何东西,则会默认是在 ...
- 技术解析 | ZEGO 移动端超分辨率技术
即构超分追求:速度更快.效果更好.码率更低.机型更广. 超分辨率(Super Resolution, SR)是从给定的低分辨率(Low Resolution, LR)图像中恢复高分辨率(High ...
- 安全 – CSP (Content Security Policy)
前言 之前讲过 CSRF.防 Cookie hacking 的. 也介绍过防 XSS 的 HtmlSanitizer. 今天再介绍 CSP. 参考 Content Security Policy 介绍 ...
- CSS – Counters
介绍 counter 有点像 JS 的 for loop index. 最常用到的地方就是做 ol > li. 参考: W3Schools – CSS Counters 默认 ol > l ...
- 阿里面试官常问的TCP和UDP,你真的弄懂了吗?
前 言 作为软件测试,大家都知道一些常用的网络协议是我们必须要了解和掌握的,面试的时候面试官也非常喜欢问一些协议相关的问题,其中有两个协议因为非常基础,出现的频率非常之高,分别是 "T ...
- 参与 2023 第一季度官方 Flutter 开发者调查
Flutter 3.7 已经正式发布,每个季度一次的 Flutter 开发者调查也如约而至,邀请社区的各位成员们填写! 调查表链接: https://flutter.cn/urls/2023q1wx ...
- Web刷题之polarctf靶场(2)
1.蜜雪冰城吉警店 点开靶场, 发现题目说点到隐藏奶茶(也就是第九杯)就给flag, 但是明显就只有八杯, 猜测大概率考的是前端代码修改 把id=1修改为id=9, 然后回到页面点击原味奶茶即可弹出f ...
- docker安装及基本的镜像拉取
docker 使用存储库安装 卸载它们以及相关的依赖项. yum remove docker \ docker-client \ docker-client-latest \ docker-commo ...
- push_back和 emplace_back背后的逻辑
push_back 与 emplace_back 的区别 push_back: 功能:将一个对象(或其副本)添加到 vector 的末尾. 参数:接受一个对象(或其副本)的引用. 过程: 如果传入的是 ...
- pytorch中y.data.norm()的含义
import torch x = torch.randn(3, requires_grad=True) y = x*2 print(y.data.norm()) print(torch.sqrt(to ...