(附体验地址)大模型知识引擎:AI 助手能否助力销售技能提升?
体验地址:https://lke.cloud.tencent.com/webim_exp/#/chat/FAIMcM
腾讯云的大模型知识引擎本身定位于为企业客户及合作伙伴提供服务,因此我在探索如何最佳利用其现有功能与特点时,专注于实际应用场景的挖掘。为此,今天我搭建出了一个卖车销售话术练习助手,旨在帮助销售人员更高效地提升其销售技能。
虽然每个人都能尝试当销售,但并不是每个人都能成为一名出色的销售人员。因此,我的目标是通过智能助手帮助销售人员优化话术,并针对性地提供总结与建议,从而帮助他们快速进入工作状态并提升销售业绩。
助手分析
先看下助手的功能,助手同样是基于腾讯云的大模型知识引擎构建,采用工作流模式进行优化和提升,整个过程被细分为几个关键环节:

第一步:当输入开始时,系统立即进入对话模式。在此阶段,助手首先提供一个随机匹配的客户特征,模拟可能的客户需求。接着,大模型会根据历史数据进行思考和生成一个与客户沟通的初始对话。用户在接收到这一内容后,可继续进行对话互动。
在对话过程中,如果大模型识别到销售人员的话术可能导致客户失去沟通兴趣,它会自动判断并挂断对话。同时,大模型将生成一份针对本次对话的优化建议,帮助销售人员提高沟通策略。
此外,销售人员也可以随时在对话过程中输入“结束”命令,主动结束当前对话。如果销售人员认为对话已无进一步价值或者进展困难时,选择结束对话不仅能节省时间,还能基于对话数据生成合理的反馈总结。
通过这个智能化的流程,系统不仅可以自动化地优化对话内容,还能够通过实时反馈帮助销售人员改进和提升其话术技巧,从而有效提升客户沟通的效率和成功率。
工作流模式
首先,为了确保我的助手能够严格遵循我设定的游戏规则,我决定将助手配置为单一工作流模式,以此确保每个步骤和操作都能按照我的要求进行。如图所示,这是我所采取的设置方式。
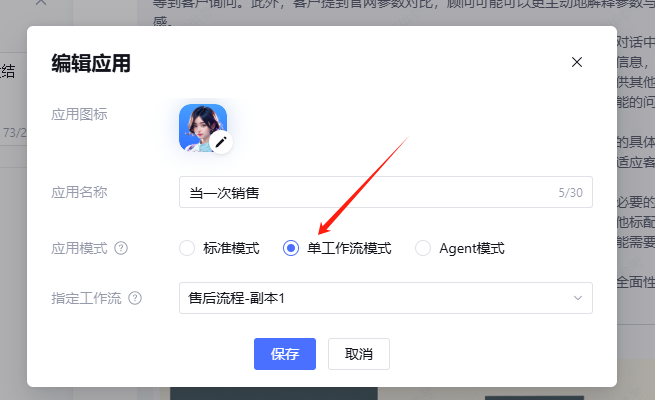
这里我们也必须制定一个工作流,我们去新建一个即可。
逻辑判断
条件判断
首先,规则中不可或缺的一项就是条件判断。我们需要根据用户的选择来判断其是希望开始操作还是结束操作。因此,我在流程中加入了两个关键的判断条件,如下图所示。
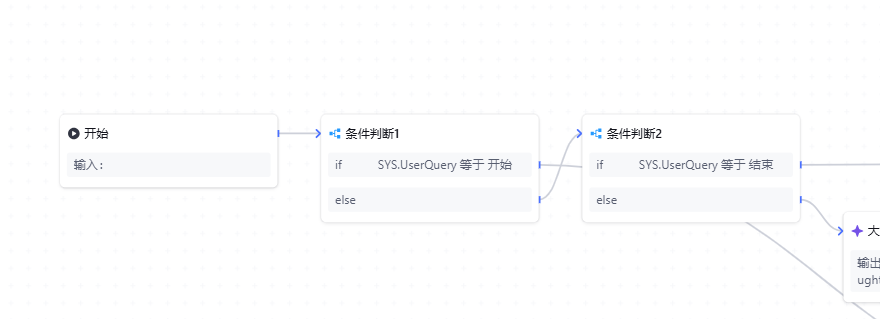
意图识别
在与客户沟通的真实场景中,事实上,大部分情况下都是用户主动结束通话。因此,为了更加贴合实际情况,我在系统中加入了一项意图识别功能,我将其称之为“高级判断”。该功能的主要目的是判断用户是否仍然有意愿继续与销售人员进行进一步的沟通与交流。如图所示:

这里提到的意图1和意图2并不是由我们手动配置的,而是在使用模板时,系统通过自动识别和分析客户的行为及语言模式来确定的。如下我的demo示例:

通过这种方式,整体上可以有效地模拟和满足真实场景中的话术沟通需求。
随机匹配客户
在我们的日常工作中,往往会接触到各种各样的人,面对不同的需求和情境。为了更好地应对这些复杂多变的场景,我事先根据实际情况设置了一些客户特征,并通过代码节点配置来实现这些特征的随机匹配,以便能够快速、灵活地处理不同类型的客户和需求。
代码节点
简单来看一下代码节点的实现,除了由于第三方依赖无法直接添加的限制外,对于系统内置的依赖包,我们可以自由地进行调用和使用。这使得我们在编写代码时,能够更加灵活地选择合适的工具和库,以满足不同的功能需求。以下是相关代码的展示:
import random
# 请保存函数名为main,输入输出均为dict;最终结果会以json字符串方式返回,请勿直接返回不支持json.dumps的对象
def main(params: dict) -> dict:
age = ['年轻','中年','老年']
person = ['男性','女性']
piqi = ['急躁', '暴躁', '温和', '宽容', '冷静', '固执', '敏感', '冲动', '沉默', '乐观', '自制力强', '冷漠', '焦虑', '嫉妒', '内向', '外向']
cars = ['宝马 X5', '宝马 3系', '宝马 X7', '宝马 M5']
return {
'age': random.choice(age),
'person':random.choice(person),
'piqi':random.choice(piqi),
'car':random.choice(cars),
}
这些返回结果中的各个字段,如果你希望在后续的操作中使用它们,就需要将它们明确地输出到 output 中进行相应的设置。如图所示:
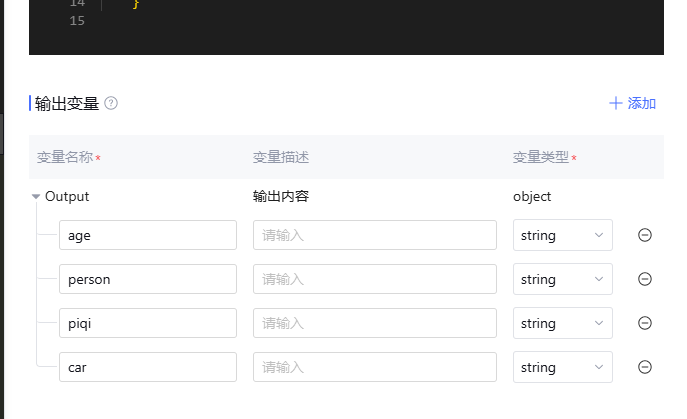
伪客户(大模型)
为了实现与用户的有效交互,自然需要借助大模型的强大能力进行介入。在此过程中,我们会根据我们提供的客户特征,提前让大模型生成一段历史对话。这段历史对话将为销售人员提供一个预设的沟通框架,使得他们能够更快速、更精准地与客户进行交流,如下所示:
帮我生成一通购车询问的通话记录,通话跟进记录要严格按照购买人群和人物性格进行模拟对话,并生成前2条销售顾问与客户之间的聊天,最后一句话为用户的回答或者询问,以下是客户的特征:
年龄特征:age
人物特征:person
脾气特征:piqi
意向车辆:car
对话生成格式为:
顾问回答:您好,张先生!感谢接听电话,我是XX宝马店的顾问小李。看到您之前关注过宝马X7,想了解一下您对配置或性能方面有没有特别的需求?
用户回答:你好。配置我看过官网了,主要想确认3.0T顶配的现车情况,还有你们说的“M运动套件”具体包含什么。
入参
如果希望大模型能够根据我们生成的客户特征进行推理和生成答案,那么必须使用入参。这些入参实际上是动态生成的变量,只有在正确引用这些变量的情况下,大模型才能够基于这些信息生成与上下文相关的答案。如果不进行引用,大模型生成的答案将无法与当前上下文产生有效关联。如下图所示:
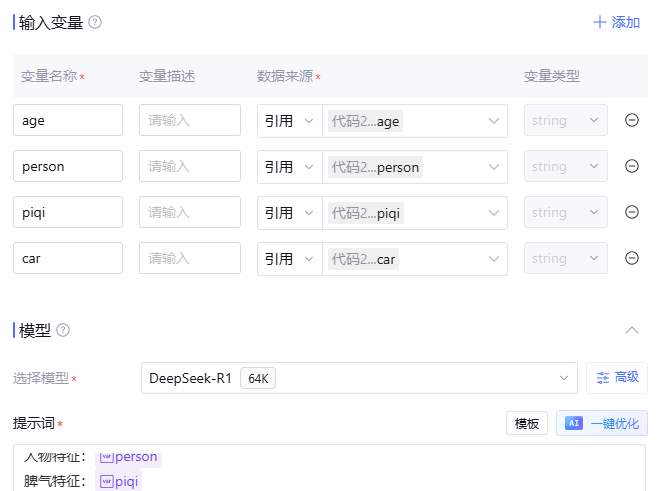
回复
可以看到,我们选择的思考模型是DeepSeek-R1,其最大的特点便是需要较长时间的思考链进行推理和分析。为了避免用户在等待过程中产生焦虑感或感到无所适从,我们需要在适当时机给予用户友好的提示和反馈。
因此,在设计交互时,回复节点就显得尤为重要。如图所示:
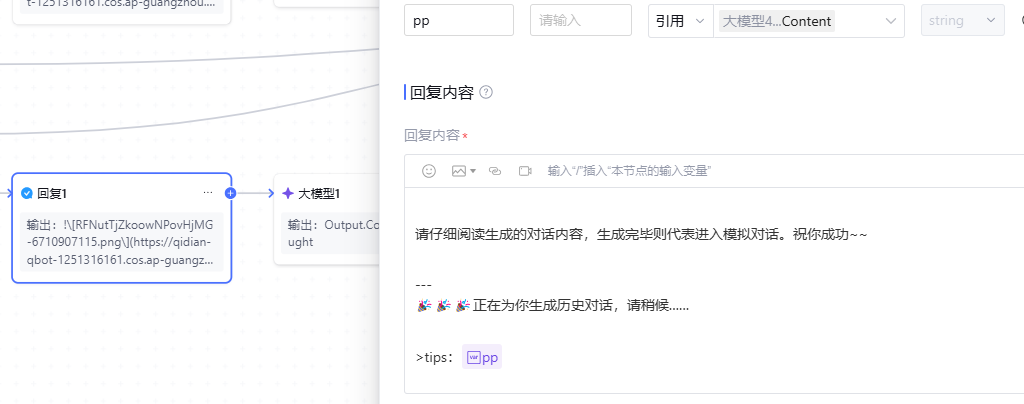
当然,你完全可以在回复中上传图片,因为图文并茂的展示方式比单纯的文字描述更加直观和易于理解。看下我的效果:

请注意,当上传图片时,Markdown语法将无法生效。只有在没有图片的情况下,Markdown语法才能正常呈现。
总结及建议
在所有对话结束之后,最为关键的一点是务必借助大模型的能力,帮助我们对整个通话过程中的销售话术进行全面总结和分析,找出其中可能存在的问题和不足之处,并清晰明确地反馈给销售顾问。
通过这种方式,不仅能够帮助销售顾问认识到自身话术的缺陷,还能提供具体的改进建议,指导他们如何有效地提升沟通技巧。只有这样,销售顾问才能在日常工作中更好地进行自我学习和进步
系统变量
总结的话,我们必须依赖于系统变量这一关键参数,即 SYS.ChatHistory,来实现相关功能或优化操作。
然而,需要注意的是,尽管 SYS.ChatHistory 是一个重要的参数,它实际上是一个字符串,而非数组。这一点在实际操作中必须特别留意。为了更好地理解它的结构和内容,我们可以通过打印输出的方式查看其具体形式,如图所示:
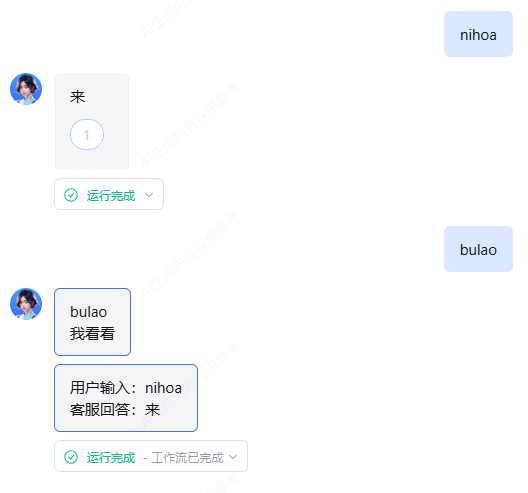
在我们的系统中,用户输入的内容和助手的回答可以视作一种客服对话模式。然而,有一个问题需要考虑:如果上下文历史特别长,如何处理呢?如果每次都要进行全量的上下文总结,那么所需的token数量可能会非常庞大,甚至达到上万token,这会带来不小的负担。
事实上,我们可以通过调整相关的参数或变量来控制上下文的使用方式。接下来,我们引用一个具体的变量来演示如何解决这个问题,如下图所示。
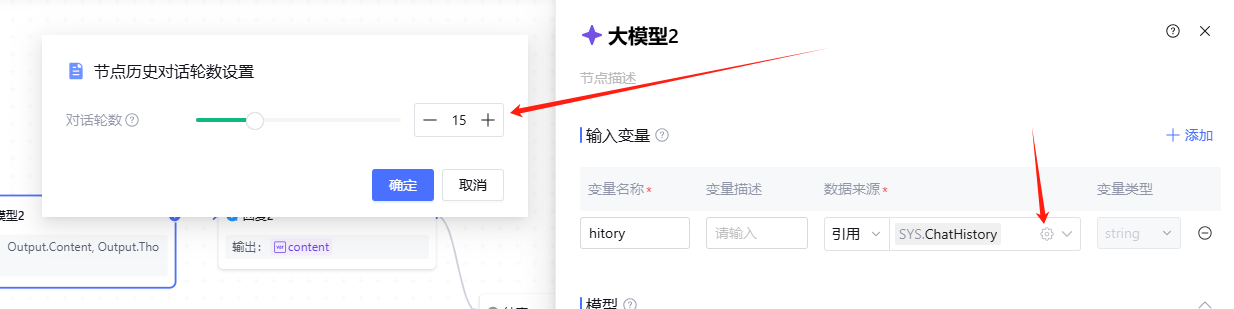
虽然它本身是一个字符串,但实际上在后台它仍然以数组的形式存在,只是被平台进行了一定的封装处理。这种封装并不会影响我们对话轮数的调节,因此我们依然能够正常操作和控制对话的进程。
封装
如果你的业务中有多个场景涉及到类似的需求,那么完全可以将这个工作流引入到其他工作流中进行复用。这也是为什么在开始节点中需要设置一些参数的原因。尽管这些带有参数的工作流无法直接被助手引用并执行,因为在这种情况下会导致直接报错,原因是助手并不会主动为这些参数赋值。如图所示:
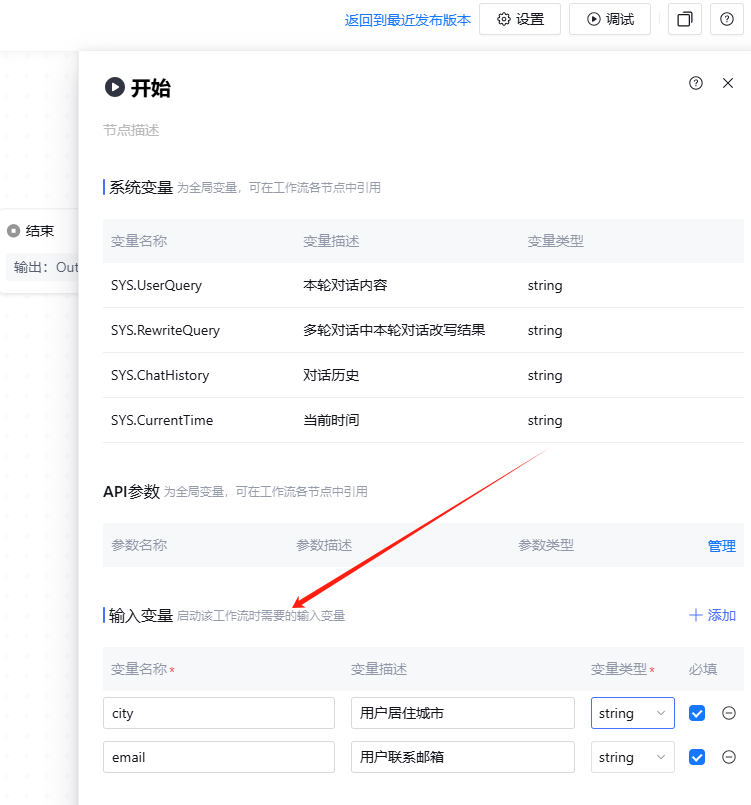
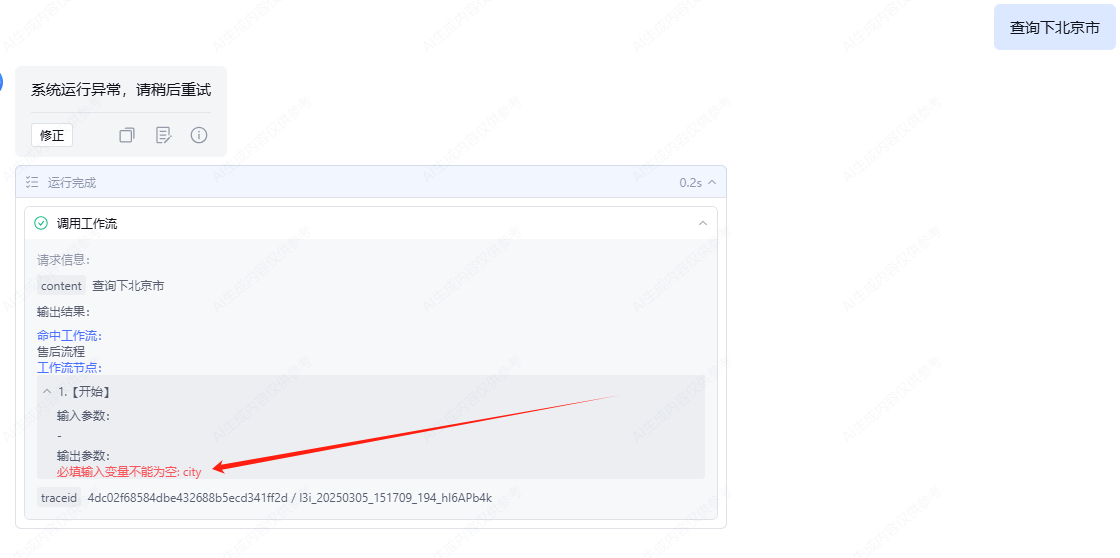
这里面我已经为一些输入变量进行了设置。如果将这些变量直接引入到助手中进行调用,助手会立即提示报错。如图所示:
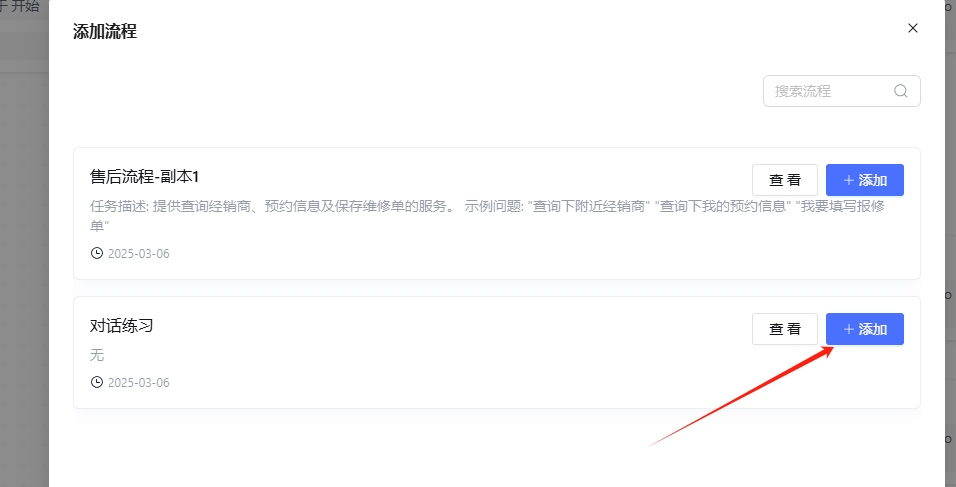
但如果我的工作流所需要的参数能够从上游系统获取,并且上游可以直接提供给我,那么这些参数是完全可以直接嵌套使用的。例如,以下这种方式:
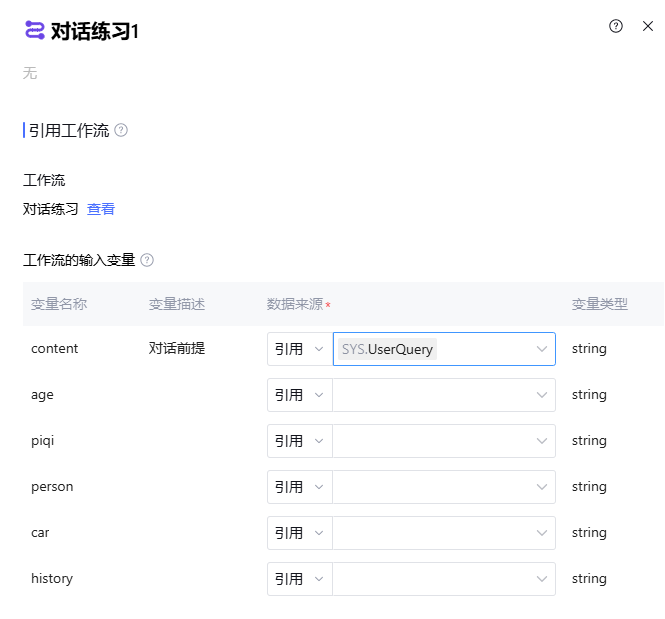
填入必要的参数即可,如图所示:
欢迎语
这段欢迎语非常重要,必不可少。我写的内容较为简洁,主要是为了清楚地说明本助手的使用规则。正如图中所展示的那样,它为用户提供了一个清晰的指南,帮助大家快速理解和掌握如何高效使用本助手。
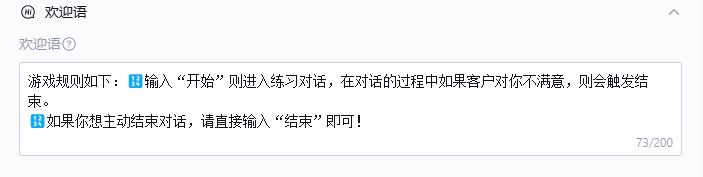
欢迎语必须具备明确的引导作用,避免无关的废话和冗余内容。不过,适当地引入一些表情包或幽默元素,可以有效地调节气氛,增加用户的参与感和愉悦感,使整体体验更加轻松和有趣。
效果展示
为了减少演示的时间,我在与助手沟通时只是简短地说了两句话,随后迅速改变了我的态度,主动采取了较为消极的态度,从而诱导并触发了挂断电话的行为。当然,直接输入“结束”命令也能实现同样的效果。

小结
今天的分享到此结束。通过对分析助手工作流模式的深入剖析,我们可以清晰地看到,从最初的客户匹配、对话模拟,到最后的总结反馈,每一个环节都经过了精心的设计与优化。大模型强大的计算与判断能力,使得助手不仅能对实时对话进行优化,还能够根据不同的实际情境,灵活生成个性化的销售话术。最终,助手的作用是帮助销售人员在不断的实践过程中提升其沟通技巧,实现更高效的销售业绩。
虽然目前并没有覆盖所有节点,但我们已成功实现了最小粒度的销售话术助手的开发。希望这个工具能为其他有类似业务需求的企业提供一些启示,帮助他们更好地让员工接触并利用AI的优势,提升员工的工作能力,从而实现更高效的企业运作与业绩增长。
我是努力的小雨,一个正经的 Java 东北服务端开发,整天琢磨着 AI 技术这块儿的奥秘。特爱跟人交流技术,喜欢把自己的心得和大家分享。还当上了腾讯云创作之星,阿里云专家博主,华为云云享专家,掘金优秀作者。各种征文、开源比赛的牌子也拿了。
想把我在技术路上走过的弯路和经验全都分享出来,给你们的学习和成长带来点启发,帮一把。
欢迎关注努力的小雨,咱一块儿进步!
(附体验地址)大模型知识引擎:AI 助手能否助力销售技能提升?的更多相关文章
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- BAT等大厂已开源的70个实用工具盘点(附下载地址)
前面的一篇文章<微软.谷歌.亚马逊.Facebook等硅谷大厂91个开源软件盘点(附下载地址)>列举了国外8个互联网公司(包括微软.Google.亚马逊.IBM.Facebook.Twit ...
- 微软、谷歌、亚马逊、Facebook等硅谷大厂91个开源软件盘点(附下载地址)
开源软件中有大量专家构建的代码,大大节省了开发人员的时间和成本,热衷于开源的大厂们总是能够带给我们新的惊喜.2016年9月GitHub报告显示,GitHub已经有超过 520 万的用户和超 30 万的 ...
- AI时代大点兵-国内外知名AI公司2018年最新盘点
AI时代大点兵-国内外知名AI公司2018年最新盘点 导言 据腾讯研究院统计,截至2017年6月,全球人工智能初创企业共计2617家.美国占据1078家居首,中国以592家企业排名第二,其后分别是英国 ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 大数据计算引擎之Flink Flink CEP复杂事件编程
原文地址: 大数据计算引擎之Flink Flink CEP复杂事件编程 复杂事件编程(CEP)是一种基于流处理的技术,将系统数据看作不同类型的事件,通过分析事件之间的关系,建立不同的时事件系序列库,并 ...
- 搭乘“AI大数据”快车,肌肤管家,助力美业数字化发展
经过疫情的发酵,加速推动各行各业进入数据时代的步伐.美业,一个通过自身技术.产品让用户变美的行业,在AI大数据的加持下表现尤为突出. 对于美妆护肤企业来说,一边是进入存量市场,一边是疫后的复苏期,一边 ...
- 有必要了解的大数据知识(一) Hadoop
前言 之前工作中,有接触到大数据的需求,虽然当时我们体系有专门的大数据部门,但是由于当时我们中台重构,整个体系的开发量巨大,共用一个大数据部门,人手已经忙不过来,没法办,为了赶时间,我自己负责的系统的 ...
随机推荐
- go语言签发和验证license
https://www.cnblogs.com/guangdelw/p/18328342 生成非对称密钥 package main import ( "crypto/rand" & ...
- linux shell移植,sh不支持数组及bash移植
查看此时系统shell ls -al /bin/sh Linux 操作系统缺省的 shell 是Bourne Again shell,它是 Bourne shell 的扩展,简称 Bash,与 Bou ...
- logback 中打印自定义参数 (ip 服务名)
打印 application.properties 配置文件中的参数 首先需要引入文件 <property resource="application.properties" ...
- Qt/C++音视频开发65-切换声卡/选择音频输出设备/播放到不同的声音设备/声卡下拉框
一.前言 近期收到一个用户需求,要求音视频组件能够切换声卡,首先要在vlc上实现,于是马不停蹄的研究起来,马上查阅对应vlc有没有自带的api接口,查看接口前,先打开vlc播放器,看下能不能切换,因为 ...
- Qt编写安防视频监控系统64-子模块8飞行轨迹
一.前言 飞行轨迹子模块是专为无人机打造的模块,也可以作为机器人移动模块,通过传入一个经纬度值,实时更新设备的位置和绘制轨迹,模块已经内置了接口进行处理,支持不同设备不同的轨迹颜色(这个功能好). 这 ...
- Qt编写的项目作品28-视频监控显示安卓版
一.功能特点 1.1 基础功能 支持各种音频视频文件格式,比如mp3.wav.mp4.asf.rm.rmvb.mkv等. 支持各种视频流格式,比如rtp.rtsp.rtmp.http等. 本地音视频文 ...
- OpenCV4.1.0与CUDAcuda_10.1.105联合进行图像特征点提取和特征匹配时,运行程序时错误提示:无法定位程序输入点?createBFMatchercv@DescriptorMatcher@cuda@cv......于动态链接库......
问题描述: OpenCV4.1.0与CUDAcuda_10.1.105联合进行图像特征点提取和特征匹配时,运行程序时错误提示:无法定位程序输入点?createBFMatchercv@Descripto ...
- [转]解决Spring Data Jpa 实体类自动创建数据库表失败问题
先说一下我遇到的这个问题,首先我是通过maven创建了一个spring boot的工程,引入了Spring data jpa,结果实体类创建好之后,运行工程却没有在数据库中自动创建数据表. 找了半天发 ...
- 百度公共IM系统的Andriod端IM SDK组件架构设计与技术实现
本文由百度技术团队分享,引用自百度Geek说,原题"百度Android IM SDK组件能力建设及应用",本文进行了排版和内容优化. 1.引言 移动互联网时代,随着社交媒体.移动支 ...
- SpringCloud(一) - Dubbo + Zookeeper
Dubbo 和Zookeeper 不是SpringCloud的东西,放在这里只是为了方便复习: 1.下载安装Zookeeper和Dubbo 1.1 下载安装教程 下载安装教程 windows环境下安装 ...