Canal——原理架构及应用场景
Canal简介
Canal是阿里开源的一款基于Mysql数据库binlog的增量订阅和消费组件,通过它可以订阅数据库的binlog日志,然后进行一些数据消费,如数据镜像、数据异构、数据索引、缓存更新等。相对于消息队列,通过这种机制可以实现数据的有序化和一致性。
github地址:https://github.com/alibaba/canal
完整wiki地址:https://github.com/alibaba/canal/wiki
Canal工作原理
原理相对比较简单:
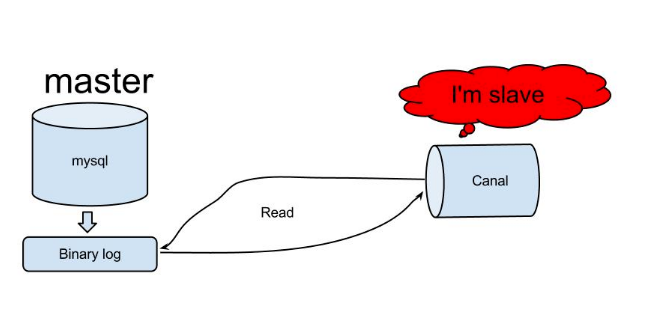
- canal模拟mysql slave与mysql master的交互协议,伪装自己是一个mysql slave,向mysql master发送dump协议
- mysql master收到mysql slave(canal)发送的dump请求,开始推送binlog增量日志给slave(也就是canal)
- mysql slave(canal伪装的)收到binlog增量日志后,就可以对这部分日志进行解析,获取主库的结构及数据变更
Mysql主从同步原理
canal工作原理其实也是基于mysql主从同步原理的,所以理解mysql主从同步原理是第一步
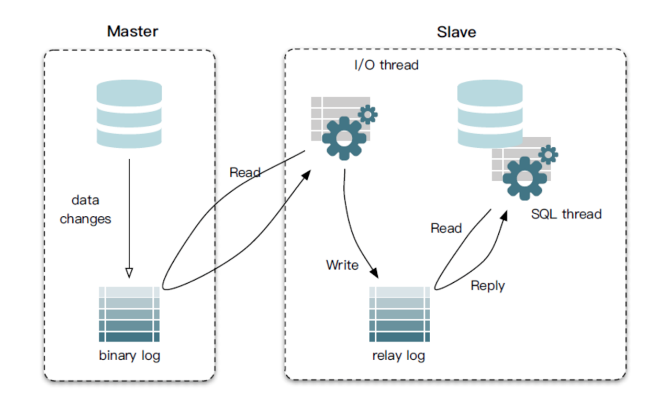
- master将改变记录到二进制日志(binary log)中
- slave(I/O thread)将master的记录改变的binlog日志拷贝到它的中继日志(relay log)中
- slave(SQL thread)重做中继日志中的事件,将改变反映它自己的数据从库中
Canal架构
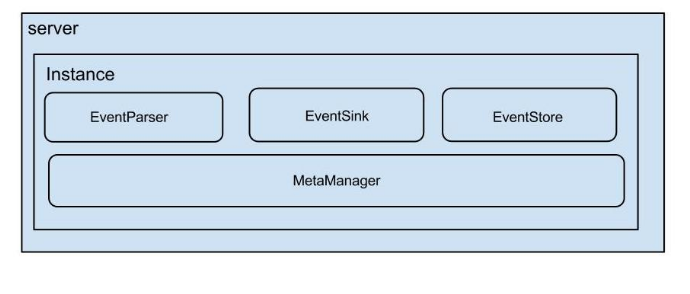
说明:
server代表一个canal运行实例,对应于一个jvm
instance对应于一个数据队列
instance模块:
eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
eventStore (数据存储)
metaManager (增量订阅&消费信息管理器)
Canal-HA机制
canal是支持HA的,其实现机制也是依赖zookeeper来实现的,用到的特性有watcher和EPHEMERAL节点(和session生命周期绑定),与HDFS的HA类似。
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
- canal server: 为了减少对mysql dump的请求,不同server上的instance(不同server上的相同instance)要求同一时间只能有一个处于running,其他的处于standby状态(standby是instance的状态)。
- canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
server ha的架构图如下:
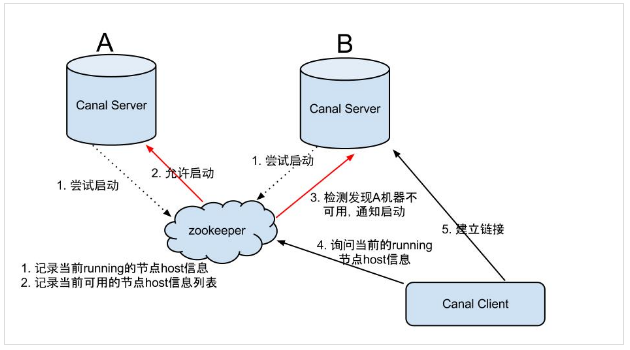
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper_进行一次尝试启动判断_(实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态。
- 一旦zookeeper发现canal server A创建的instance节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance。
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect。
Canal Client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制.
Canal应用场景
1、同步缓存redis/全文搜索ES
canal一个常见应用场景是同步缓存/全文搜索,当数据库变更后通过binlog进行缓存/ES的增量更新。当缓存/ES更新出现问题时,应该回退binlog到过去某个位置进行重新同步,并提供全量刷新缓存/ES的方法,如下图所示。
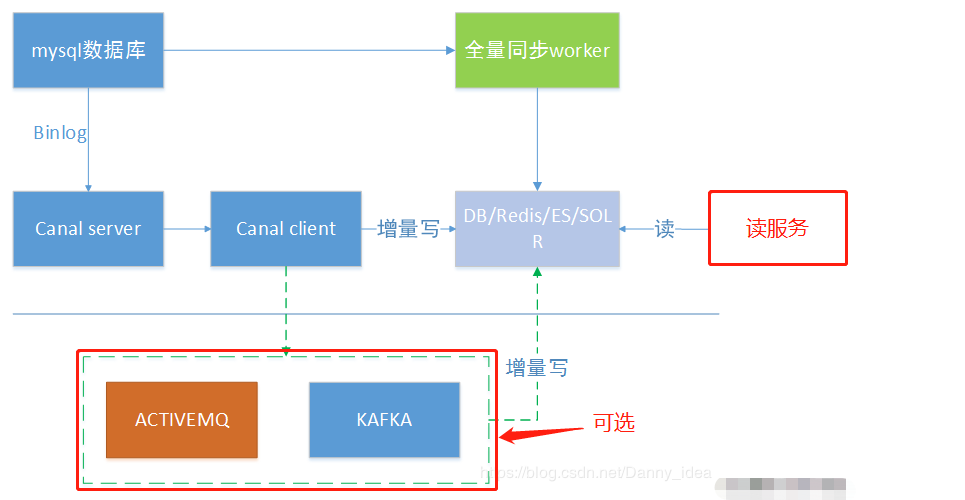
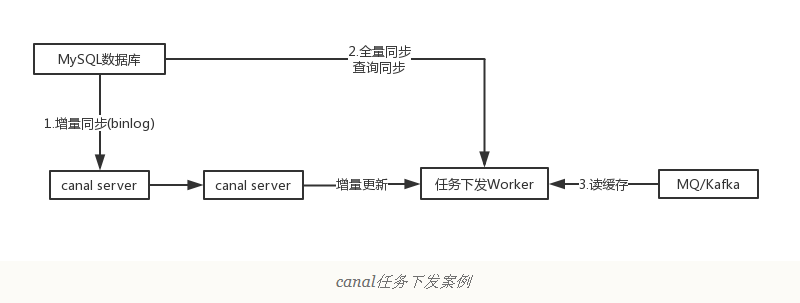
2、下发任务
另一种常见应用场景是下发任务,当数据变更时需要通知其他依赖系统。其原理是任务系统监听数据库变更,然后将变更的数据写入MQ/kafka进行任务下发,比如商品数据变更后需要通知商品详情页、列表页、搜索页等先关系统。这种方式可以保证数据下发的精确性,通过MQ发送消息通知变更缓存是无法做到这一点的,而且业务系统中不会散落着各种下发MQ的代码,从而实现了下发归集,如下图所示。
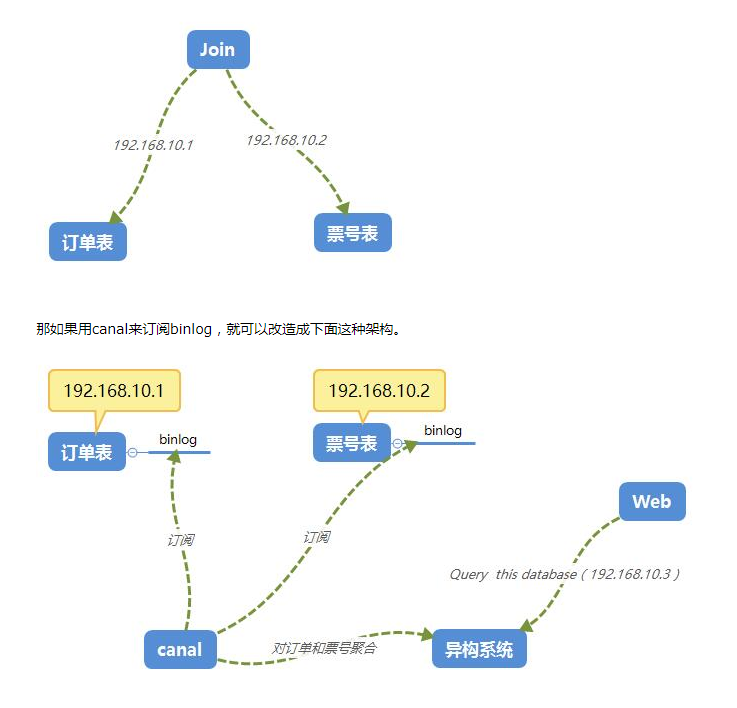
3、数据异构
在大型网站架构中,DB都会采用分库分表来解决容量和性能问题,但分库分表之后带来的新问题。比如不同维度的查询或者聚合查询,此时就会非常棘手。一般我们会通过数据异构机制来解决此问题。
所谓的数据异构,那就是将需要join查询的多表按照某一个维度又聚合在一个DB中。让你去查询。canal就是实现数据异构的手段之一。
参考:
https://www.cnblogs.com/huangxincheng/p/7456397.html
Canal——原理架构及应用场景的更多相关文章
- 阿里P8架构师谈:数据库分库分表、读写分离的原理实现,使用场景
本文转载自:阿里P8架构师谈:数据库分库分表.读写分离的原理实现,使用场景 为什么要分库分表和读写分离? 类似淘宝网这样的网站,海量数据的存储和访问成为了系统设计的瓶颈问题,日益增长的业务数据,无疑对 ...
- 这可能是目前最透彻的Netty原理架构解析
https://juejin.im/post/5be00763e51d453d4a5cf289 本文基于 Netty 4.1 展开介绍相关理论模型,使用场景,基本组件.整体架构,知其然且知其所以然,希 ...
- Netty原理架构解析
Netty原理架构解析 转载自:http://www.sohu.com/a/272879207_463994本文转载关于Netty的原理架构解析,方便之后巩固复习 Netty是一个异步事件驱动的网络应 ...
- 【Netty】最透彻的Netty原理架构解析
这可能是目前最透彻的Netty原理架构解析 本文基于 Netty 4.1 展开介绍相关理论模型,使用场景,基本组件.整体架构,知其然且知其所以然,希望给大家在实际开发实践.学习开源项目方面提供参考. ...
- (转)OpenStack —— 原理架构介绍(一、二)
原文:http://blog.51cto.com/wzlinux/1961337 http://blog.51cto.com/wzlinux/category18.html-------------O ...
- MySQL运行机制原理&架构
1.MySQL知识普及: MySQL是一个开放源代码的关系数据库管理系统. MySQL架构可以在多种不同场景中应用并发挥良好作用.主要体现在存储引擎的架构上,插件式的存储引擎架构将查询处理和其它的系统 ...
- Ceph介绍及原理架构分享
https://www.jianshu.com/p/cc3ece850433 1. Ceph架构简介及使用场景介绍 1.1 Ceph简介 Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能. ...
- 开源框架TLog核心原理架构解析
前言 最近在做TLog 1.2.5版本的迭代,许多小伙伴之前也表示说很想参与开源项目的贡献.为了让项目更好更快速的迭代新特性以及本着发扬开源精神互相学习交流,很有幸招募到了很多小伙伴与我一起前行. 为 ...
- kylin(一): 原理架构
由eBay开源的一个大数据OLAP框架,2014年11月加入了Apache,项目名字也改成了"Apache Kylin",Apache Kylin是唯一来自中国的Apache顶级开 ...
随机推荐
- CVE-2018-10933 LibSSH auth bypass
漏洞原理 认证实现错误, 认证分为多个步骤,可以直接跳到成功的步骤 A vulnerability was found in libssh's server-side state mach ...
- python_函数高级
1.函数名当变量来使用 def func(): print('wdc') # 可以将函数赋值给变量 v1 = func v1() func() def func(): print('wdc')# 可以 ...
- linux基础_用户管理
1.创建用户 基本语法 创建用户:useradd [选项] 用户名 (1)当传教用户成功后,会自动的创建和用户名同名的家目录. (2)也可以通过useradd -d 指定目录 新用户名,给新创建的用户 ...
- python——flask常见接口开发(简单案例)
python——flask常见接口开发(简单案例)原创 大蛇王 发布于2019-01-24 11:34:06 阅读数 5208 收藏展开 版本:python3.5+ 模块:flask 目标:开发一个只 ...
- 简单的理解 StringBuffer/StringBuilder/String 的区别
StringBuffer/StringBuilder/String 的区别 这个三类之间主要的区别:运行速度,线程安全两个方面. 速度方面(快到慢): StringBuilder > Strin ...
- sublimeTest3的安装注册插件
[感谢:https://blog.csdn.net/wxl1555/article/details/69941451 ]1)下载:http://www.sublimetext.com/32)安装:(我 ...
- HDU 6058 - Kanade's sum | 2017 Multi-University Training Contest 3
/* HDU 6058 - Kanade's sum [ 思维,链表 ] | 2017 Multi-University Training Contest 3 题意: 给出排列 a[N],求所有区间的 ...
- access denied
背景: 想要使用nginx转发 实现一个输出PHPinfo的页面, 比如: 访问 aaa.com/phpinfo 浏览器显示phpinfo的信息, 因为有的时候需要查看phpinfo, 所以想单独 ...
- WebService如何封装XML请求 以及解析接口返回的XML
原 WebService如何封装XML请求 以及解析接口返回的XML 置顶 2019年08月16日 15:00:47 童子泛舟 阅读数 28 标签: XML解析WebService第三方API 更多 ...
- java超大文件上传
上周遇到这样一个问题,客户上传高清视频(1G以上)的时候上传失败. 一开始以为是session过期或者文件大小受系统限制,导致的错误. 查看了系统的配置文件没有看到文件大小限制, web.xml中se ...