python下的多线程与多进程
多进程:
进程我们可以理解为是一个可以独立运行的程序单位,比如打开一个浏览器,这就开启了一个浏览器进程;打开一个文本编辑器,这就开启了一个文本编辑器进程。但一个进程中是可以同时处理很多事情的,比如在浏览器中,我们可以在多个选项卡中打开多个页面,有的页面在播放音乐,有的页面在播放视频,有的网页在播放动画,它们可以同时运行,互不干扰。为什么能同时做到同时运行这么多的任务呢?这里就需要引出线程的概念了,其实这一个个任务,实际上就对应着一个个线程的执行。
而进程呢?它就是线程的集合,进程就是由一个或多个线程构成的,线程是操作系统进行运算调度的最小单位,是进程中的一个最小运行单元。比如上面所说的浏览器进程,其中的播放音乐就是一个线程,播放视频也是一个线程,当然其中还有很多其他的线程在同时运行,这些线程的并发或并行执行最后使得整个浏览器可以同时运行这么多的任务。
并行与并发:
并发,英文叫作 concurrency。它是指同一时刻只能有一条指令执行,但是多个线程的对应的指令被快速轮换地执行。比如一个处理器,它先执行线程 A 的指令一段时间,再执行线程 B 的指令一段时间,再切回到线程 A 执行一段时间。
由于处理器执行指令的速度和切换的速度非常非常快,人完全感知不到计算机在这个过程中有多个线程切换上下文执行的操作,这就使得宏观上看起来多个线程在同时运行。但微观上只是这个处理器在连续不断地在多个线程之间切换和执行,每个线程的执行一定会占用这个处理器一个时间片段,同一时刻,其实只有一个线程在执行。
并行,英文叫作 parallel。它是指同一时刻,有多条指令在多个处理器上同时执行,并行必须要依赖于多个处理器。不论是从宏观上还是微观上,多个线程都是在同一时刻一起执行的。
并行只能在多处理器系统中存在,如果我们的计算机处理器只有一个核,那就不可能实现并行。而并发在单处理器和多处理器系统中都是可以存在的,因为仅靠一个核,就可以实现并发。
举个例子,比如系统处理器需要同时运行多个线程。如果系统处理器只有一个核,那它只能通过并发的方式来运行这些线程。如果系统处理器有多个核,当一个核在执行一个线程时,另一个核可以执行另一个线程,这样这两个线程就实现了并行执行,当然其他的线程也可能和另外的线程处在同一个核上执行,它们之间就是并发执行。具体的执行方式,就取决于操作系统的调度了。
多线程使用场景:
在一个程序进程中,有一些操作是比较耗时或者需要等待的,比如等待数据库的查询结果的返回,等待网页结果的响应。如果使用单线程,处理器必须要等到这些操作完成之后才能继续往下执行其他操作,而这个线程在等待的过程中,处理器明显是可以来执行其他的操作的。如果使用多线程,处理器就可以在某个线程等待的时候,去执行其他的线程,从而从整体上提高执行效率。
像上述场景,线程在执行过程中很多情况下是需要等待的。比如网络爬虫就是一个非常典型的例子,爬虫在向服务器发起请求之后,有一段时间必须要等待服务器的响应返回,这种任务就属于 IO 密集型任务。对于这种任务,如果我们启用多线程,处理器就可以在某个线程等待的过程中去处理其他的任务,从而提高整体的爬取效率。
但并不是所有的任务都是 IO 密集型任务,还有一种任务叫作计算密集型任务,也可以称之为 CPU 密集型任务。顾名思义,就是任务的运行一直需要处理器的参与。此时如果我们开启了多线程,一个处理器从一个计算密集型任务切换到切换到另一个计算密集型任务上去,处理器依然不会停下来,始终会忙于计算,这样并不会节省总体的时间,因为需要处理的任务的计算总量是不变的。如果线程数目过多,反而还会在线程切换的过程中多耗费一些时间,整体效率会变低。
所以,如果任务不全是计算密集型任务,我们可以使用多线程来提高程序整体的执行效率。尤其对于网络爬虫这种 IO 密集型任务来说,使用多线程会大大提高程序整体的爬取效率。
多线程示例:
1.基本使用
import threading
import time def func1(n):
print(f'{threading.current_thread().name} is running')
print(f'{threading.current_thread().name} is sleep {n}s')
time.sleep(n)
print(f'{threading.current_thread().name} is end') for i in [1, 5]:
t = threading.Thread(target=func1, args=[I]) # 创建一个线程 第一个参数为调用的方法,第二个是传递的参数(以列表的方式)
t.start() #开始线程任务
#t.join() print(f'{threading.current_thread().name} is ended') 特点:
主线程与子线程是各自跑自己的程序,也就是说主线程结束了,可能子线程还在运行当中
如果我想让主线程等待子线程执行完成之后,再向下执行,就需要添加一个join方法
2.支持使用继承线程类的方式
import threading
class MyThread(threading.Thread):
def __init__(self, second):
threading.Thread.__init__(self) # 继承父类初始化方法
self.second = second
def run(self):
print(f'Threading {threading.current_thread().name} is running')
print(f'Threading {threading.current_thread().name} is sleep {self.second}s')
print(f'Threading {threading.current_thread().name} is end')
print(f'Threading {threading.current_thread().name} is running...')
for i in [1, 5]:
t = MyThread(i)
t.start()
# t.join()
print(f'Threading {threading.current_thread().name} is ended')
3. 在线程中有一个叫作守护线程的概念,如果一个线程被设置为守护线程,那么意味着这个线程是“不重要”的,这意味着,如果主线程结束了而该守护线程还没有运行完,那么它将会被强制结束。
import threading
import time def func1(n):
print(f'{threading.current_thread().name} is running')
print(f'{threading.current_thread().name} is sleep {n}s')
time.sleep(n)
print(f'{threading.current_thread().name} is end') print(f'Threading {threading.current_thread().name} is running')
# 使用守护线程方式运行
t1 = threading.Thread(target=func1, args=[1])
t1.start()
t1.join() t2 = threading.Thread(target=func1, args=[5])
t2.setDaemon(True)
t2.start()
#t2.join()
print(f'Threading {threading.current_thread().name} is ended')
#这样主线程结束之后,子线程即使没有执行完成,也会强制退出, 如果不想这样的话,可以添加join方法等待子进程的结束
4. 互斥锁(一个进程中,多个线程之间是资源共享的)
import threading
import time count = 0
class MyThread(threading.Thread): def __init__(self):
threading.Thread.__init__(self) def run(self):
global count
#lock.acquire()
temp = count+1
time.sleep(0.001)
count = temp
#lock.release() # 释放锁 #lock = threading.Lock() threads = []
for i in range(1, 1001):
print(i)
t = MyThread()
t.start()
threads.append(t) for thread in threads:
thread.join() print(f'Final count: {count}') 没有加锁的情况下,最终得到的count并不是1000, 而是比1000较小, 为了避免,我们需要对多个线程进行同步,要实现同步,我们可以对需要操作的数据进行加锁保护 使用线程锁 threading.Lock() 经历了获取锁==>lock.acquire()
执行逻辑代码
释放锁==> lock.release()
线程池:
传统多线程方案会使用“即时创建,即时销毁”的策略。尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务时执行时间较短,而且执行次数及其频繁,那么服务器将处于不停的创建线程,销毁线程的状态。
一个线程的运行时间可以分为三部分:线程的启动时间、线程体的运行时间和线程的销毁时间。在多线程处理的情景中,如果线程不能被重用,就意味着每次线程运行都要经过启动、销毁和运行3个过程。这必然会增加系统相应的时间,减低了效率。
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,能带来更好的性能和稳定性。
此外,使用线程池可以有效地控制系统中并发线程的数量。当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致Python解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量不超过此数。
服务器CPU数有限,能够同时并发的线程数有限,并不是开得越多越好,以及线程切换时有开销的,如果线程切换过于频繁,反而会使性能降低
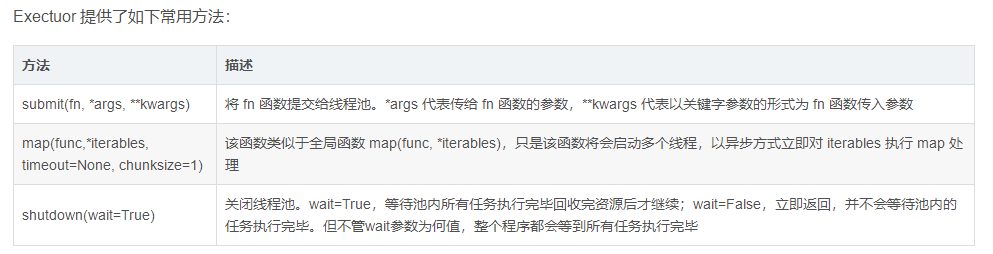
从python3.2开始,标准库提供了concurrent.futures模块,它提供了两个子类:ThreadPoolExecutor和ProcessPoolExecutor。其中ThreadPoolExecutor用于创建线程池,而ProcessPoolExecutor用于创建进程池。不仅可以自动调度线程,还可以做到:
• 主线程可以获取某一个线程(或任务)的状态,以及返回值
• 当一个线程完成的时候,主线程能够立即知道
• 让多线程和多进程编码接口一致
使用线程池/进程池来管理并发编程,只要将相应的 task 函数提交给线程池/进程池,剩下的事情就由线程池/进程池来搞定。
ThreadPoolExecutor构造函数有两个参数:
一个是max_workers参数,用于指定线程池的最大线程数,如果不指定的话则默认是CPU核数的5倍。
另一个参数是thread_name_prefix,它用来指定线程池中线程的名称前缀(可选),如下:
threadPool = ThreadPoolExecutor(max_workers=self.max_workers, thread_name_prefix="test_")
程序将 task 函数提交(submit)给线程池后,submit 方法会返回一个 Future 对象,Future 类主要用于获取线程任务函数的返回值。由于线程任务会在新线程中以异步方式执行,因此线程执行的函数相当于一个“将来完成”的任务,所以 Python 使用 Future 来代表。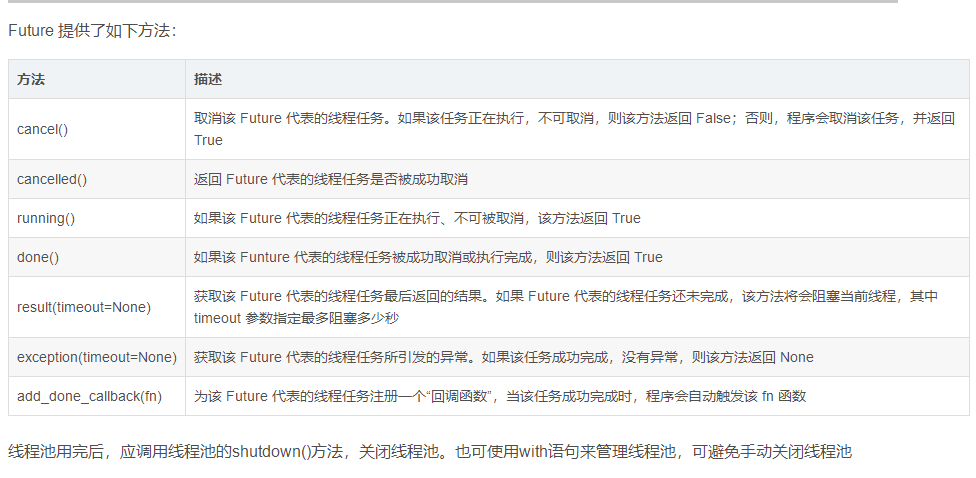
示例1:
from concurrent.futures import ThreadPoolExecutor # 导入ThreadPoolExecutor模块
import time max_workers = 5
t = []
t1 = time.time() # 作为线程任务的函数
def task(x, y):
return x + y threadPool = ThreadPoolExecutor(max_workers) # 创建最大线程数为max_workers的线程池 for i in range(20): # 循环向线程池中提交task任务
future = threadPool.submit(task, i, i+1)
t.append(future) # 若不需要获取返回值,则可不需要下面两行代码
for i in t:
print(i.result()) # 获取每个任务的返回值,result()会阻塞主线程 threadPool.shutdown() # 阻塞主线程,所有任务执行完后关闭线程池
print(time.time() - t1)
示例2:(map)
from concurrent.futures import ThreadPoolExecutor # 导入ThreadPoolExecutor模块 max_workers = 5
t = []
t1 = time.time() # 作为线程任务的函数
def task(x):
return x + (x + 1) args = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19) with ThreadPoolExecutor(max_workers) as threadPool: # 创建最大线程数为max_workers的线程池
results = threadPool.map(task, args) # 启动线程,并收集每个线任务的返回结果 # 若无返回值,则可不需要下面两行代码
for i in results:
print(i)
示例3:
as_complete():是一个生成器,在没有任务完成的时候会阻塞,在有某个任务完成的时候会yield这个任务,执行语句,继续阻塞,循环到所有任务结束,先完成的任务会先通知主线程
from concurrent.futures import ThreadPoolExecutor, as_completed
import time max_workers = 5
t = []
t1 = time.time() # 作为线程任务的函数
def task(x, y):
return x + y def handle_result(future):
print(future.result()) with ThreadPoolExecutor(max_workers) as threadPool: # 创建最大线程数为max_workers的线程池 for i in range(20): # 循环向线程池中提交task任务
future = threadPool.submit(task, i, i+1)
t.append(future) # 若不需要获取返回值,则可不需要下面两行代码
for future in as_completed(t): # as_completed,哪个先完成就先处理哪个,会阻塞主线程,直到完成所有,除非设置timeout
future.add_done_callback(handle_result)
多进程:
进程(Process)是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。
顾名思义,多进程就是启用多个进程同时运行。由于进程是线程的集合,而且进程是由一个或多个线程构成的,所以多进程的运行意味着有大于或等于进程数量的线程在运行。
优势:
我们知道,由于进程中 GIL 的存在,Python 中的多线程并不能很好地发挥多核优势,一个进程中的多个线程,在同一时刻只能有一个线程运行。
而对于多进程来说,每个进程都有属于自己的 GIL,所以,在多核处理器下,多进程的运行是不会受 GIL 的影响的。因此,多进程能更好地发挥多核的优势。
当然,对于爬虫这种 IO 密集型任务来说,多线程和多进程影响差别并不大。对于计算密集型任务来说,Python 的多进程相比多线程,其多核运行效率会有成倍的提升。
总的来说,Python 的多进程整体来看是比多线程更有优势的。所以,在条件允许的情况下,能用多进程就尽量用多进程。
不过值得注意的是,由于进程是系统进行资源分配和调度的一个独立单位,所以各个进程之间的数据是无法共享的,如多个进程无法共享一个全局变量,进程之间的数据共享需要有单独的机制来实现,这在后面也会讲到。
基本使用:
Process([group [, target [, name [, args [, kwargs]]]]]) target表示调用对象,你可以传入方法的名字
args表示被调用对象的位置参数元组,比如target是函数a,他有两个参数m,n,那么args就传入(m, n)即可
kwargs表示调用对象的字典
name是别名,相当于给这个进程取一个名字
group分组,实际上不使用
示例1:
import multiprocessing def process(num):
print 'Process:', num if __name__ == '__main__':
for i in range(5):
p = multiprocessing.Process(target=process, args=(i,))
p.start() 最简单的创建Process的过程如上所示,target传入函数名,args是函数的参数,是元组的形式,如果只有一个参数,那就是长度为1的元组。 然后调用start()方法即可启动多个进程了。
示例2:
import multiprocessing
import time def process(num):
time.sleep(num)
print 'Process:', num if __name__ == '__main__':
for i in range(5):
p = multiprocessing.Process(target=process, args=(i,))
p.start() print('CPU number:' + str(multiprocessing.cpu_count()))
for p in multiprocessing.active_children():
print('Child process name: ' + p.name + ' id: ' + str(p.pid)) print('Process Ended')
示例3:
from multiprocessing import Process
import time class MyProcess(Process):
def __init__(self, loop):
Process.__init__(self)
self.loop = loop def run(self):
for count in range(self.loop):
time.sleep(1)
print('Pid: ' + str(self.pid) + ' LoopCount: ' + str(count)) if __name__ == '__main__':
for i in range(2, 5):
p = MyProcess(i)
p.start() 继承了 Process 这个类,然后实现了run方法。
示例4:
from multiprocessing import Process
import time class MyProcess(Process):
def __init__(self, loop):
Process.__init__(self)
self.loop = loop def run(self):
for count in range(self.loop):
time.sleep(1)
print('Pid: ' + str(self.pid) + ' LoopCount: ' + str(count)) if __name__ == '__main__':
for i in range(2, 5):
p = MyProcess(i)
p.daemon = True
p.start() print 'Main process Ended!' 调用的时候增加了设置deamon,每个线程都可以单独设置它的属性,如果设置为True,当父进程结束后,子进程会自动被终止。
示例5:
from multiprocessing import Process
import time class MyProcess(Process):
def __init__(self, loop):
Process.__init__(self)
self.loop = loop def run(self):
for count in range(self.loop):
time.sleep(1)
print('Pid: ' + str(self.pid) + ' LoopCount: ' + str(count)) if __name__ == '__main__':
for i in range(2, 5):
p = MyProcess(i)
p.daemon = True
p.start()
p.join() print 'Main process Ended!' 每个子进程都调用了join()方法,这样父进程(主进程)就会等待子进程执行完毕
示例6:
from multiprocessing import Process, Lock
import time class MyProcess(Process):
def __init__(self, loop, lock):
Process.__init__(self)
self.loop = loop
self.lock = lock def run(self):
for count in range(self.loop):
time.sleep(0.1)
self.lock.acquire()
print('Pid: ' + str(self.pid) + ' LoopCount: ' + str(count))
self.lock.release() if __name__ == '__main__':
lock = Lock()
for i in range(10, 15):
p = MyProcess(i, lock)
p.start() 互斥锁。在一个进程输出时,加锁,其他进程等待。等此进程执行结束后,释放锁,其他进程可以进行输出。
Semaphore
信号量,是在进程同步过程中一个比较重要的角色。可以控制临界资源的数量,保证各个进程之间的互斥和同步。
from multiprocessing import Process, Semaphore, Lock, Queue
import time buffer = Queue(10)
empty = Semaphore(2)
full = Semaphore(0)
lock = Lock() class Consumer(Process): def run(self):
global buffer, empty, full, lock
while True:
full.acquire()
lock.acquire()
buffer.get()
print('Consumer pop an element')
time.sleep(1)
lock.release()
empty.release() class Producer(Process):
def run(self):
global buffer, empty, full, lock
while True:
empty.acquire()
lock.acquire()
buffer.put(1)
print('Producer append an element')
time.sleep(1)
lock.release()
full.release() if __name__ == '__main__':
p = Producer()
c = Consumer()
p.daemon = c.daemon = True
p.start()
c.start()
p.join()
c.join()
print 'Ended!'
如上代码实现了注明的生产者和消费者问题,定义了两个进程类,一个是消费者,一个是生产者。
定义了一个共享队列,利用了Queue数据结构,然后定义了两个信号量,一个代表缓冲区空余数,一个表示缓冲区占用数。
生产者Producer使用empty.acquire()方法来占用一个缓冲区位置,然后缓冲区空闲区大小减小1,接下来进行加锁,对缓冲区进行操作。然后释放锁,然后让代表占用的缓冲区位置数量+1,消费者则相反。
Queue
在上面的例子中我们使用了Queue,可以作为进程通信的共享队列使用。
在上面的程序中,如果你把Queue换成普通的list,是完全起不到效果的。即使在一个进程中改变了这个list,在另一个进程也不能获取到它的状态。
因此进程间的通信,队列需要用Queue。当然这里的队列指的是 multiprocessing.Queue
依然是用上面那个例子,我们一个进程向队列中放入数据,然后另一个进程取出数据。
from multiprocessing import Process, Semaphore, Lock, Queue
import time
from random import random buffer = Queue(10)
empty = Semaphore(2)
full = Semaphore(0)
lock = Lock() class Consumer(Process): def run(self):
global buffer, empty, full, lock
while True:
full.acquire()
lock.acquire()
print 'Consumer get', buffer.get()
time.sleep(1)
lock.release()
empty.release() class Producer(Process):
def run(self):
global buffer, empty, full, lock
while True:
empty.acquire()
lock.acquire()
num = random()
print 'Producer put ', num
buffer.put(num)
time.sleep(1)
lock.release()
full.release() if __name__ == '__main__':
p = Producer()
c = Consumer()
p.daemon = c.daemon = True
p.start()
c.start()
p.join()
c.join()
print 'Ended!'
Queue.empty() 如果队列为空,返回True, 反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 获取队列,timeout等待时间
Queue.get_nowait() 相当Queue.get(False)
Queue.put(item) 阻塞式写入队列,timeout等待时间
Queue.put_nowait(item) 相当Queue.put(item, False)
Pipe
管道,顾名思义,一端发一端收。
Pipe可以是单向(half-duplex),也可以是双向(duplex)。我们通过mutiprocessing.Pipe(duplex=False)创建单向管道 (默认为双向)。一个进程从PIPE一端输入对象,然后被PIPE另一端的进程接收,单向管道只允许管道一端的进程输入,而双向管道则允许从两端输入。
from multiprocessing import Process, Pipe class Consumer(Process):
def __init__(self, pipe):
Process.__init__(self)
self.pipe = pipe def run(self):
self.pipe.send('Consumer Words')
print 'Consumer Received:', self.pipe.recv() class Producer(Process):
def __init__(self, pipe):
Process.__init__(self)
self.pipe = pipe def run(self):
print 'Producer Received:', self.pipe.recv()
self.pipe.send('Producer Words') if __name__ == '__main__':
pipe = Pipe()
p = Producer(pipe[0])
c = Consumer(pipe[1])
p.daemon = c.daemon = True
p.start()
c.start()
p.join()
c.join()
print 'Ended!'
Pool
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
在这里需要了解阻塞和非阻塞的概念。
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态。
阻塞即要等到回调结果出来,在有结果之前,当前进程会被挂起。
Pool的用法有阻塞和非阻塞两种方式。非阻塞即为添加进程后,不一定非要等到改进程执行完就添加其他进程运行,阻塞则相反。
from multiprocessing import Lock, Pool
import time def function(index):
print 'Start process: ', index
time.sleep(3)
print 'End process', index if __name__ == '__main__':
pool = Pool(processes=3)
for i in xrange(4):
pool.apply_async(function, (i,)) print "Started processes"
pool.close()
pool.join()
print "Subprocess done." 在这里利用了apply_async方法,即非阻塞。
阻塞方式:
from multiprocessing import Lock, Pool
import time def function(index):
print 'Start process: ', index
time.sleep(3)
print 'End process', index if __name__ == '__main__':
pool = Pool(processes=3)
for i in xrange(4):
pool.apply(function, (i,)) print "Started processes"
pool.close()
pool.join()
print "Subprocess done."
apply_async(func[, args[, kwds[, callback]]]) 它是非阻塞,apply(func[, args[, kwds]])是阻塞的。
close() 关闭pool,使其不在接受新的任务。
terminate() 结束工作进程,不在处理未完成的任务。
join() 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
当然每个进程可以在各自的方法返回一个结果。apply或apply_async方法可以拿到这个结果并进一步进行处理。
from multiprocessing import Lock, Pool
import time def function(index):
print 'Start process: ', index
time.sleep(3)
print 'End process', index
return index if __name__ == '__main__':
pool = Pool(processes=3)
for i in xrange(4):
result = pool.apply_async(function, (i,))
print result.get()
print "Started processes"
pool.close()
pool.join()
print "Subprocess done."
如果你现在有一堆数据要处理,每一项都需要经过一个方法来处理,那么map非常适合。
比如现在你有一个数组,包含了所有的URL,而现在已经有了一个方法用来抓取每个URL内容并解析,那么可以直接在map的第一个参数传入方法名,第二个参数传入URL数组。
from multiprocessing import Pool
import requests
from requests.exceptions import ConnectionError def scrape(url):
try:
print requests.get(url)
except ConnectionError:
print 'Error Occured ', url
finally:
print 'URL ', url, ' Scraped' if __name__ == '__main__':
pool = Pool(processes=3)
urls = [
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'http://xxxyxxx.net'
]
pool.map(scrape, urls)
python下的多线程与多进程的更多相关文章
- python分别使用多线程和多进程获取所有股票实时数据
python分别使用多线程和多进程获取所有股票实时数据 前一天简单介绍了python怎样获取历史数据和实时分笔数据,那么如果要获取所有上市公司的实时分笔数据,应该怎么做呢? 肯定有人想的是,用一个 ...
- python爬虫之多线程、多进程+代码示例
python爬虫之多线程.多进程 使用多进程.多线程编写爬虫的代码能有效的提高爬虫爬取目标网站的效率. 一.什么是进程和线程 引用廖雪峰的官方网站关于进程和线程的讲解: 进程:对于操作系统来说,一个任 ...
- python中的多线程和多进程
一.简单理解一下线程和进程 一个进程中可有多个线程,线程之间可共享内存,进程间却是相互独立的.打比方就是,进程是火车,线程是火车厢,车厢内人员可以流动(数据共享) 二.python中的多线程和多进程 ...
- 第十章:Python高级编程-多线程、多进程和线程池编程
第十章:Python高级编程-多线程.多进程和线程池编程 Python3高级核心技术97讲 笔记 目录 第十章:Python高级编程-多线程.多进程和线程池编程 10.1 Python中的GIL 10 ...
- Python系列之多线程、多进程
线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程. Python的标准库提供 ...
- python之路-----多线程与多进程
一.进程和线程的概念 1.进程(最小的资源单位): 进程:就是一个程序在一个数据集上的一次动态执行过程.进程一般由程序.数据集.进程控制块三部分组成. 程序:我们编写的程序用来描述进程要完成哪些功能以 ...
- python基础之多线程与多进程(二)
上课笔记整理: 守护线程的作用,起到监听的作用 一个函数连接数据库 一个做守护线程,监听日志 两个线程同时取一个数据 线程---->线程安全---->线程同时进行操作数据. IO操作--- ...
- python基础之多线程与多进程(一)
并发编程? 1.为什么要有操作系统? 操作系统,位于底层硬件与应用软件之间 工作方式:向下管理硬件,向上提供接口 2.多道技术? 不断切换程序. 操作系统进程切换: 1.出现IO操作 2.固定时间 进 ...
- Python之threading多线程,多进程
1.threading模块是Python里面常用的线程模块,多线程处理任务对于提升效率非常重要,先说一下线程和进程的各种区别,如图 概括起来就是 IO密集型(不用CPU) 多线程计算密集型(用CPU) ...
- python 16篇 多线程和多进程
1.概念 线程.进程 进程 一个程序,它是一组资源的集合 一个进程里面默认是有一个线程的,主线程 多进程是可以利用多核cpu的线程 最小的执行单位 线程和线程之间是互相独立的 主线程等待子线程执行结束 ...
随机推荐
- 像 Mysql 和 MongoDB 这种大型软件在设计上都是精益求精的,它们为什么选择B树,B+树这些数据结构?
为什么 MongoDB (索引)使用B-树而 Mysql 使用 B+树? B 树与 B+ 树,其比较大的特点是:B 树对于特定记录的查询,其时间复杂度更低.而 B+ 树对于范围查询则更加方便,另外 B ...
- Angular Material 18+ 高级教程 – CDK Scrolling
Angular CDK 的意义 经过之前两篇文章 CDK Portal 和 CDK Layout の Breakpoints,我相信大家已经悟到了 CDK 的意义. CDK 有 3 个方向: 包装 B ...
- 为什么我觉得需要熟悉vim使用,难道仅仅是为了耍酷?
实例说话: 使用vscode保存,有报提示信息,可以以超级用户身份重试,于是我授权root给vscode软件,却还提示失败! 而实际上,我使用cat命令发现已经写入成功了 终端内使用cat这条shel ...
- 基于图扑 HT for Web 实现的昼夜切换场景应用
图扑软件 HT 的案例中有许多白天黑夜效果.这种效果在各类不同的项目中得到了广泛的应用和认可. 白天黑夜效果是视觉设计和交互设计中常见的一种手法.通过细致巧妙地调整色彩.亮度.对比度等视觉参数,即可成 ...
- vsphere8.0 VCenter部署
一.vCenter Server 介绍 vCenter Server是VMware提供的一种集中管理平台,用于管理和监控虚拟化环境中的虚拟机.主机.存储和网络等资源.它提供了一套功能强大的工具和界面, ...
- LeetCode 1397. Find All Good Strings 找到所有好字符串 (数位DP+KMP)
好题- 就是比平时的 hard 难了一些-- 虽然猜出是数位DP了-不过比我之前做的题,好像多了一维,印象中都是一维记录之前状态就够了--然后就没做出-- 至于 KMP 的应用更是神奇,虽然掌握的 k ...
- 40. diff 的新旧节点数组如何比较
根据唯一标识符key值,把新旧的节点比较,不同就更新到新节点,相同就复用就节点,然后生成新的 Vnode :
- 0608-nn和autograd的区别
0608-nn和autograd的区别 目录 一.nn 和 autograd 的区别 二.Function 和 Module 在实际中使用的情况 pytorch完整教程目录:https://www.c ...
- day08-数据类型拓展及面试题
数据类型拓展及面试题 整数拓展----进制 //整数拓展----进制 int i=10;//十进制 不能以0开头,0~9 int i1=0b11;//二进制:0 ...
- HTB打靶记录-Cicada
Nmap Scan nmap扫描一下ip nmap -sT -sV -O -Pn 10.10.11.35 Nmap scan report for 10.10.11.35 Host is up (0. ...