Alembic迁移脚本冲突的智能检测与优雅合并之道
title: Alembic迁移脚本冲突的智能检测与优雅合并之道
date: 2025/05/12 13:10:27
updated: 2025/05/12 13:10:27
author: cmdragon
excerpt:
Alembic迁移脚本冲突检测与合并方案主要解决团队协作中的迁移脚本冲突问题。冲突场景包括并行开发、分支合并和环境差异。通过自动化检测脚本check_migration_conflicts.py可识别多个头版本。手动合并流程包括确定基准版本、创建合并分支和编辑迁移文件。合并后通过测试用例验证迁移的兼容性,确保升级和回滚的一致性。常见报错如“Multiple head revisions”和“Failed to alter column”提供了具体的解决方案,确保迁移过程顺利进行。
categories:
- 后端开发
- FastAPI
tags:
- Alembic
- 数据库迁移
- 冲突检测
- 脚本合并
- 自动化测试
- 版本控制
- SQLAlchemy

扫描二维码
关注或者微信搜一搜:编程智域 前端至全栈交流与成长
探索数千个预构建的 AI 应用,开启你的下一个伟大创意:https://tools.cmdragon.cn/
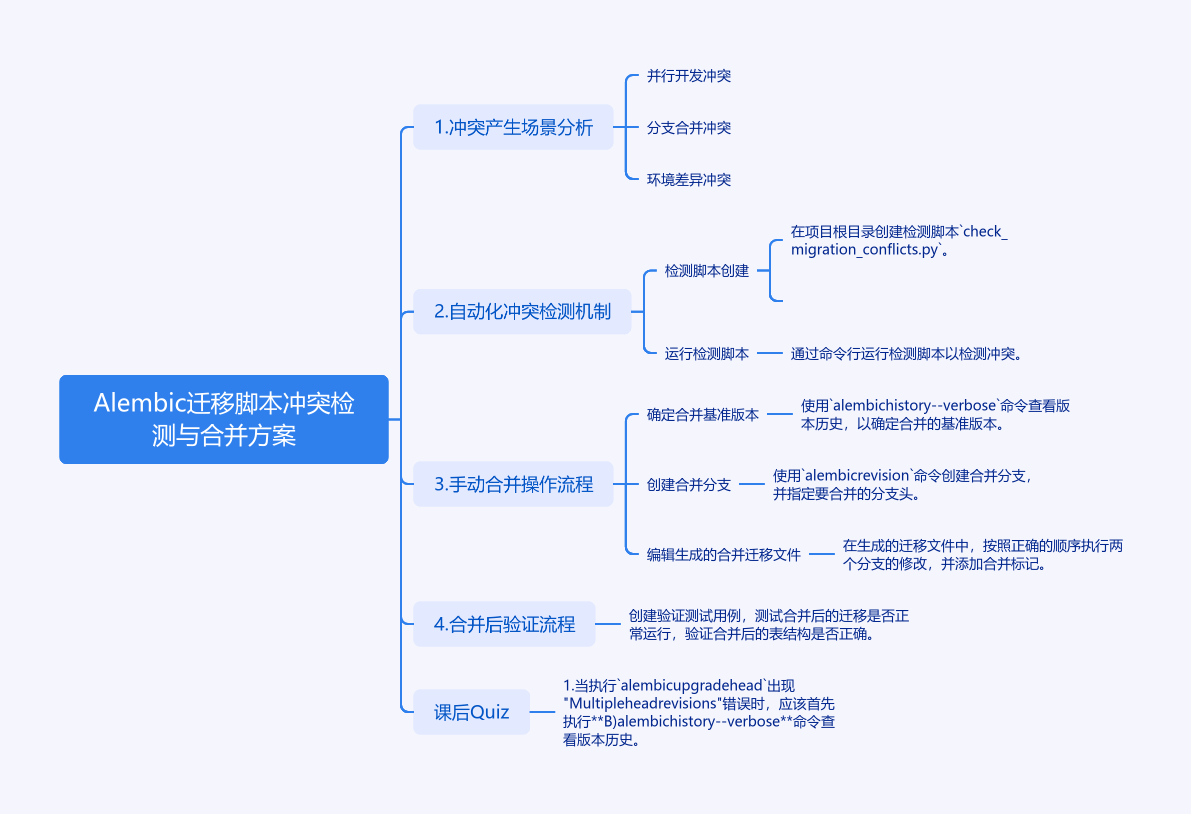
1. Alembic迁移脚本冲突检测与合并方案
1.1 冲突产生场景分析
当团队多人协作开发时,可能出现以下典型冲突场景:
- 并行开发冲突:开发者A和B同时从版本
a1b2c3d4创建新迁移 - 分支合并冲突:不同Git分支中的迁移脚本在合并时产生版本顺序矛盾
- 环境差异冲突:测试环境与生产环境的数据库版本不一致时执行迁移
1.2 自动化冲突检测机制
在项目根目录创建检测脚本check_migration_conflicts.py:
# check_migration_conflicts.py
from alembic.config import Config
from alembic.script import ScriptDirectory
def detect_conflicts():
config = Config("alembic.ini")
scripts = ScriptDirectory.from_config(config)
# 获取当前分支的所有版本
heads = scripts.get_heads()
if len(heads) > 1:
print(f"️ 检测到多个头版本:{heads}")
# 可视化显示分支结构
for revision in heads:
script = scripts.get_revision(revision)
print(f"分支 {revision}:")
for rev in script.iterate_revisions(script.down_revision, False):
print(f" ← {rev.revision}")
else:
print(" 无版本冲突")
if __name__ == "__main__":
detect_conflicts()
运行检测脚本:
python check_migration_conflicts.py
1.3 手动合并操作流程
当检测到冲突时,按以下步骤处理:
步骤1:确定合并基准版本
alembic history --verbose
步骤2:创建合并分支
alembic revision -m "merge_branch" --head a1b2c3d4,b5e6f7g8
步骤3:编辑生成的合并迁移文件
# migrations/versions/xxxx_merge_branch.py
def upgrade():
# 按正确顺序执行两个分支的修改
op.execute("ALTER TABLE users ADD COLUMN merged_flag BOOLEAN")
op.alter_column('posts', 'content_type',
existing_type=sa.VARCHAR(length=50),
nullable=False)
# 添加合并标记
op.create_table(
'migration_merge_records',
sa.Column('id', sa.Integer, primary_key=True),
sa.Column('merged_version', sa.String(32))
)
1.4 合并后验证流程
创建验证测试用例tests/test_merged_migrations.py:
import pytest
from alembic.command import upgrade, downgrade
from alembic.config import Config
@pytest.fixture
def alembic_config():
return Config("alembic.ini")
def test_merged_migration_upgrade(alembic_config):
try:
upgrade(alembic_config, "head")
# 验证合并后的表结构
with alembic_config.connection() as conn:
result = conn.execute("SHOW TABLES LIKE 'migration_merge_records'")
assert result.fetchone() is not None
finally:
downgrade(alembic_config, "base")
def test_conflict_resolution_consistency(alembic_config):
upgrade(alembic_config, "head")
downgrade(alembic_config, "-1")
upgrade(alembic_config, "+1")
# 验证回滚后重新升级是否一致
with alembic_config.connection() as conn:
result = conn.execute("DESC users")
columns = [row[0] for row in result]
assert 'merged_flag' in columns
课后Quiz
当执行
alembic upgrade head出现"Multiple head revisions"错误时,应该首先执行什么命令?
A) alembic downgrade base
B) alembic history --verbose
C) alembic merge heads
D) 直接删除迁移文件合并迁移时需要特别注意哪个文件的修改?
A) requirements.txt
B) alembic.ini
C) env.py
D) 合并生成的迁移脚本文件如何验证合并后的迁移脚本兼容性?
A) 直接在生产环境测试
B) 使用自动化测试回滚和重新升级
C) 仅检查代码格式
D) 手动执行SQL语句
答案解析:
- B。需要先通过
alembic history查看版本结构,确定冲突点 - D。合并迁移的核心是正确处理生成的合并脚本
- B。自动化测试能确保迁移的可逆性和一致性
常见报错解决方案
错误1:Multiple head revisions
alembic.util.exc.CommandError: Multiple head revisions are present
➔ 解决方案:
- 执行合并命令:
alembic merge heads - 编辑生成的合并迁移文件
- 测试验证后标记新版本:
alembic stamp head
错误2:Failed to alter column
sqlalchemy.exc.OperationalError: (MySQL Error)无法修改字段类型
➔ 解决方案:
- 检查字段是否包含索引或约束
- 分步执行修改:
op.drop_constraint('fk_post_user', 'posts')
op.alter_column(...)
op.create_foreign_key(...)
错误3:Table already exists after merge
sqlalchemy.exc.ProgrammingError: 表'migration_merge_records'已存在
➔ 解决方案:
- 在合并脚本中添加存在性检查:
if not op.get_bind().engine.dialect.has_table(op.get_bind(), 'migration_merge_records'):
op.create_table(...)
- 使用
op.execute("DROP TABLE IF EXISTS temp_table")清理临时表
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:Alembic迁移脚本冲突的智能检测与优雅合并之道 | cmdragon's Blog
往期文章归档:
- 多数据库迁移的艺术:Alembic在复杂环境中的精妙应用 | cmdragon's Blog
- 数据库事务回滚:FastAPI中的存档与读档大法 | cmdragon's Blog
- Alembic迁移脚本:让数据库变身时间旅行者 | cmdragon's Blog
- 数据库连接池:从银行柜台到代码世界的奇妙旅程 | cmdragon's Blog
- 点赞背后的技术大冒险:分布式事务与SAGA模式 | cmdragon's Blog
- N+1查询:数据库性能的隐形杀手与终极拯救指南 | cmdragon's Blog
- FastAPI与Tortoise-ORM开发的神奇之旅 | cmdragon's Blog
- DDD分层设计与异步职责划分:让你的代码不再“异步”混乱 | cmdragon's Blog
- 异步数据库事务锁:电商库存扣减的防超卖秘籍 | cmdragon's Blog
- FastAPI中的复杂查询与原子更新指南 | cmdragon's Blog
- 深入解析Tortoise-ORM关系型字段与异步查询 | cmdragon's Blog
- FastAPI与Tortoise-ORM模型配置及aerich迁移工具 | cmdragon's Blog
- 异步IO与Tortoise-ORM的数据库 | cmdragon's Blog
- FastAPI数据库连接池配置与监控 | cmdragon's Blog
- 分布式事务在点赞功能中的实现 | cmdragon's Blog
- Tortoise-ORM级联查询与预加载性能优化 | cmdragon's Blog
- 使用Tortoise-ORM和FastAPI构建评论系统 | cmdragon's Blog
- 分层架构在博客评论功能中的应用与实现 | cmdragon's Blog
- 深入解析事务基础与原子操作原理 | cmdragon's Blog
- 掌握Tortoise-ORM高级异步查询技巧 | cmdragon's Blog
- FastAPI与Tortoise-ORM实现关系型数据库关联 | cmdragon's Blog
- Tortoise-ORM与FastAPI集成:异步模型定义与实践 | cmdragon's Blog
- 异步编程与Tortoise-ORM框架 | cmdragon's Blog
- FastAPI数据库集成与事务管理 | cmdragon's Blog
- FastAPI与SQLAlchemy数据库集成 | cmdragon's Blog
- FastAPI与SQLAlchemy数据库集成与CRUD操作 | cmdragon's Blog
- FastAPI与SQLAlchemy同步数据库集成 | cmdragon's Blog
- SQLAlchemy 核心概念与同步引擎配置详解 | cmdragon's Blog
- FastAPI依赖注入性能优化策略 | cmdragon's Blog
- FastAPI安全认证中的依赖组合 | cmdragon's Blog
- FastAPI依赖注入系统及调试技巧 | cmdragon's Blog
- FastAPI依赖覆盖与测试环境模拟 | cmdragon's Blog
- FastAPI中的依赖注入与数据库事务管理 | cmdragon's Blog
- FastAPI依赖注入实践:工厂模式与实例复用的优化策略 | cmdragon's Blog
- XML Sitemap
Alembic迁移脚本冲突的智能检测与优雅合并之道的更多相关文章
- flask 使用Flask-Migrate迁移数据库(创建迁移环境、生成迁移脚本、更新数据库)
使用Flask-Migrate迁移数据库 在开发时,以删除表再重建的方式更新数据库简单直接,但明显的缺陷是会丢掉数据库中的所有数据.在生产环境下,没有人想把数据都删除掉,这时需要使用数据库迁移工具来完 ...
- Oracle冷备迁移脚本(文件系统)
Oracle冷备迁移脚本(文件系统) 两个脚本: 配置文件生成脚本dbinfo.sh 网络拷贝到目标服务器的脚本cpdb16.sh 1. 配置文件生成脚本 #!/bin/bash #Usage: cr ...
- python脚本实现集群检测和管理
python脚本实现集群检测和管理 场景是这样的:一个生产机房,会有很多的测试机器和生产机器(也就是30台左右吧),由于管理较为混乱导致了哪台机器有人用.哪台机器没人用都不清楚,从而产生了一个想法-- ...
- 摹客iDoc的PS插件全新改版!—— 智能检测不对应的设计稿
一.简洁美观——iDoc的PS插件全新界面 iDoc对PS插件的界面进行了全新设计,无论是登录.上传.还是设置界面,都变得更精致.简洁美观,功能分布也非常明确,是一款轻巧且实用的小插件. 二.同步上传 ...
- Python智能检测编码并转码
#安装包工具 $pip3 install chardet #直接打开文件,中文显示乱码 >>> import chardet >>> f = open('test. ...
- django迁移脚本
执行migrate报错的解决办法: 想知道migrate为什么报错,需要先了解migrate到底做了什么事情 migrate做了什么事情? 1.将相关的迁移脚本翻译成sql语句,然后在数据库中执行 2 ...
- (转) 技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道
技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道 原创 2016-09-21 钟巧勇 深度学习大讲堂 点击上方“深度学习大讲堂”可订阅哦!深度学习大讲堂是高质量原创内容平台,邀请 ...
- 利用SHELL脚本实现文件完整性检测程序(1.2版更新)
一..开发背景 因时势所逼,需要对服务器的文件系统实行监控.虽然linux下有不少入侵检测和防窜改系统,但都比较麻烦,用起来也不是很称手.自己琢磨着也不需要什么多复杂的功能,写个脚本应该就可以满足基本 ...
- SQLServer的Login迁移脚本
背景:公司的数据由SQLServer2008 R2升级至SQLServer2012,并配置了AlwaysOn,本脚本用于将主节点的Login迁移至辅助节点. 1.在主节点执行以下脚本创建存储过程: U ...
- PHP性能调优,PHP慢日志---PHP脚本执行效率性能检测之WebGrind的使用
如何一睹webgrind这个神奇的php性能检测工具神奇呢? 废话不多说首先webgrind这个性能检测是需要xdebug来配合,因为webgrind 进行性能检测分析就是通过xdebug生成的日志文 ...
随机推荐
- 『Python底层原理』--GIL对多线程的影响
在 Python 多线程编程中,全局解释器锁(Global Interpreter Lock,简称 GIL)是一个绕不开的话题. GIL是CPython解释器的一个机制,它限制了同一时刻只有一个线程可 ...
- javascript 陀螺仪加摄像头可以玩出AR效果
原文链接:https://blog.jijian.link/2020-09-08/js-ar/ 重要事情说三遍 此文章中的API接口,必须放在 https 协议下测试!浏览器APP必须开启摄像头权限! ...
- vue2中如何使用组合式API和vueuse工具包
vue2中如何使用组合式API和vueuse工具包 1. 安装 @vue/composition-api 依赖包 yarn add @vue/composition-api # 或 npm insta ...
- golang实现三重DES加密解密
DES DES(Data Encryption)是1977年美国联邦信息处理标准(FIPS)中所采用的一种对称密码(FIPS46-3),一直以来被美国及其他国家的政府和银行等广泛使用.随着计算机的进步 ...
- MAMP PRO教程
简单使用 第一步 创建新主机,按主机表左下角的"+"按钮. 第二步 配置域名和项目地址 第三步 选择你要使用的web服务器 第四步 配置URL重写规则 第五步 检查端口号 第六步 ...
- 栈的应用(后进先出 LIFO)--括号匹配问题
博客地址:https://www.cnblogs.com/zylyehuo/ # -*- coding: utf-8 -*- class Stack: def __init__(self): self ...
- MySQL-InnoDB行锁
InnoDB的锁类型 InnoDB存储引擎支持行锁,锁类型有两种: 共享锁(S锁) 排他锁(X锁) S和S不互斥,其他均互斥. 除了这两种锁以外,innodb还支持一种锁,叫做意向锁. 那么什么是意向 ...
- 【Unity】改变游戏运行时Window的窗口标题
[Unity]改变游戏运行时Window的窗口标题 零.需求 Unity打包好的Windows程序,启动后如何更改窗口标题?因为看着英文的感觉不太好,故有此想法.什么?你说为啥不改项目产品名?产品名会 ...
- macOS 字体文件所在路径
目录 用户字体路径/Library/Fonts 系统字体路径/System/Library/Fonts macOS font 也就是字体文件,有2个可用路径 这里以 macOS Monterey 版本 ...
- 学习unigui【17】-数据集和JSON互相转换-DataSetConverter4D 开源项目
学习unigui过程中,出现使用json和fdquery等数据交换的太多场景要求. 感谢开源DataSetConverter4D提供轮子. 直接抄demo: {Convert DataSet to J ...