最简单之安装hadoop单机版
一,hadoop下载
(前提:先安装java环境)
下载地址:http://hadoop.apache.org/releases.html(注意是binary文件,source那个是源码)
二,解压配置
tar xzvf hadoop-2.10..tar.gz
[root@--- hadoop-2.10.]# echo $JAVA_HOME
/usr/java/jdk1..0_231-amd64
[root@--- hadoop-2.10.]# vi /home/hadoop-2.10./etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1..0_231-amd64
[root@192-168-22-220 hadoop-2.10.0]# vi /home/hadoop-2.10.0/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
[root@--- hadoop-2.10.]# hostname
---
[root@--- ~]# mkdir /home/hadoop-2.10./tmp
[root@--- ~]# vi /home/hadoop-2.10./etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop-2.10./tmp</value>
</property>
</configuration>
[root@--- hadoop-2.10.]# mkdir /home/hadoop-2.10./hdfs
[root@--- hadoop-2.10.]# mkdir /home/hadoop-2.10./hdfs/name
[root@--- hadoop-2.10.]# mkdir /home/hadoop-2.10./hdfs/data
[root@--- hadoop-2.10.]# vi /home/hadoop-2.10./etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop-2.10./hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property> <property>
<name>dfs.data.dir</name>
<value>/home/hadoop-2.10./hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property> <property>
<name>dfs.replication</name>
<value></value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
[root@--- hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@--- hadoop]# vi /home/hadoop-2.10./etc/hadoop/mapred-site.xml <configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[root@--- hadoop]#vi /home/hadoop-2.10./etc/hadoop/yarn-site.xml
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
三,环境变量
vi /etc/profile
export HADOOP_HOME=/home/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin
source /etc/profile
四,免密登陆
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod ~/.ssh/authorized_keys
五,第一次先格式化hdfs
[root@--- hadoop-2.10.]# pwd
/home/hadoop-2.10.
[root@--- hadoop-2.10.]# ./bin/hdfs namenode -format #或者 hadoop namenode -format
六,启动hdfs
./sbin/start-dfs.sh #启动命令
./sbin/stop-dfs.sh #停止命令
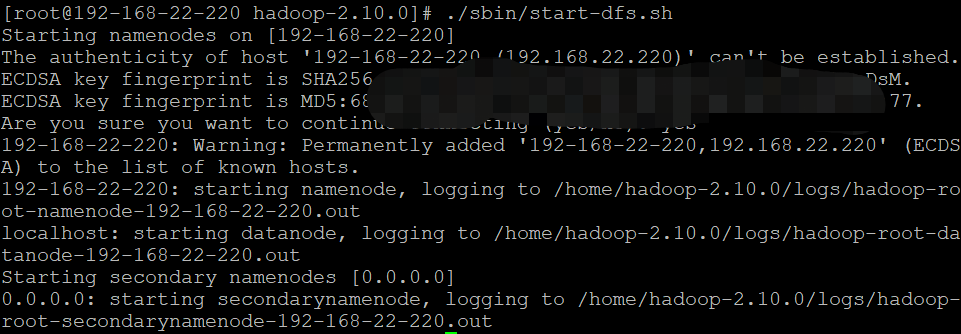
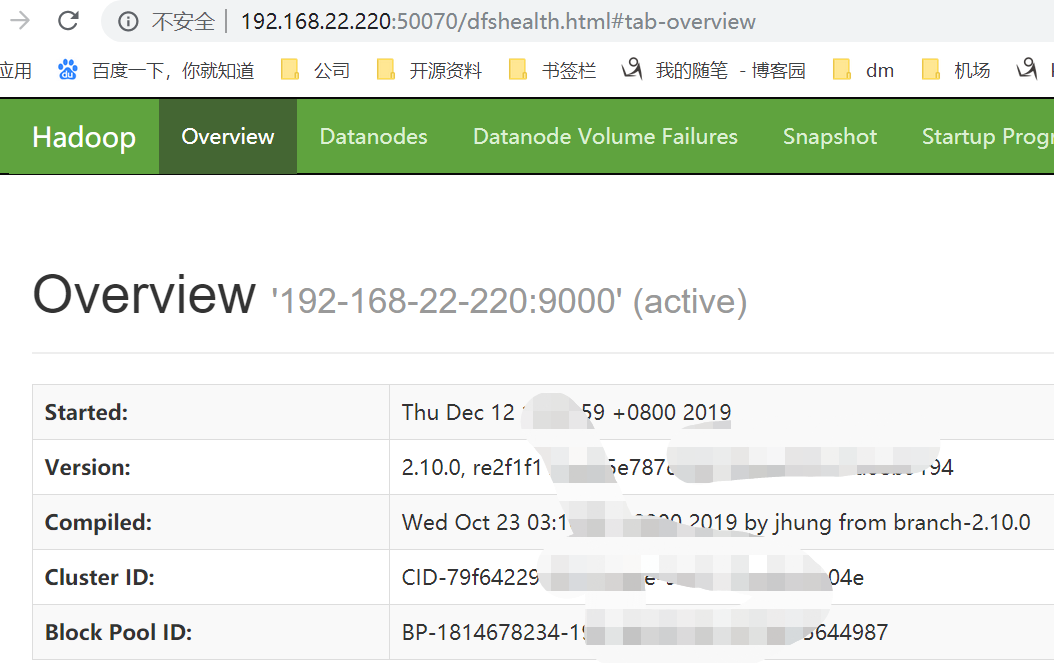
七,启动yarn
[root@--- hadoop-2.10.]# pwd
/home/hadoop-2.10.
[root@--- hadoop-2.10.]# ./sbin/start-yarn.sh # 关闭命令:./sbin/stop-yarn.sh
starting yarn daemons
resourcemanager running as process . Stop it first.
localhost: starting nodemanager, logging to /home/hadoop-2.10./logs/yarn-root-n
odemanager----.out
[root@--- hadoop-2.10.]# jps
NameNode
ResourceManager
Jps
DataNode
SecondaryNameNode
NodeManager
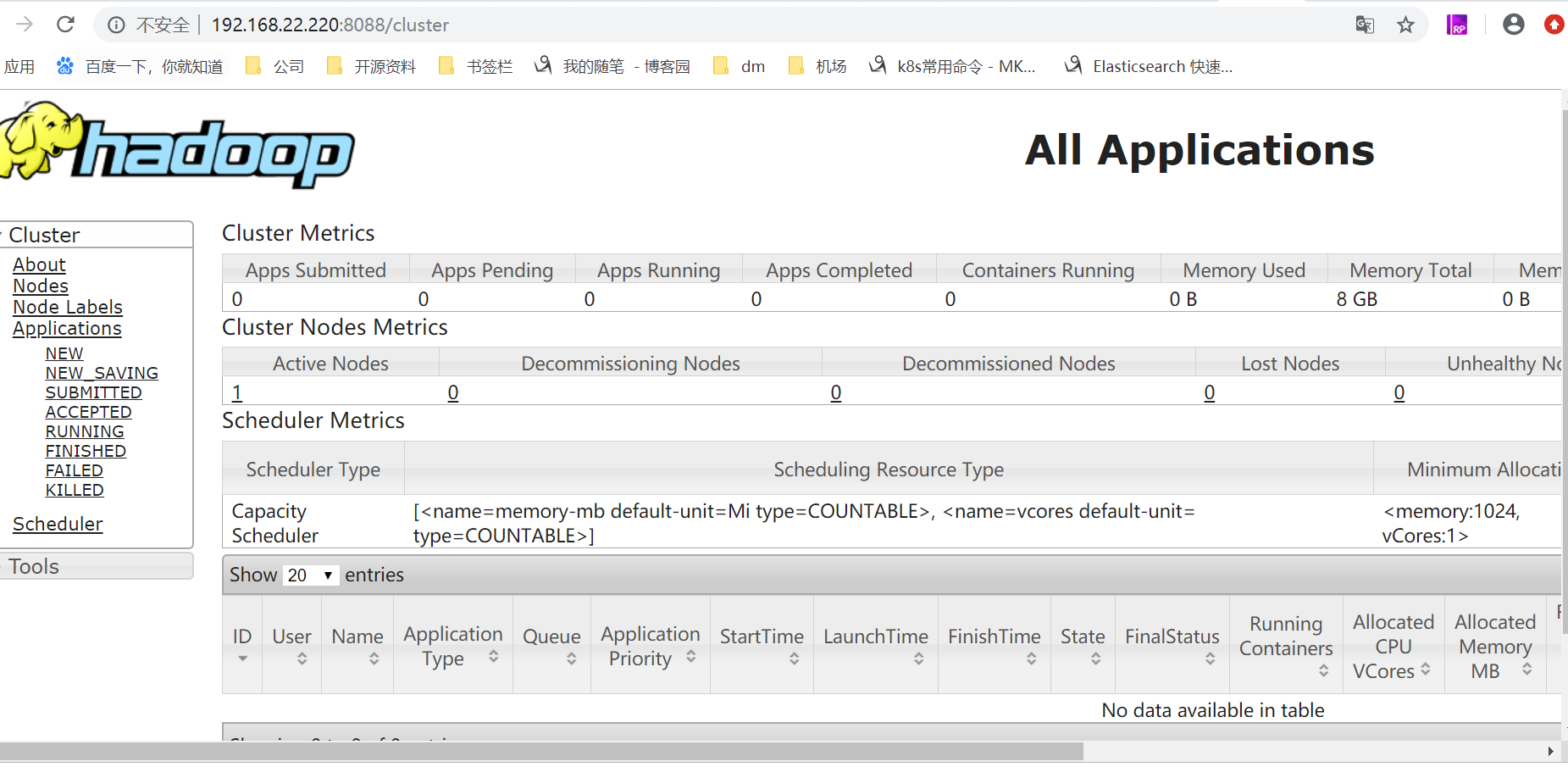
八,批量启动和停止
[root@--- hadoop-2.10.]# ./sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [---]
---: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
localhost: nodemanager did not stop gracefully after seconds: killing with kill -
no proxyserver to stop
[root@--- hadoop-2.10.]# ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [---]
---: starting namenode, logging to /home/hadoop-2.10./logs/hadoop-root-namenode----.out
localhost: starting datanode, logging to /home/hadoop-2.10./logs/hadoop-root-datanode----.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop-2.10./logs/hadoop-root-secondarynamenode----.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop-2.10./logs/yarn-root-resourcemanager----.out
localhost: starting nodemanager, logging to /home/hadoop-2.10./logs/yarn-root-nodemanager----.out
最简单之安装hadoop单机版的更多相关文章
- ambari快速安装hadoop
资源下载http://www.cnblogs.com/bfmq/p/6027202.html 大家都知道hadoop包含很多的组件,虽然很多都是下载后解压简单配置下就可以用的,但是还是耐不住我是一个懒 ...
- Hadoop单机版安装,配置,运行
Hadoop是最近非常流行的东东啦,但是乍一看都觉得是集群的东东,其实在单机版上安装Hadoop也是可以的,并且安装好以后可以很方便的进行程序的调试,调试好程序以后再丢到集群中,放心的算吧,呵呵.. ...
- hadoop单机版安装及基本功能演示
本文所使用的Linux发行版本为:CentOS Linux release 7.4.1708 (Core) hadoop单机版安装 准备工作 创建用户 useradd -m hadoop passwd ...
- CentOS下安装hadoop
CentOS下安装hadoop 用户配置 添加用户 adduser hadoop passwd hadoop 权限配置 chmod u+w /etc/sudoers vi /etc/sudoers 在 ...
- Linux下安装Hadoop完全分布式(Ubuntu12.10)
Hadoop的安装非常简单,可以在官网上下载到最近的几个版本,最好使用稳定版.本例在3台机器集群安装.hadoop版本如下: 工具/原料 hadoop-0.20.2.tar.gz Ubuntu12.1 ...
- Ubuntu安装Hadoop与Spark
更新apt 用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了.按 ctrl+alt+t 打开终端窗口,执行如下命令: sudo a ...
- 在Ubuntu上单机安装Hadoop
最近大数据比较火,所以也想学习一下,所以在虚拟机安装Ubuntu Server,然后安装Hadoop. 以下是安装步骤: 1. 安装Java 如果是新机器,默认没有安装java,运行java –ver ...
- [Hadoop]如何安装Hadoop
Hadoop是一个分布式系统基础架构,他使得用户可以在不了解分布式底层细节的情况下,开发分布式程序. Hadoop的重要核心:HDFS和MapReduce.HDFS负责储存,MapReduce负责计算 ...
- Ubuntu 安装hadoop 伪分布式
一.安装JDK : http://www.cnblogs.com/E-star/p/4437788.html 二.配置SSH免密码登录1.安装所需软件 sudo apt-get ins ...
随机推荐
- 【FFMPEG】使用ffmpeg类库打开流媒体
版权声明:本文为博主原创文章,未经博主允许不得转载. 使用ffmpeg类库进行开发的时候,打开流媒体(或本地文件)的函数是avformat_open_input(). 其中打开网络流的话,前面要加上函 ...
- 论文阅读 | TextBugger: Generating Adversarial Text Against Real-world Applications
NDSS https://arxiv.org/abs/1812.05271 摘要中的创新点确实是对抗攻击中值得考虑的点: 1. effective 2. evasive recognized b ...
- 01trie
前置芝士 二进制,tire 平衡树 一种数据结构,来维护一些数,需要支持以下操作: 1.插入 xx 数 2.删除 xx 数(若有多个相同的数,因只删除一个) 3.查询 xx 数的排名(排名定义为比当前 ...
- Centos 7 忘记密码的情况下,修改root密码
应用场景 linux管理员忘记root密码,需要进行找回操作. 注意事项:本文基于centos7.4环境进行操作,由于centos的版本是有差异的,继续之前请确定好版本 操作步骤 一.重启系统,在开机 ...
- Hadoop集群搭建-04安装配置HDFS
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- 在Hadoop中ResourceManager是干什么的?
[学习笔记] 1)ResourceManager:马克-to-win @ 马克java社区:防盗版实名手机尾号:73203.当应用程序对集群资源需求时,ResourceManager是Yarn集群主控 ...
- array_merge与数组加
array_merge() 索引数组:值不会覆盖,会重新索引; 关联数组:相同的键名,则最后的元素会覆盖其他元素. 数组+ 以左为主,按键加; Array ( [0] => A006 ) + A ...
- Python 字符串,元祖,列表之间的转换
1.字符串是 Python 中最常用的数据类型.我们可以使用引号('或")来创建字符串. 创建字符串很简单,只要为变量分配一个值即可.例如: var1 = 'Hello World!' 2. ...
- scoket模块 粘包问题 tcp协议特点 重启服务器会遇到地址被占用问题
scoket()模块函数用法 import socket socket.socket(socket_family,socket_type,protocal=0) 获取tcp/ip套接字 tcpsock ...
- 并不对劲的复健训练-CF1187D
题目大意 有两个长度为\(n\)的序列\(a_1,...,a_n\),\(b_1,...,b_n\)(\(a,b\leq n\leq 3\times 10^5\) ).一次操作是选取 \([l,r]\ ...