HashMap集合--基本操作流程的源码可视化
本文主要包含:HashMap 插入过程、扩容过程、查询过程和删除过程的源码可视化
1. 操作流程
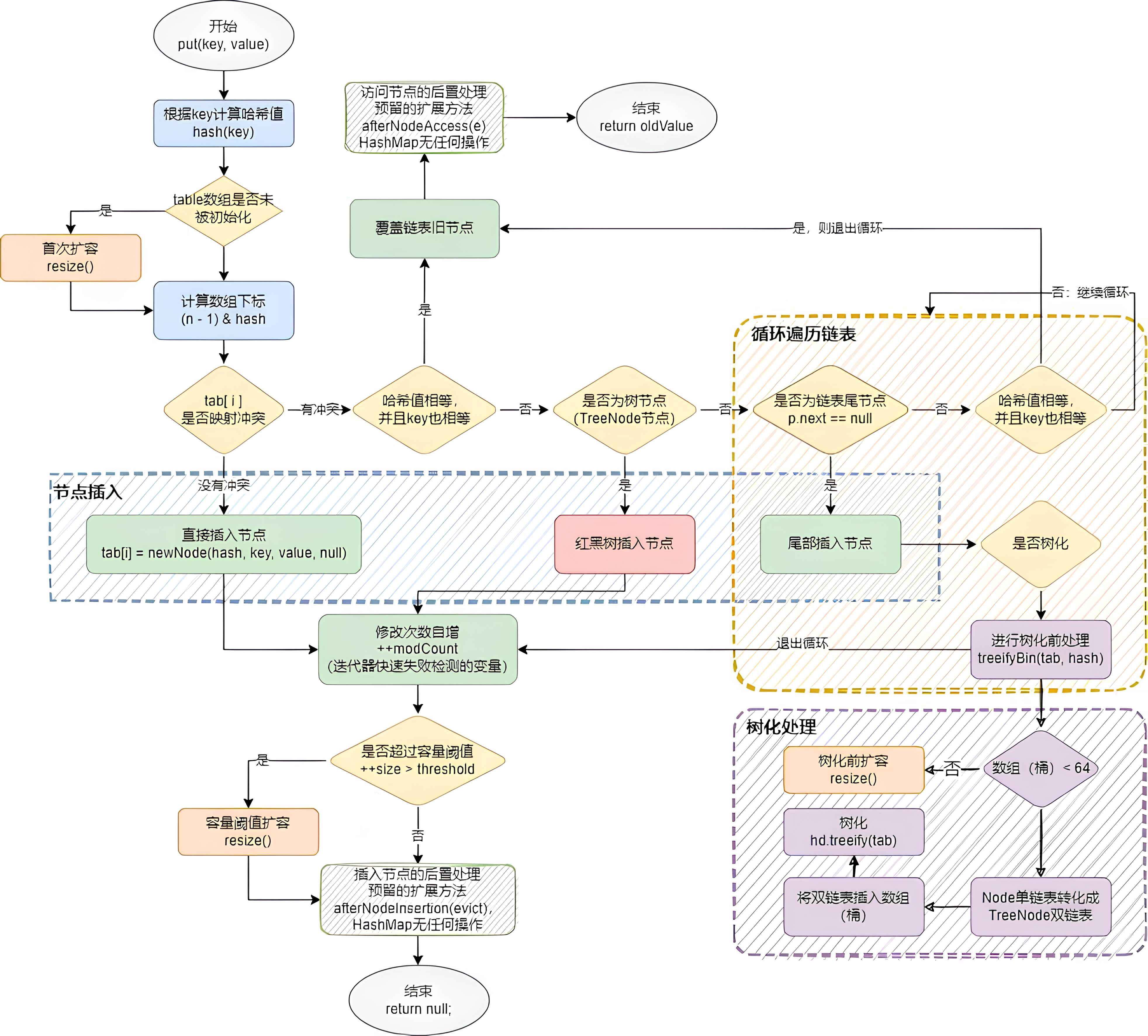
1.1. 插入过程(put(K key, V value))
插入流程主要涉及四种操作:扩容(首层扩容和阈值扩容)、单节点插入(无哈希冲突的情况)、链表遍历插入(冲突节点不超8个的情况)、红黑树插入。
插入节点的全流程图:
1.2. 扩容过程(resize())
扩容条件、扩容涉及到的链表挂载、链表树化、树转链表等等,都在前一篇四次扩容的文章中讲到,渐进式的学习HashMap扩容。
HashMap扩容源码可视化
文章链接:https://mp.weixin.qq.com/s/J3kU51hb-GcM4Rsp7QCIFw
视频链接:https://www.bilibili.com/video/BV1wM3KzaE3d/
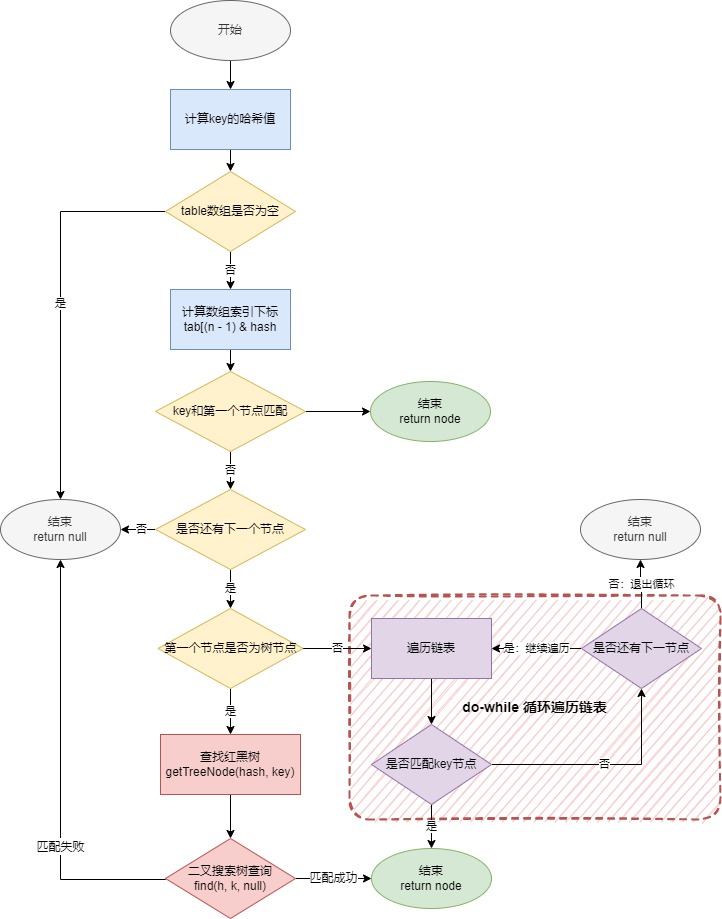
1.3. 查询过程(get(Object key))
空表或
key == null:立即返回null(nullkey 存储在索引 0)。计算
hash、下标i遍历
如果
table[i]为单链表,逐节点比较hash与key.equals;如果为红黑树,调用
TreeNode的getTreeNode,按树结构快速查找(对数复杂度)。
查找元素全流程图:
1.4. 删除过程(remove(Object key))
最后将展示单链表的节点删除和红黑树节点的删除可视化过程。
计算
hash、下标i。定位到槽位的链表或树,找到目标节点。
单链表:直接断链跳过;红黑树:调用
removeTreeNode完成删除。size--,更新modCount,返回被删节点的值。
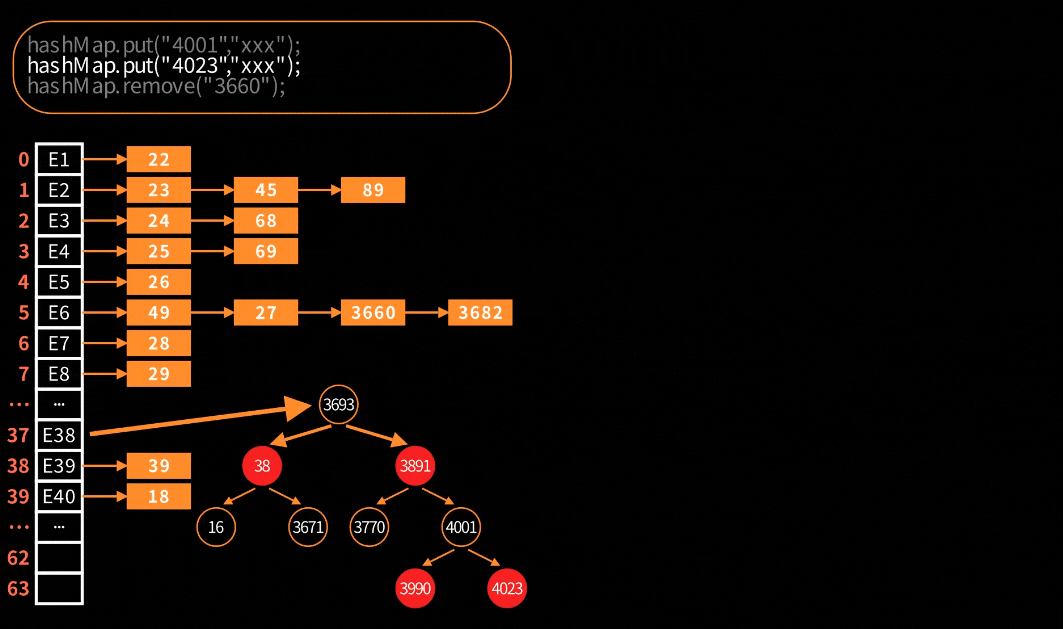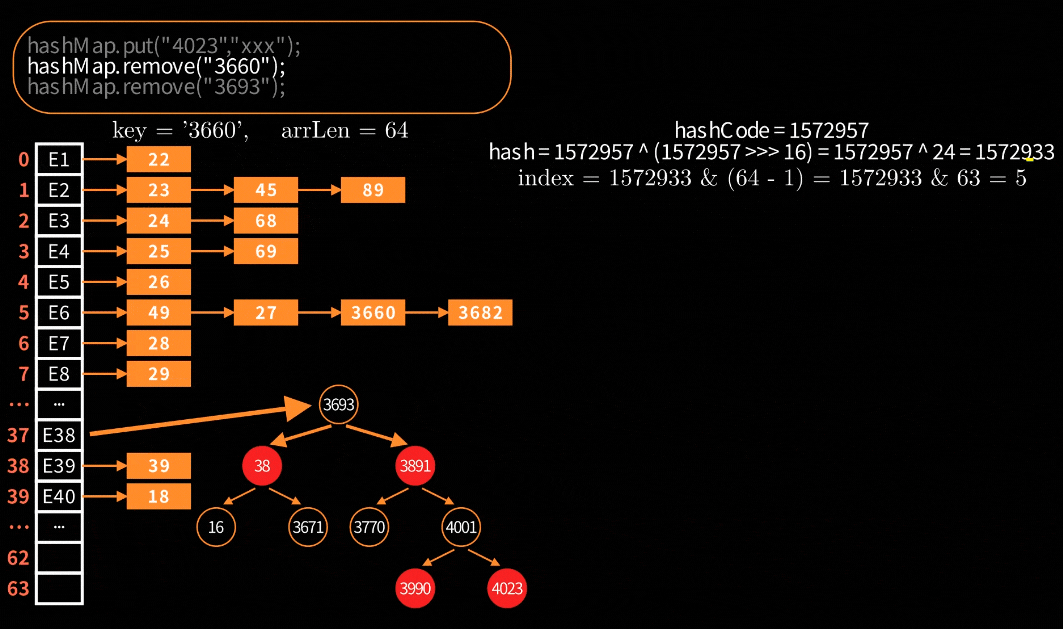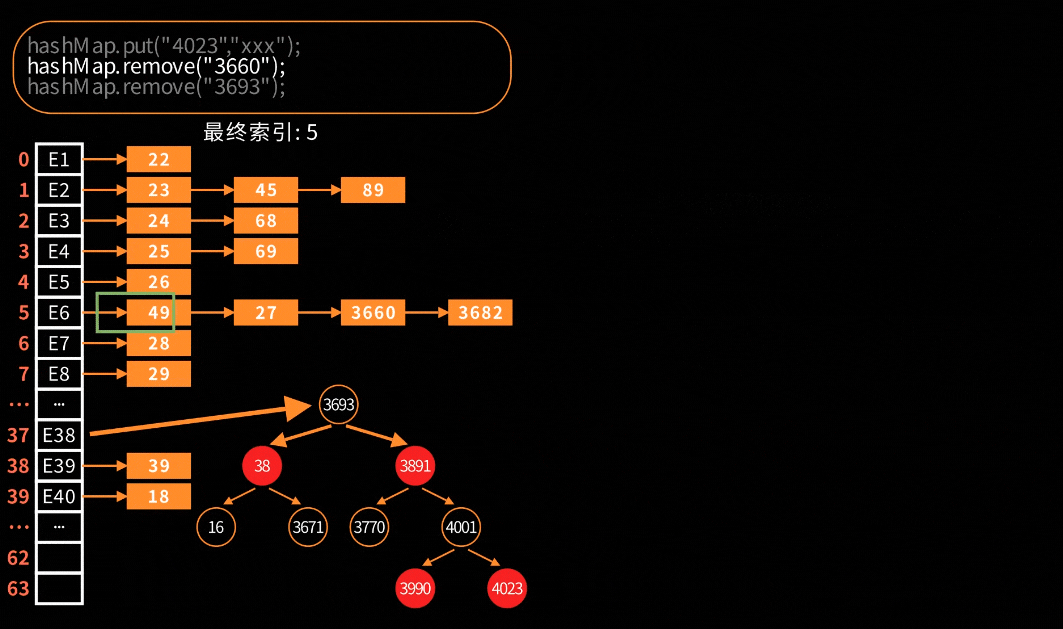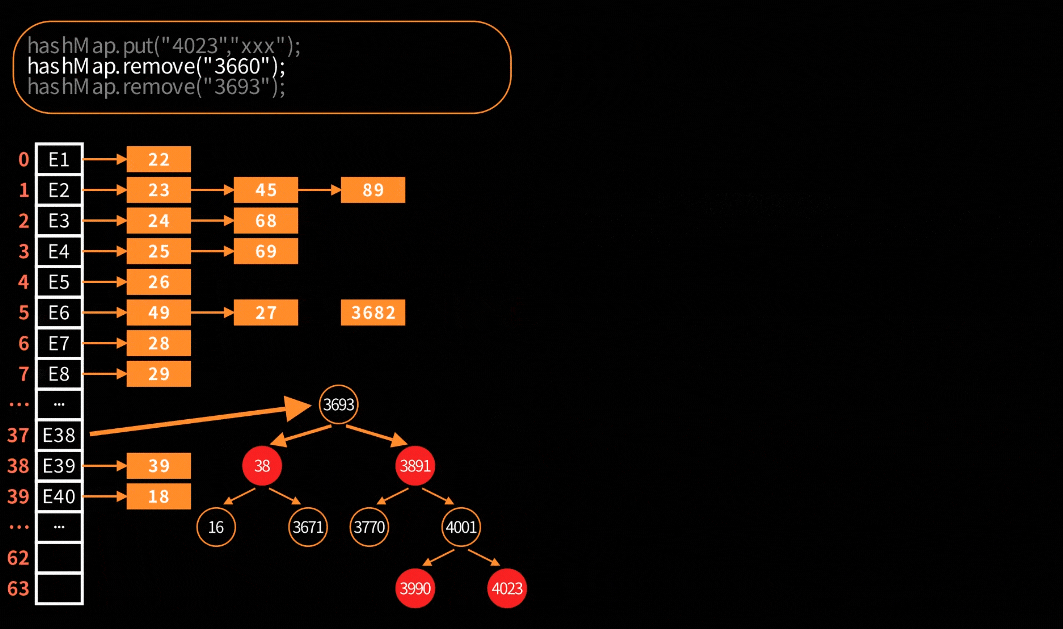
删除链表节点
跟普通链表删除节点一样简单,下面直接通过动图来理解
删除红黑树节点
对于链表的删除处理是很简单很好理解,但是对于红黑树的删除就会比较复杂。在HashMap中,红黑树节点删除的可视化:
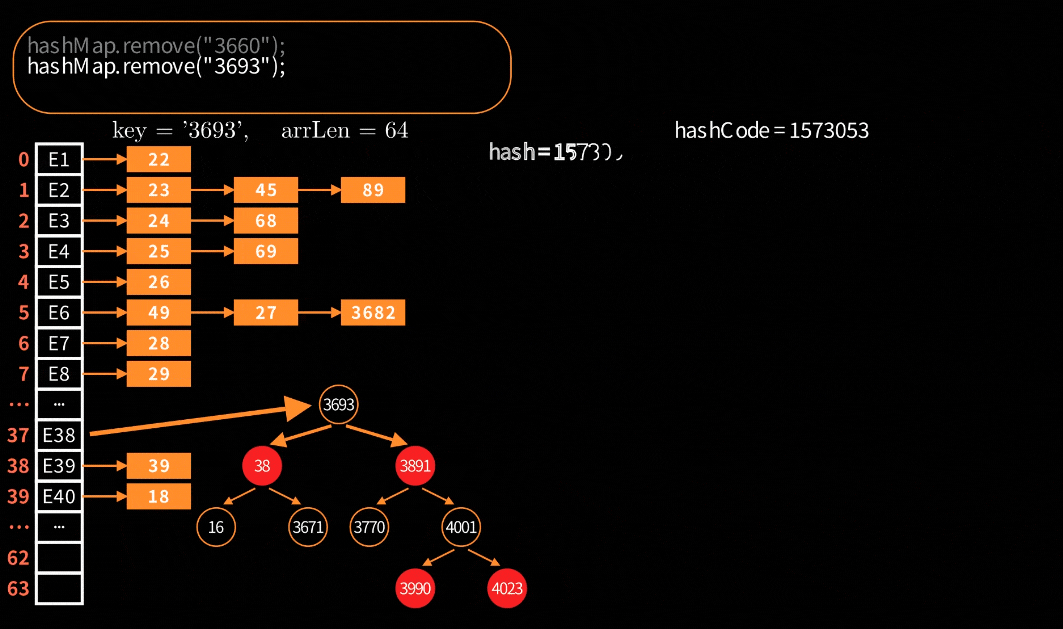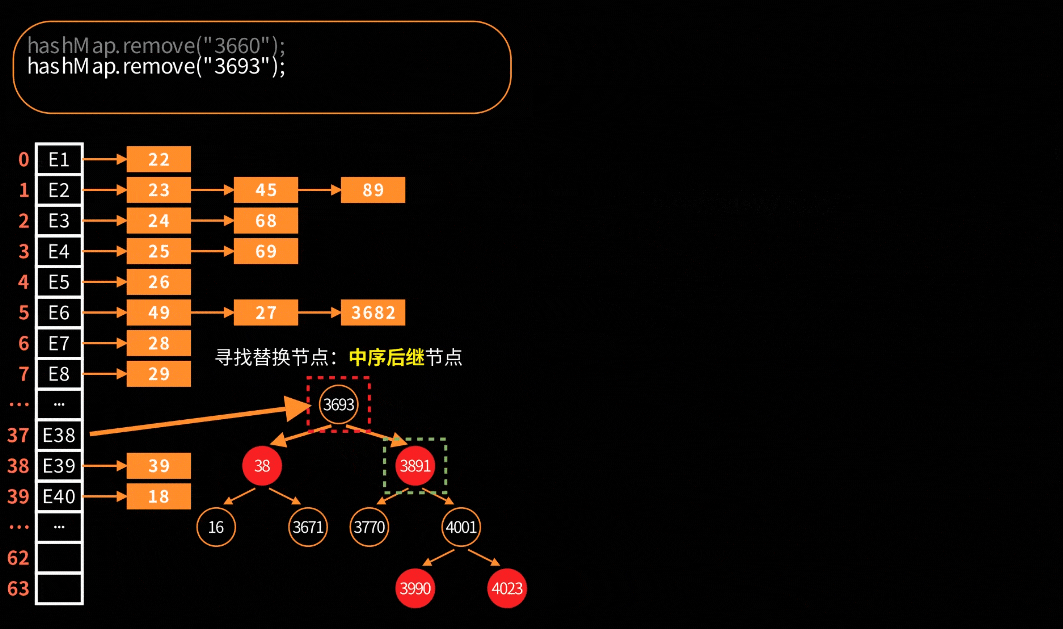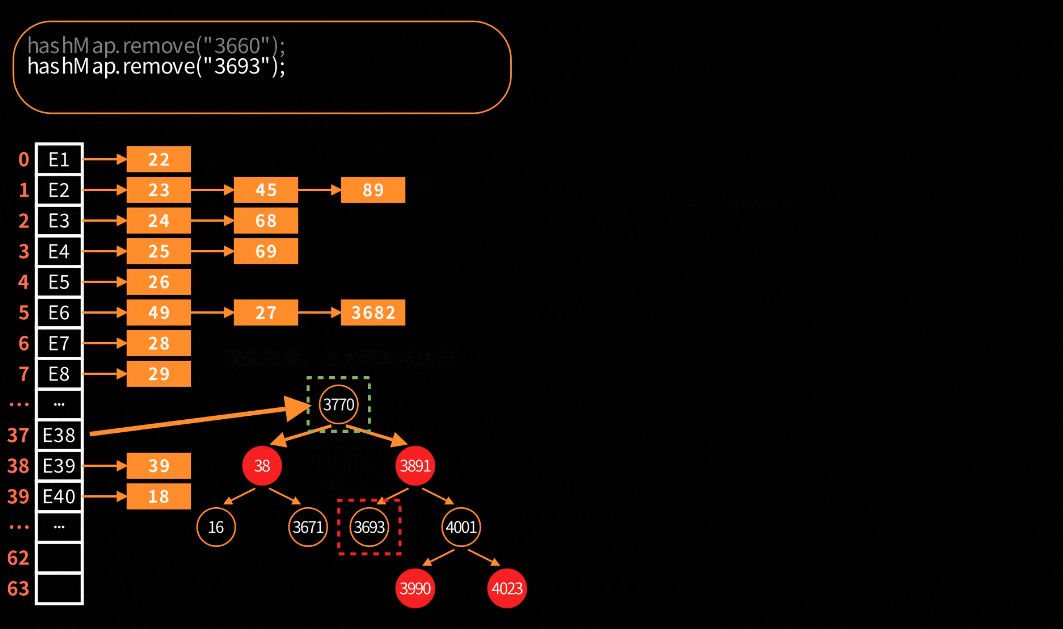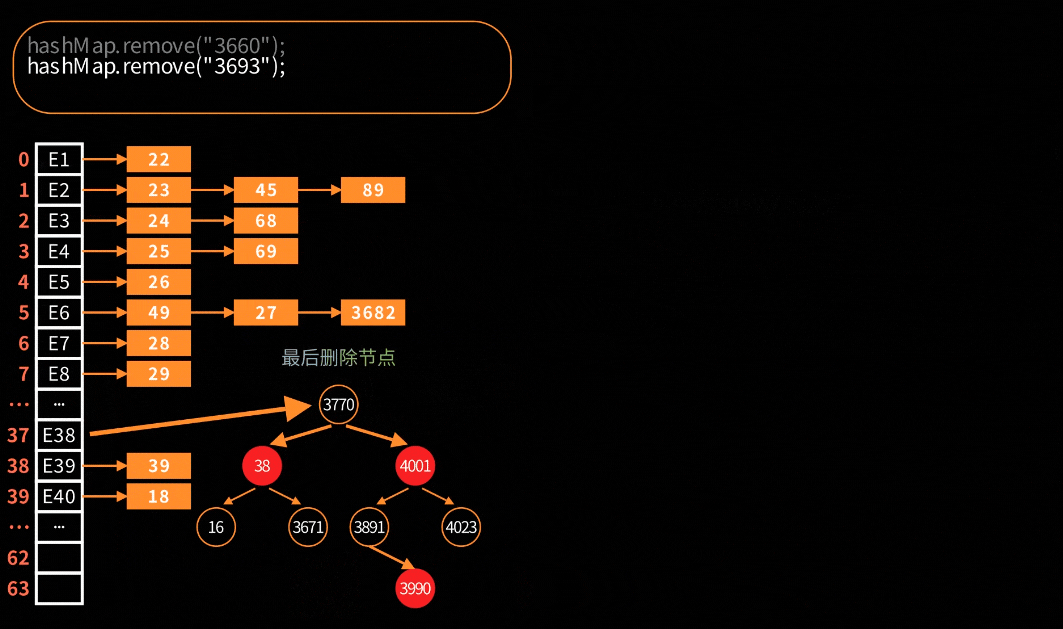
关键步骤大致分为四步:寻找替换节点、进入待删除状态、红黑树平衡调整和最终删除节点。
最主要的两步源码如下,其次就是红黑树数据结构删除过程的理解:
寻找替换:寻找中序后继节点作为替换节点。比如:红黑树左中右序为1、2、3、4,删除了2节点,那么就找3节点作为替换节点;如果删除3节点,那么就找4节点作为替换。对应的源代码如下
if (pl != null && pr != null) {
// 如果左右都不为空,找中序的后继节点替换,(右子树最靠左的节点)
TreeNode<K,V> s = pr, sl;
while ((sl = s.left) != null)
s = sl;
...
}
删除黑节点树平衡:
删除的主要源码如下,已为每一行源码附上注释。
// map: 当前所在的 HashMap 实例
// tab: 哈希表数组(即 table)
// movable=true
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {
int n;
// 如果表为 null 或长度为 0,直接返回(无操作)
if (tab == null || (n = tab.length) == 0)
return;
// 用哈希值定位当前节点所在的桶 index
int index = (n - 1) & hash;
// 获取根节点
TreeNode<K,V> first = (TreeNode<K,V>)tab[index], root = first, rl;
// 从链表中断开当前节点(this),红黑树同时是双向链表这点必须知道,所以才有维护链表的操作
TreeNode<K,V> succ = (TreeNode<K,V>)next, pred = prev;
if (pred == null)
tab[index] = first = succ;
else
pred.next = succ;
if (succ != null)
succ.prev = pred;
// 如果断链后没有剩余节点(即只有当前一个节点),直接返回
if (first == null)
return;
if (root.parent != null)
root = root.root();
if (root == null
|| (movable
&& (root.right == null
|| (rl = root.left) == null
|| rl.left == null))) {
tab[index] = first.untreeify(map); // too small
return;
}
// 红黑树删除操作
TreeNode<K,V> p = this, pl = left, pr = right, replacement;
// 处理删除节点p 同时有左右子节点的情况
if (pl != null && pr != null) {
// 如果左右都不为空,找中序的后继替换,(右子树最靠左的节点)
TreeNode<K,V> s = pr, sl;
while ((sl = s.left) != null) // find successor
s = sl;
// 节点颜色交换
boolean c = s.red; s.red = p.red; p.red = c; // swap colors
// 交换结构:把后继节点换上来
TreeNode<K,V> sr = s.right;
TreeNode<K,V> pp = p.parent;
// p 是 s 的直接父节点
if (s == pr) {
p.parent = s;
s.right = p;
}
else {
TreeNode<K,V> sp = s.parent;
if ((p.parent = sp) != null) {
if (s == sp.left)
sp.left = p;
else
sp.right = p;
}
if ((s.right = pr) != null)
pr.parent = s;
}
// 调整左子树与父指针:p 的左右清空(它即将被删),s 左右指针都设置好(接替 p)
p.left = null;
if ((p.right = sr) != null)
sr.parent = p;
if ((s.left = pl) != null)
pl.parent = s;
// s 接替 p 成为新的 root 的子节点
if ((s.parent = pp) == null)
root = s;
else if (p == pp.left)
pp.left = s;
else
pp.right = s;
// 设置替换节点
if (sr != null)
replacement = sr;
else
replacement = p;
}
// 处理删除节点p 有一个或没有子节点情况
else if (pl != null)
replacement = pl;
else if (pr != null)
replacement = pr;
else
replacement = p;
// 让 replacement 替换掉 删除节点p 的位置
if (replacement != p) {
TreeNode<K,V> pp = replacement.parent = p.parent;
if (pp == null)
root = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
p.left = p.right = p.parent = null;
}
// 如果删除节点p 是黑节点,需要平衡红黑树
TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement);
// 如果 p 等于 replacement,说明删除的节点是叶子节点,断开叶子节点
if (replacement == p) {
TreeNode<K,V> pp = p.parent;
p.parent = null;
if (pp != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
}
}
// 将新的 root 移动到链表最前(优化访问)
if (movable)
moveRootToFront(tab, r);
}
2. 性能与并发考虑
时间复杂度
| 操作 | 平均时间复杂度 | 最坏时间复杂度 | 备注 |
|---|---|---|---|
get |
O(1) | O(log n) | 红黑树查找最坏 O(log n) |
put |
O(1) | O(log n) | 链表树化后插树最坏 O(log n) |
remove |
O(1) | O(log n) | 红黑树删除维护平衡 O(log n) |
resize |
O(1) | O(n) | 摊销成本后每次插入 O(1) |
| 遍历全部元素 | O(n) | O(n) |
并发风险
HashMap 非线程安全,在多线程无外部同步时可能出现数据丢失或死循环(扩容时环路)。
多线程并发场景推荐使用 ConcurrentHashMap,或者对 HashMap 外层加锁(如 Collections.synchronizedMap,串行效率低)
3. 在 HashMap 中红黑树同时是双向链表?
链表节点(未树化):Node<K,V> 类型,只包含:
Node<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
是 单向链表。
树化节点(TreeNode):扩展自 Node<K,V>,添加了:
TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // 这是额外的双向链表字段
boolean red;
}
是 双向链表 + 红黑树结构。
3.1. 红黑树根节点始终是双向链表的头节点
这里所说的双向链表结构指的是:在同一个桶中的红黑树。
在不同的桶中,红黑树之间是没有联系的,也不存在双向链表。
moveRootToFront 这个方法有两个作用
更新数组桶指向新的根节点
更新根节点为双向链表的头节点,并将旧的根节点作为下一节点接上(就是新的根节点和旧的根节点互换位置)
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
// 获取旧的根节点
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
// 数组桶指向新的根节点
tab[index] = root;
// 断开 root 在原链表中的连接:先取出root上一节点
TreeNode<K,V> rp = root.prev;
// 再将前后节点连接起来,从而断开root 在原链表中的连接
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
// 新的根节点调整为头节点
if (first != null)
first.prev = root;
// 旧的根节点成为头节点的下一节点
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
总的来说,没什么深奥的,就是单链表和双链表的作用区别,为了任意树节点都可以更快的找到上一节点,提高操作效率。
4. 总结
HashMap插入流程、扩容流程、查询流程,以及删除节点时链表和红黑树的处理。对 HashMap 会有一个基本而完整的理解。接下来可以深入学习红黑树数据结构,这是学习HashMap、LinkedHashMap、TreeMap等集合必须掌握的数据结构。

Java集合--HashMap底层原理可视化,秒懂扩容、链化、树化
查看往期设计模式文章的:设计模式
原创不易,觉得还不错的,三连支持:点赞、分享、推荐↓
HashMap集合--基本操作流程的源码可视化的更多相关文章
- List-LinkedList、set集合基础增强底层源码分析
List-LinkedList 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 继上一章继续讲解,上章内容: List-ArreyLlist集合基础增强底层源码分析:https:// ...
- List-ArrayList集合基础增强底层源码分析
List集合基础增强底层源码分析 作者:Stanley 罗昊 [转载请注明出处和署名,谢谢!] 集合分为三个系列,分别为:List.set.map List系列 特点:元素有序可重复 有序指的是元素的 ...
- 【转】HashMap,ArrayMap,SparseArray源码分析及性能对比
HashMap,ArrayMap,SparseArray源码分析及性能对比 jjlanbupt 关注 2016.06.03 20:19* 字数 2165 阅读 7967评论 13喜欢 43 Array ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- 集合之HashMap(含JDK1.8源码分析)
一.前言 之前的List,讲了ArrayList.LinkedList,反映的是两种思想: (1)ArrayList以数组形式实现,顺序插入.查找快,插入.删除较慢 (2)LinkedList以链表形 ...
- [源码解析]HashMap和HashTable的区别(源码分析解读)
前言: 又是一个大好的周末, 可惜今天起来有点晚, 扒开HashMap和HashTable, 看看他们到底有什么区别吧. 先来一段比较拗口的定义: Hashtable 的实例有两个参数影响其性能:初始 ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- HashMap就是这么简单【源码剖析】
前言 声明,本文用得是jdk1.8 前面已经讲了Collection的总览和剖析List集合以及散列表.Map集合.红黑树的基础了: Collection总览 List集合就这么简单[源码剖析] Ma ...
- HashMap 与 ConcrrentHashMap 使用以及源码原理分析
前奏一:HashMap面试中常见问题汇总 HashMap的工作原理是近年来常见的Java面试题,几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和Has ...
随机推荐
- Web前端入门第 24 问:CSS 单位
单位就是那个形容长度大小的东西.比如身高180cm(厘米),cm就是单位. css 也不例外,要描述一个盒子的大小,就必须要用到单位. css 单位根据其作用分为几大类:绝对单位.相对单位.视口单位. ...
- markdown文本编辑器--核心功能(解析和渲染)
开源项目地址 GitHub 开源地址(YtyMark-java) 欢迎提交 PR.Issue.Star ️! 1. 简述 YtyMark-java项目分为两大模块: UI界面(ytyedit-mark ...
- Spring基于XML的事务管理器DataSourceTransactionManager
Spring基于XML的事务管理器DataSourceTransactionManager 源码 代码测试 pom.xml <?xml version="1.0" encod ...
- 使用 Go-Spring 构建最小 Web API
前言 Go 语言以简单著称,一个很明显的例子就是只需要很少的代码即可实现一个最小的 Web API .Go-Spring 融合了 Go 简单和 Spring 自动配置的优点.本文通过几个实现最小 We ...
- 改进NeteaseCloudMusicGtk4:添加移除歌曲按钮
之前已经发了一篇博客简述了如何阅读这个项目,尽管这个项目已经开源很久了,但我找了很久都没有找到怎么从播放列表移除歌曲,那就自己动手实现,再提个 PR 吧. 运行起来应用后通过 Inspector(Ct ...
- 【BUG】Hexo|GET _MG_0001.JPG 404 (Not Found),hexo博客搭建过程图片路径正确却找不到图片
我的问题 我查了好多资料,结果原因是图片名称开头是_则该文件会被忽略...我注意到网上并没有提到这个问题,遂补了一下这篇博客并且汇总了我找到的所有解决办法. 具体检查方式: hexo生成一下静态资源: ...
- 【工具】VS Code Counter|除了Gitstats之外的Github一键统计代码行数工具
需求: 1)被要求统计代码行数: 2)不想打开Linux,懒得下载Windows版本GitStats: 3)打开了Linux但也不记得find命令行怎么用: 4)打开了Linux,装好了Gitstat ...
- [java与https]第一篇、证书杂谈
一.算法.密钥(对).证书.证书库 令狐冲是个马场老板,这天,他接到店里伙计电话,说有人已经签了租马合同,准备到马场提马,,他二话不说,突突突就去了,到了之后,发现不认识租客. 令狐冲说,你把你租马合 ...
- .NET + AI | Semantic Kernel vs Microsoft.Extensions.AI
Microsoft.Extensions.AI 在 .NET AI 应用架构中的定位示意图:应用程序通过 Microsoft.Extensions.AI 调用下层各种 AI 服务(如 Semantic ...
- DrissionPage采集抖音搜索结果详情信息及各视频的评论详情
目前正在做的一个项目,因为涉及到社交媒体的相关数据,在采集douyin数据的时候接触到了DrissionPage这个库,相对于该帖子发布的时间来说,该库的时效性较新,且目前在数据采集领域也属于较为新颖 ...