Python中logging在多进程环境下打印日志
因为涉及到进程间互斥与通信问题,因此默认情况下Python中的logging无法在多进程环境下打印日志。但是查询了官方文档可以发现,推荐了一种利用logging.SocketHandler的方案来实现多进程日志打印。
其原理很简单,概括一句话就是说:多个进程将各自环境下的日志通过Socket发送给一个专门打印日志的进程,这样就可以防止多进程打印的冲突与混乱情况。
本文主要记录下SocketHandler真实的用法情况:
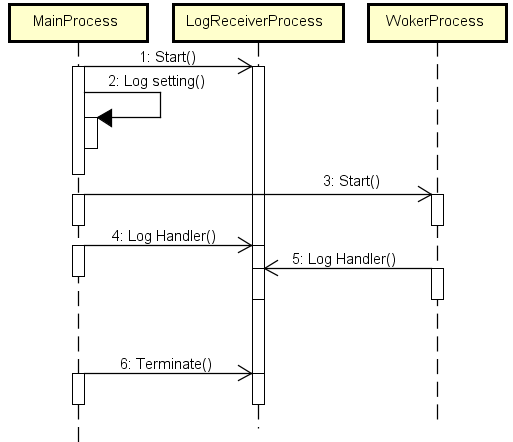
1 时序图
简单说明下逻辑:主进程(MainProcess)启动一个专门打印日志的进程(LogReceiverProcess),并且将自己(主进程)环境下的日志都“重定向”给LogReceiverProcess。同理,在后续逻辑中启动的所有工作子进程(WorkerProcess)都做一样的操作,把自己环境下的日志都“重定向”给日志进程去打印。
2 实现代码
2.1 日志进程
日志进程的代码核心在于要建立一个TCP Server来接收并处理Log record,代码如下:
import os
import logging
import logging.handlers
import traceback
import cPickle
import struct
import SocketServer
from multiprocessing import Process class LogRecordStreamHandler(SocketServer.StreamRequestHandler):
def handle(self):
while True:
try:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack(">L", chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
obj = self.unpickle(chunk)
record = logging.makeLogRecord(obj)
self.handle_log_record(record) except:
break @classmethod
def unpickle(cls, data):
return cPickle.loads(data) def handle_log_record(self, record):
if self.server.logname is not None:
name = self.server.logname
else:
name = record.name
logger = logging.getLogger(name)
logger.handle(record) class LogRecordSocketReceiver(SocketServer.ThreadingTCPServer):
allow_reuse_address = 1 def __init__(self, host='localhost', port=logging.handlers.DEFAULT_TCP_LOGGING_PORT, handler=LogRecordStreamHandler):
SocketServer.ThreadingTCPServer.__init__(self, (host, port), handler)
self.abort = 0
self.timeout = 1
self.logname = None def serve_until_stopped(self):
import select
abort = 0
while not abort:
rd, wr, ex = select.select([self.socket.fileno()], [], [], self.timeout)
if rd:
self.handle_request()
abort = self.abort def _log_listener_process(log_format, log_time_format, log_file):
log_file = os.path.realpath(log_file)
logging.basicConfig(level=logging.DEBUG, format=log_format, datefmt=log_time_format, filename=log_file, filemode='a+') # Console log
console = logging.StreamHandler()
console.setLevel(logging.INFO)
console.setFormatter(logging.Formatter(fmt=log_format, datefmt=log_time_format))
logging.getLogger().addHandler(console) tcp_server = LogRecordSocketReceiver() logging.debug('Log listener process started ...')
tcp_server.serve_until_stopped()
关键点:
(1)TCPServer的构建逻辑,拆包还原Log记录;
(2)在日志进程中设定好logging记录级别和打印方式,这里除了指定文件存储还添加了Console打印。
2.2 其他进程
除了日志进程之外的进程,设置logging都“重定向”给日志进程,并且要关闭当前进程的日志在Console打印(默认会显示Warning级别及以上的日志到Console),否则Console上日志展示会有重复凌乱的感觉。
class LogHelper:
# 默认日志存储路径(相对于当前文件路径)
default_log_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'logs') # 记录当前实际的日志所在目录
current_log_path = '' # 记录当前实际的日志完整路径
current_log_file = '' # 日志文件内容格式
log_format = '[%(asctime)s.%(msecs)03d][%(processName)s][%(levelname)s][%(filename)s:%(lineno)d] %(message)s' # 日志中时间格式
log_time_format = '%Y%m%d %H:%M:%S' # 日志进程
log_process = None def __init__(self):
pass @staticmethod
def print_console_log(level, message):
print '--------------------------------------------------'
if level == logging.WARN:
level_str = '[WARN]'
elif level == logging.ERROR:
level_str = '[ERROR]'
elif level == logging.FATAL:
level_str = '[FATAL]'
else:
level_str = '[INFO]'
print '\t%s %s' % (level_str, message)
print '--------------------------------------------------' @staticmethod
def init(clear_logs=True, log_path=''):
#
console = logging.StreamHandler()
console.setLevel(logging.FATAL)
logging.getLogger().addHandler(console) try:
# 如果外部没有指定日志存储路径则默认在common同级路径存储
if log_path == '':
log_path = LogHelper.default_log_path
if not os.path.exists(log_path):
os.makedirs(log_path)
LogHelper.current_log_path = log_path # 清理旧的日志并初始化当前日志路径
if clear_logs:
LogHelper.clear_old_log_files()
LogHelper.current_log_file = LogHelper._get_latest_log_file() socket_handler = logging.handlers.SocketHandler('localhost', logging.handlers.DEFAULT_TCP_LOGGING_PORT)
logging.getLogger().setLevel(logging.DEBUG)
logging.getLogger().addHandler(socket_handler) #
LogHelper.start() except Exception, ex:
LogHelper.print_console_log(logging.FATAL, 'init() exception: %s' % str(ex))
traceback.print_exc() @staticmethod
def start():
if LogHelper.log_process is None:
LogHelper.log_process = Process(target=_log_listener_process, name='LogRecorder', args=(LogHelper.log_format, LogHelper.log_time_format, LogHelper.current_log_file))
LogHelper.log_process.start()
else:
pass @staticmethod
def stop():
if LogHelper.log_process is None:
pass
else:
LogHelper.log_process.terminate()
LogHelper.log_process.join() @staticmethod
def _get_latest_log_file():
latest_log_file = ''
try:
if os.path.exists(LogHelper.current_log_path):
for maindir, subdir, file_name_list in os.walk(LogHelper.current_log_path):
for file_name in file_name_list:
apath = os.path.join(maindir, file_name)
if apath > latest_log_file:
latest_log_file = apath if latest_log_file == '':
latest_log_file = LogHelper.current_log_path + os.sep + 'system_'
latest_log_file += time.strftime("%Y%m%d_%H%M%S", time.localtime(time.time())) + '.log' except Exception, ex:
logging.error('EXCEPTION: %s' % str(ex))
traceback.print_exc() finally:
return latest_log_file @staticmethod
def get_log_file():
return LogHelper.current_log_file @staticmethod
def clear_old_log_files():
if not os.path.exists(LogHelper.current_log_path):
logging.warning('clear_old_log_files() Not exist: %s' % LogHelper.current_log_path)
return try:
for maindir, subdir, file_name_list in os.walk(LogHelper.current_log_path):
for file_name in file_name_list:
apath = os.path.join(maindir, file_name)
if apath != LogHelper.current_log_file:
logging.info('DEL -> %s' % str(apath))
os.remove(apath)
else:
with open(LogHelper.current_log_file, 'w') as f:
f.write('') logging.debug('Clear log done.') except Exception, ex:
logging.error('EXCEPTION: %s' % str(ex))
traceback.print_exc()
Python中logging在多进程环境下打印日志的更多相关文章
- Python 中 logging 日志模块在多进程环境下的使用
因为我的个人网站 restran.net 已经启用,博客园的内容已经不再更新.请访问我的个人网站获取这篇文章的最新内容,Python 中 logging 日志模块在多进程环境下的使用 使用 Pytho ...
- Python中logging模块的基本用法
在 PyCon 2018 上,Mario Corchero 介绍了在开发过程中如何更方便轻松地记录日志的流程. 整个演讲的内容包括: 为什么日志记录非常重要 日志记录的流程是怎样的 怎样来进行日志记录 ...
- python中logging模块的用法
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误.警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,loggin ...
- 尚学python课程---11、linux环境下安装python注意
尚学python课程---11.linux环境下安装python注意 一.总结 一句话总结: 准备安装依赖包:zlib.openssl:yum install zlib* openssl*:pytho ...
- 重写NSLog,Debug模式下打印日志和当前行数
在pch文件中加入以下命令,NSLog在真机测试中就不会打印了 //重写NSLog,Debug模式下打印日志和当前行数 #if DEBUG #define NSLog(FORMAT, ...) fpr ...
- python中logging模块的一些简单用法
用Python写代码的时候,在想看的地方写个print xx 就能在控制台上显示打印信息,这样子就能知道它是什么了,但是当我需要看大量的地方或者在一个文件中查看的时候,这时候print就不大方便了,所 ...
- python中logging模块使用
1.logging模块使用场景 在写程序的时候,尤其是大型的程序,在程序中加入日志系统是必不可少的,它能记录很多的信息.刚刚接触python的时候肯定都在用print来输出信息,这样是最简单的输出,正 ...
- python中logging的使用
什么是日志: 日志是一种可以追踪某些软件运行时所发生事件的方法 软件开发人员可以向他们的代码中调用日志记录相关的方法来表明发生了某些事情 一个事件可以用一个可包含可选变量数据的消息来描述 此外,事件也 ...
- Python中的输入(input)和输出打印
目录 最简单的打印 打印数字 打印字符 字符串的格式化输出 python中让输出不换行 以下的都是在Python3.X环境下的 使用 input 函数接收用户的输入,返回的是 str 字符串 最简单的 ...
随机推荐
- 带你了解HTTP协议(一)
本篇文章篇幅比较长,先来个思维导图预览一下. 一张图带你看完本篇文章 一.概述 1.计算机网络体系结构分层 计算机网络体系结构分层 2.TCP/IP 通信传输流 利用 TCP/IP 协议族进行 ...
- python下载后出现python 已停止工作
背景: 在执行IDLE或者在terminal窗口执行 python命令时出现如下提示,修改了防火墙关闭也不行,找不到解决办法? 如图: [解决方案] 1.卸载重装python,确保python版本与系 ...
- $.extend和$.fn.extend详解
一.定义 $.extend()属于j全局的Query对象,用于将一个或多个对象合并到目标对象上: $.fn.extend()属于jQuery的原型对象,用于在jQuery原型上扩展实例属性和方法. 二 ...
- (转) hive调优(2)
hive 调优(二)参数调优汇总 在hive调优(一) 中说了一些常见的调优,但是觉得参数涉及不多,补充如下 1.设置合理solt数 mapred.tasktracker.map.tasks.maxi ...
- p2p通信原理及实现
1.简介 当今互联网到处存在着一些中间件(MIddleBoxes),如NAT和防火墙,导致两个(不在同一内网)中的客户端无法直接通信.这些问题即便是到了IPV6时代也会存在,因为即使不需要NAT,但还 ...
- c3p0数据库连接池 原创: Java之行 Java之行 5月8日 一、连接池概述 实际开发中“获得连接”或“释放资源”是非常消耗系统资源的两个过程
c3p0数据库连接池 原创: Java之行 Java之行 5月8日 一.连接池概述 实际开发中“获得连接”或“释放资源”是非常消耗系统资源的两个过程 DB连接池HikariCP为什么如此快 原创: D ...
- 遇到多个构造器参数时要考虑用构建器 builder 模式 JavaBean 线程安全
effective java p9 JavaBeans模式阻止了把类做成不可变的可能,这需要程序员付出额外的努力来确保它的线程安全.
- word excel 未响应
前几天笔记本突然出现word 一打开就未响应的情况,导致完全无法使用.今天发现 excel 也出现了这种情况.今天终于下定决心解决这个问题. 百度上搜索了很多,找到了很多解决方案.总结如下. 一.禁用 ...
- Android:ART 优化配置(Mstar-6A648)
1.Android预优化的原理 先来回顾一下Android的发展史,在2014年的Google I/O大会上,Google隆重的发布了Android 4.4操作系统,其中有一个环节着重介绍了ART(A ...
- alpha测试和beta测试的区别是什么?
1.测试时间不同: Beta测试是软件产品完成了功能测试和系统测试之后,在产品发布之前所进行的软件测试活动,它是技术测试的最后一个阶段. alpha测试简称“α测试”,可以从软件产品编码结束之时开始, ...