Django模型查询与性能调优:告别N+1问题
一、查询基础
QuerySet 详解
Django 中通过模型类的 Manager 构建 QuerySet 来检索数据库对象,其核心特性包括:
- 代表数据库中对象的集合
- 可通过过滤器缩小查询范围
- 具有惰性执行特性(仅在需要结果时才执行 SQL)
常用过滤器
all():返回所有对象filter(**kwargs):返回满足条件的对象exclude(** kwargs):返回不满足条件的对象get(**kwargs):返回单个匹配对象(无匹配或多匹配会抛异常)- 切片
# 切片操作示例:返回前5个对象(LIMIT 5)
Book.objects.all()[:5]
一对多关联查询
假设一个作者可以写多本书,但每本书只能属于一个作者。
from django.db import models
class Author(models.Model):
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
def __str__(self):
return f"{self.first_name} {self.last_name}"
class Book(models.Model):
title = models.CharField(max_length=100)
publication_date = models.DateField()
# 外键关联Author,级联删除,反向查询名为books
author = models.ForeignKey(
Author,
on_delete=models.CASCADE,
related_name='books'
)
def __str__(self):
return self.title
正向查询(通过外键属性访问)
b = Book.objects.get(id=2)
b.author # 获取关联的Blog对象,查询数据库
b.author = some_body # 设置关联对象
b.save() # 保存更改
使用 select_related() 预加载关联对象,避免额外查询
b = Book.objects.select_related().get(id=2)
print(b.author) # 已预加载到缓存,使用缓存,不查询数据库
反向查询(通过关联管理器)
# 未定义related_name, 默认Manager名称为:<模型名称小写>_set
a = Author.objects.get(id=1)
a.book_set.all() # 返回所有关联的Book
# 定义了related_name='books'
a.books.all() # 更直观的访问方式
关联对象操作方法如下。所有 “反向” 操作对数据库都是立刻生效,保存到数据库。
add(obj1, obj2):添加关联对象create(**kwargs):创建并关联新对象remove(obj1, obj2):移除关联对象clear():清空所有关联set(objs):替换关联集合
a = Author.objects.get(id=1)
a.books.set([b1, b2]) # b1 和 b2 都是 Book 实例
多对多关联查询
假设一个作者可以写多本书,一本书也可以有多个作者。
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=100)
email = models.EmailField()
def __str__(self):
return self.name
class Book(models.Model):
title = models.CharField(max_length=200)
publication_date = models.DateField()
# 多对多关联Author
authors = models.ManyToManyField(Author, related_name='books')
def __str__(self):
return self.title
正向与反向查询示例
# 正向查询
b = Book.objects.get(id=3)
b.authors.all() # 获取所有关联的Author
b.authors.count()
b.authors.filter(name__contains="张三")
# 反向查询
a = Author.objects.get(id=5)
a.book_set.all() # 获取所有关联的Book
多对多关联中,add()、set() 和 remove() 可直接使用主键
a = Author.objects.get(id=5)
a.book_set.set([b1, b2])
# 等价于
a.book_set.set([b1.pk, b2.pk])
二、N+1查询问题
问题分析
N+1 查询是常见的性能问题,表现为主查询后执行 N 次额外查询。例如:
books = Book.objects.all()
for book in books:
print(book.author.first_name)
以上代码会产生 1 次查询获取所有 Book,加上 N 次查询获取对应的 Author(N 为 Book 数量),共 N+1 次查询。
检测方法
- Django Debug Toolbar:直观显示请求中的 SQL 查询
- 日志记录:配置日志记录 SQL 语句
- 性能分析工具:如 Django Silk 分析查询性能
解决方案
方法 1:使用 select_related
适用于一对多(正向)和一对一关系,通过 SQL JOIN 预加载关联对象
- 语法:
select_related('related_field'),related_field是模型中定义的ForeignKey或OneToOneField字段
books = Book.objects.select_related('author').all()
for book in books:
print(book.author.first_name) # 无额外查询
可结合 only() 选择需要的字段
books = Book.objects.select_related('author').only('title', 'author__name')
支持多级关联
# 加载书籍、作者及作者家乡信息
books = Book.objects.select_related('author__hometown').all()
for book in books:
print(book.author.hometown.name) # 无额外查询
方法 2:使用 prefetch_related
适用于多对多和反向关系,通过批量查询后在 Python 中关联。适用场景:
- 多对多关系(ManyToManyField)
- 反向一对多关系
- 反向一对一关系
books = Book.objects.prefetch_related('authors').all()
for book in books:
print(book.authors.all()) # 无额外查询
参考资料:Django 数据库访问优化
三、高级查询优化
values()
返回字典形式的查询集(返回一个 ValuesQuerySet 对象,其中每个元素是一个字典),适合提取特定字段
books = Book.objects.values('title', 'author')
for book in books:
print(book)
# 输出示例
{'title': 'Book1', 'author': 'Author1'}
{'title': 'Book2', 'author': 'Author2'}
values_list()
返回元组形式的查询集(返回一个 ValuesListQuerySet 对象,其中每个元素是一个元组),内存占用更低
books = Book.objects.values_list('title', 'author')
for book in books:
print(book)
### 输出示例
('Book1', 'Author1')
('Book2', 'Author2')
使用 flat=True 获取单一字段值列表。如果有多个字段时,传入 flat 会报错。
titles = Book.objects.values_list('title', flat=True)
# <QuerySet ['红楼梦', '西游记', ...]>
使用 named=True ,结果返回 namedtuple()
books_info = Book.objects.values_list("id", "title", named=True)
# <QuerySet [Row(id=1, title='红楼梦'), ...]>
values()和values_list()对比
| 对比维度 | values() |
values_list() |
|---|---|---|
| 返回值类型 | 返回一个包含字典的查询集,字典的键为字段名,值为字段对应的数据 | 返回一个包含元组的查询集,元组中的元素依次对应指定字段的值 |
| 内存占用 | 相对较高,因为字典需要存储键值对信息 | 通常更节省内存,元组是更轻量的数据结构,无需存储字段名 |
| 使用场景 | 适合需要通过字段名访问字段值的场景,例如需要明确知道每个值对应的字段时 | 适合仅需要获取字段值的场景,例如只需批量获取某个或某几个字段的具体数据时 |
Q() 对象复杂查询
Q() 对象用于构建复杂查询条件,支持逻辑运算
&:逻辑与(AND)|:逻辑或(OR)~:逻辑非(NOT)
from django.db.models import Q
# 标题含Python或作者为John的书籍
books = Book.objects.filter(
Q(title__icontains="Python") | Q(author="John")
)
# 复杂组合条件
books = Book.objects.filter(
(Q(title__icontains="Python") | Q(title__icontains="Django")) &
~Q(author="John")
)
查看生成的 SQL
调试时可查看 QuerySet 生成的 SQL
queryset = Book.objects.filter(author="John")
print(queryset.query) # 输出对应的SQL语句
四、项目实战
场景
Django+Vue 后台管理系统中,一般需要支持不同的数据权限
- 仅本人数据权限
- 本部门及以下数据权限
- 本部门数据权限
- 指定部门数据权限
- 全部数据权限
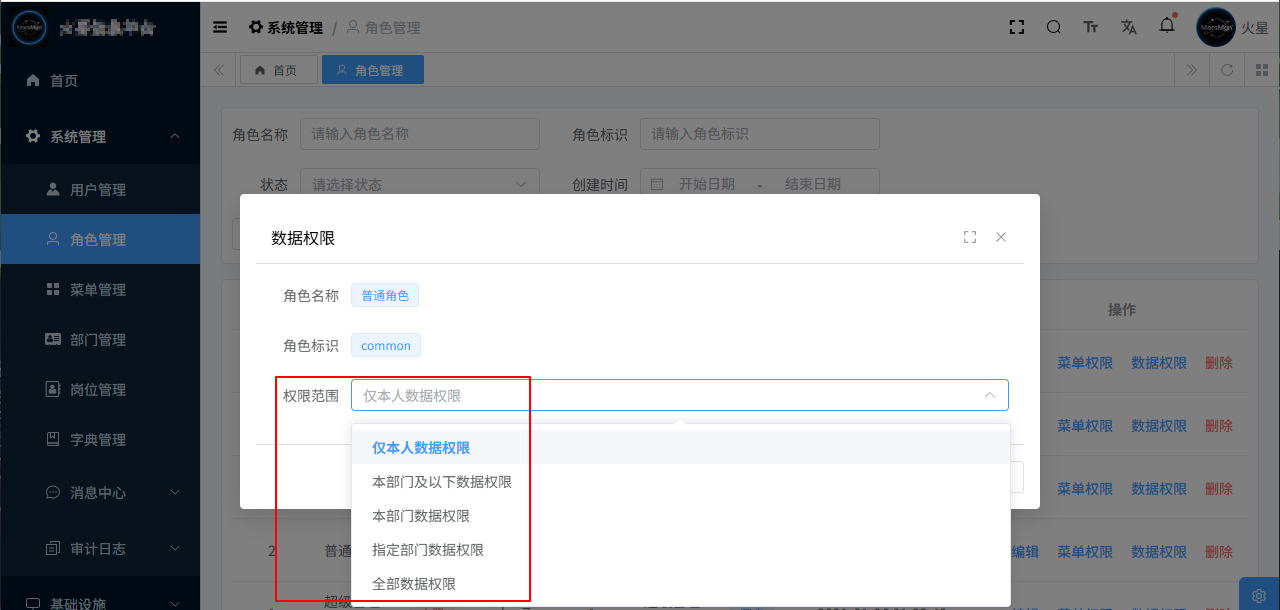
数据权限与功能权限(基于RBAC实现)的区别
- 功能权限:控制 “能做什么”(如新增、删除按钮的显示和执行)
- 数据权限:控制 “能看到什么数据”(如销售经理只能查看自己团队的数据)
实战
使用Q() 对象构建复杂查询,实现灵活的数据权限计算

您正在阅读的是《Django从入门到实战》专栏!关注不迷路~
Django模型查询与性能调优:告别N+1问题的更多相关文章
- 性能调优9:根据WaitType诊断性能
SQL Server数据库接收到查询请求,从生成计划到执行计划的过程,等待次数和等待时间在一定程度上揭示了系统性能的压力,如果资源严重不足,就会成为性能的瓶颈.因此,对等待的监控非常有助于对系统性能进 ...
- 性能调优6:Spool 假脱机调优
SQL Server的Spool(假脱机)操作符,用于把前一个操作符处理的数据(又称作中间结果集)存储到一个隐藏的临时结构中,以便在执行过程中重用这些数据.这个临时结构都创建在tempdb中,通常的结 ...
- Elasticsearch索引和查询性能调优的21条建议
Elasticsearch部署建议 1. 选择合理的硬件配置:尽可能使用 SSD Elasticsearch 最大的瓶颈往往是磁盘读写性能,尤其是随机读取性能.使用SSD(PCI-E接口SSD卡/SA ...
- JVM内存模型与性能调优
堆内存(Heap) 堆是由Java虚拟机(JVM,下文提到的JVM特指Sun hotspot JVM)用来存放Java类.对象和静态成员的内存空间,Java程序中创建的所有对象都在堆中分配空间,堆只用 ...
- 在SQL Server 2016里使用查询存储进行性能调优
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在 ...
- 记一次sql server 性能调优,查询从20秒至2秒
一.需求 需求很简单,就是需要查询一个报表,只有1个表,数据量大约60万左右,但是中间有些逻辑. 先说明一下服务器配置情况:1核CPU.2GB内存.机械硬盘.Sqlserver 2008 R2.Win ...
- JVM性能调优(1) —— JVM内存模型和类加载运行机制
一.JVM内存模型 运行一个 Java 应用程序,必须要先安装 JDK 或者 JRE 包.因为 Java 应用在编译后会变成字节码,通过字节码运行在 JVM 中,而 JVM 是 JRE 的核心组成部分 ...
- Java 应用性能调优实践
Java 应用性能优化是一个老生常谈的话题,笔者根据个人经验,将 Java 性能优化分为 4 个层级:应用层.数据库层.框架层.JVM 层.通过介绍 Java 性能诊断工具和思路,给出搜狗商业平台的性 ...
- Advacned Puppet: Puppet Master性能调优
本文是Advanced Puppet系列的第一篇:Puppet master性能调优,谈一谈如何优化和提高C/S架构下master端的性能. 故事情节往往惊人地类似:你是一名使用Puppet管理线上业 ...
- linux性能调优概述
- 什么是性能调优?(what) - 为什么需要性能调优?(why) - 什么时候需要性能调优?(when) - 什么地方需要性能调优?(where) - 什么人来进行性能调优?(who) - 怎么样 ...
随机推荐
- IPO——LeetCode⑫
//原题链接https://leetcode.com/problems/ipo/ 题目描述 Suppose LeetCode will start its IPO soon. In order to ...
- 用QT、QImage来制作简单图像处理工具
用QT.QImage来制作简单图像处理工具 源码地址: https://github.com/dependon/simple-image-filter 下载地址(windows版本) github 下 ...
- Linux环境使用apt-get安装telnet、curl、ifconfig、vim、ping等工具【转】
当在Linux服务器执行Telnet命令时,如果提示command not found: telnet,说明服务器上并未安装Telnet命令,需要安装此命令.下面介绍在linux服务器如何安装te ...
- SenseVoice部署,并调用api接口
目录 安装Python 代码下载 虚拟环境 安装依赖 下载模型 修改启用webui.py 启用api.py 安装Python 这个网上找下教程安装下就可以,版本应该没有什么要求,我装的是3.10.7 ...
- 大巧不工,袋鼠云正式开源大数据任务调度平台——Taier(太阿)!
2022年2月22日,在今天这个特殊的日子里,历经多年持续迭代和千万周期实例并发调度考验的Taier(太阿)终于开源了! Github开源地址: https://github.com/DTStack/ ...
- 致谢每一位ChunJun Contributor!这里有一份礼物等你领取!
作为一个批流统一的数据集成框架,秉承着易用.稳定.高效的目标,ChunJun于2018年4月29日在Github上将内核源码正式开放. 从还被叫作FlinkX,写下第一行代码开始,ChunJun已经走 ...
- 你知道CAE软件的配置要求吗?
CAE软件是一类特殊的计算机软件,主要用于工程设计和分析.由于CAE软件的处理量非常大,因此对计算机的配置要求较高.在选择计算机配置时,需要考虑多个因素,包括CPU.GPU.内存和存储等. 首先,CP ...
- [arc133e]Cyclic Medians
E - Cyclic Medians 看到中位数,就是经典套路:将\(\geq\)中位数的都赋值为\(1\),\(<\)的赋值为\(0\) 那么对于数\(A\),就等于\(\sum_{i=1}^ ...
- java 获取访问的真实ip
request 是 javax.servlet.http.HttpServletRequest 获取其他机器访问自己服务时的真实ip public String getIP(HttpServletRe ...
- typescript结构化类型应用两例
介绍 结构化类型是typescript类型系统的一个重要特性,如果不了解这个特性,则经常会被typescript的行为搞得一头雾水,导致我们期待的行为与实际的行为不一致.今天我们就来看两个例子. 不了 ...