14、RALM: 实时 look-alike 算法在推荐系统中的应用
转载:https://zhuanlan.zhihu.com/p/71951411
RALM: 实时 look-alike 算法在推荐系统中的应用
0. 导语
本论文题为《Real-time Attention based Look-alike Model for Recommender System》,作者 Yudan Liu, Kaikai Ge, Xu Zhang, Leyu Lin,已被 KDD 19 接收,原文见附录。
Look-alike 是广告领域经典的推荐算法,拥有定向能力强、用户扩展精准等优点。本文在微信看一看的推荐场景下对传统 look-alike 进行了改造,使之更适合高时效性的资讯推荐系统。

微信看一看面向全体微信用户,每天有数百万新闻、视频和公众号文章借由个性化推荐系统完成分发。在微信看一看,我们将各类深度学习算法广泛应用到了推荐系统的各个环节中。新闻资讯、运营专题和小众文章由于缺少历史行为或者倾向长尾,往往曝光效率不高,对此我们提出 RALM 模型尝试解决这个问题。
1. 背景
1.1. 未被缓解的马太效应
现阶段,Deep Learning已经在推荐领域中广泛应用,深度模型如 Youtube DNN/WND/DeepFM 等在传统的个性化召回/CTR排序都取得了不错的效果,但仍有一些覆盖效果不佳的场景。对于传统的推荐模型来说,item 的历史行为特征对于 pCTR 的影响很大,这也造成模型推荐结果总体趋热(当然大多数场景下热文是大家都爱看的)。因此而来的副作用就是内容体系的马太效应没有得到充分缓解,一些优质的长尾内容,比如运营新闻专题、冷门类目精品等受到打压,无法得到高效的投放。
要解决这个问题,我们不妨思考传统推荐模型的建模思路,大致如下:
- 获取样本:user, item, label。这里以资讯推荐举例,label即是否点击(0/1)。注意,这条样本是最原始的信息,包含这一行为的所有信息量;
- 拆解特征:直接使用行为样本信息损失当然是最低的,但那意味着失去泛化性。所以我们需要引入用户画像、语义信息、统计信息作为user/item的表达;
- 训练权重:拟合样本,学习各特征权重
由上可以看到,从1到2有一个信息损失的过程。特别是对于item的历史行为信息,并没有很完整的表示方式。传统模型里一个 point-wise 的样本用 itemid、统计信息(历史点击率/点击次数/标签点击率等等)表征 item 行为,但无论是 itemid 还是点击率/点击次数,都是倾向于头部历史行为丰富 item 的特征,这也是为什么前文说的马太效应未被缓解。
1.2. Look-alike Model
综上所述,我们需要的是一个能精准建模 item 历史行为的模型。Look-alike 是广告领域流行的一类方法,其核心思想是针对某个 item,先根据历史行为圈定一部分种子用户,然后通过模型寻找与种子用户相似的人群,为他们推荐该 item。
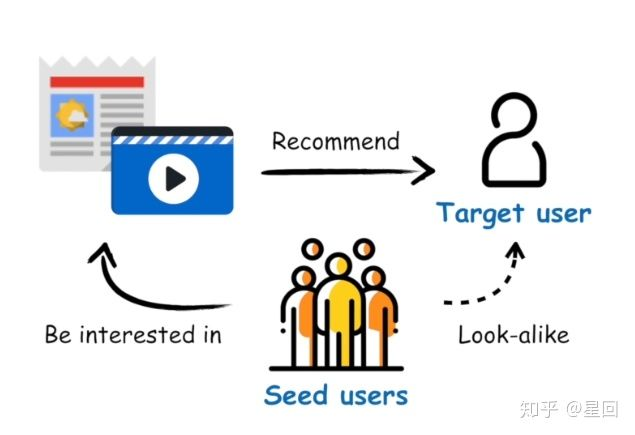
由于 look-alike 充分利用了 item 的所有行为信息,因此在定向挖掘长尾内容受众上具有独特的优势。然而相较于广告系统,我们的资讯推荐有如下差异:
- 内容时效性要求高,一条新闻投放资讯生命周期一般不超过一天。
- 候选集更新频率高,一天可能有几十上百万条新内容出现。
传统的广告 look-alike 包括 similarity based models (LSH/user embedding) 和 regression based models (LR/xgboost/MLP),在广告系统中都得到过验证,但不太适用于资讯推荐。这些模型往往都是针对每个 item 训练一个模型(或者每个 itemid 训练一个 embedding) ,当 item 候选集增加时,模型都需要首先积累样本,然后重训或增量更新,这对于高时效性高频率更新的资讯推荐系统来说是难以接受的。
总结下来,我们最后需要的模型应具备如下特点:
- 实时扩展用户,无需更新模型,让资讯第一时间触达受众;
- 保证推荐的准确性和多样性;
- 支持在线预测、
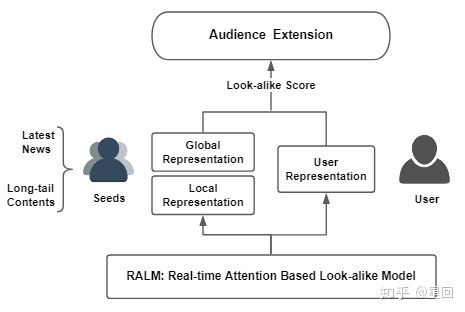
基于以上,我们提出了 RALM(Realtime Attention-based Look-alike Model) 模型,它通过 user representation learning 表达用户的兴趣状态,通过 Look-alike learning 学习种子用户群体信息以及目标用户与种子用户群的相似性,从而实现实时且高效的受众用户扩展和内容触达。
2. 模型
RALM 模型能实现实时扩散的核心在于,我们使用种子用户的特征来代替 item 的历史行为特征,从而将常规 user-item 的模型转换成了 user-users 模型,这意味着任何在系统中有过行为的 item ,都能被表示为 I = Eseeds= f({E(u1), E(u2), ..., E(un)}),其中 un ∈ U,U 为系统用户全集;Eseeds 是 item 种子用户集合的表示。
RALM 的训练包含两部分:User Representation learning 和 Look-alike learning。User Representation learning 的任务是学习E(un);Look-alike learning 的任务则是基于 E(un) 学习 Eseeds。
2.1. User Representation learning
User Representation learning 的任务是学习用户的高阶表示,目的是对繁杂的多域低阶特征做抽象,尽可能全面地表达用户在系统中的状态,便于后续模型的利用。这里可以是个多任务学习,或者输出不同向量空间的多个 embeddings。
我们改进了 Youtube DNN 模型,针对点击样本训练了一版模型,取最后一层隐层作为用户行为 embedding,供后续使用。模型细节计划在CF优化专题里详细说明,在此不再赘述。
2.2. Look-alike learning
从 User Representation learning 得到 user embedding 后,我们将其作为 user 特征,学习种子用户到目标用户的关系,即上文提到的 user-users model。
模型结构

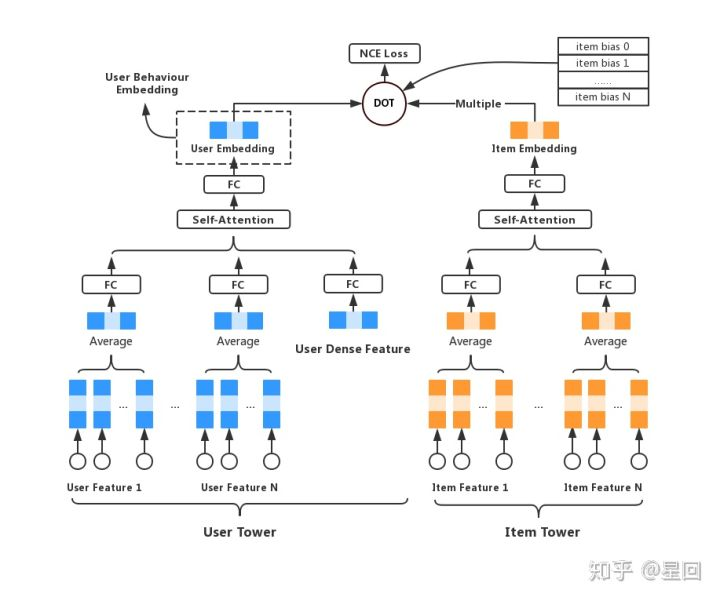
模型结构比较简单,是一个双塔结构。左边称为“seeds tower”,以种子用户的 embeddings 作为输入,经过一层空间转换(全连接+pRELU),然后分别经过一个 self-attention 单元和一个 productive attention 单元,pooling 后输出向量;模型右边结构称为“target tower”,目标用户 embedding 输入后经过空间转换(与seeds tower共享参数),直接与左边向量计算 cosine 相似度。
Local attention
为了计算种子用户群体和目标用户的相似度,我们需要首先把多个用户向量 pooling 成一条。Average 是常用的 pooling 方式,但取均值的结果是趋向群体的中心,也就是大众化的兴趣,丢失了群体中的离群点和个性化兴趣。而一个群体中,必然只有一部分用户是和目标用户兴趣相仿的。基于这些假设,我们加入了 local attention unit,激活种子用户群的局部兴趣点,并且学习到一个和目标用户紧密关联的用户群表达方式,公式如下:

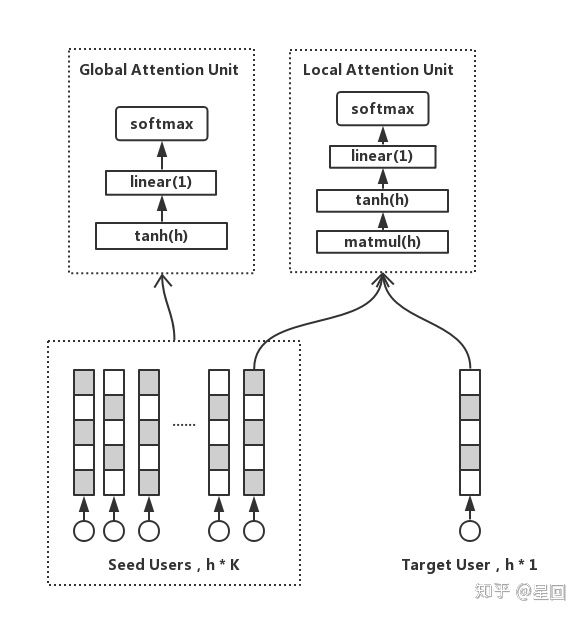
这是一个乘法注意力,Wl ∈ Rhxh 表示转换矩阵,Es 表示种子用户,Eu 表示目标用户,Elocal 为种子用户的 local info。
当 item 有 n 个种子用户时,计算 attention 需要 n * h * h 次乘法计算,当 n 很大时,计算耗时也会水涨船高,不利于在线预测。为了减少计算次数,我们在这引入聚类。我们用 K-means 把种子用户聚成 k 个类簇,然后令种子用户向量按最近类簇中心聚合成 k 个向量,最后再计算 attention。这样一来,计算次数就从 n * h * h 减少至 k * h * h,k 只是一个很小的常数。在我们的实践中,k 取 20 是性能与效果的最佳折中点。注意,由于 attention 前的空间转换矩阵是可学习的,所以输入向量也是会变的,因此最好每隔一定 batch 数迭代更新 K-means 的 k 个聚类中心,减少聚类带来的信息损失。
Global attention
除了个性化信息,用户群体还有共性的、与自身组成相关的全局信息。因此我们引入 global attention unit 来捕获这部分群体信息。
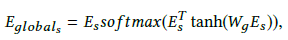
Wg ∈ Rsxn 表示全连接矩阵,Eglobal 为种子用户的 global info。本质上这是一个 self-attention,与群体分布更相似的兴趣将会被提取出来。最终我们令 Elocal , Eglobal 分别与 Eu 求 cosine,加权求和即得到目标用户与种子用户的相似度分数。
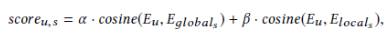
Loss
RALM 是个多分类任务(目标用户属于哪一个种子用户群),我们用 negative sampling 的方式采多正多反(点击item的种子用户做正例,随机采负例),使用多组交叉熵作为模型 loss 函数。
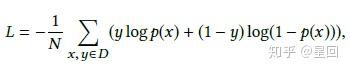
3. 系统架构
RALM 模型框架现在已经部署在微信看一看,整体流程如下:
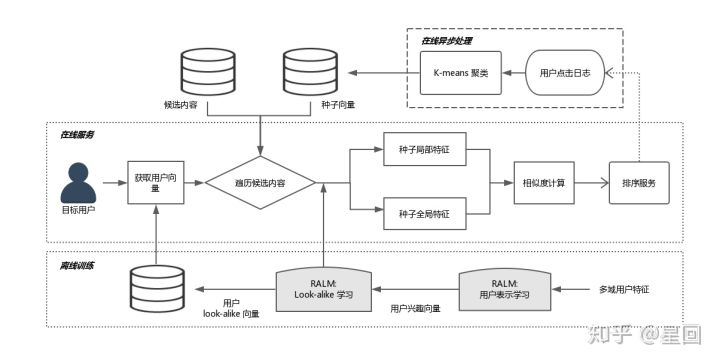
3.1. 离线训练
离线训练包括 User Representation learning 和 Look-alike learning,最终输出 look-alike 模型参数和 Eu。模型参数可加载到内存,全量用户的 Eu 可存到 kv cache。
3.2. 在线异步处理
在线异步处理主要是针对需要快速更新的数据进行准实时的更新和计算,节约线上请求耗时。包括两部分:拉取用户点击日志,更新线上候选集 item 的种子用户,预计算 Elocal(因为这部分与目标用户无关);计算 K-means 类簇中心。以上两部分通过词典系统推送到线上内存。
3.3. 在线服务
线上服务首先拉取当前请求 user 的 Eu,然后遍历候选集 item,分别得到各 item 的种子用户 embedding,计算 local/global attention(已预计算),加权得到最终的相似度。相似度分数可以作为后续模型的特征分,也可以通过卡阈值的方式控制曝光。
4. 一些细节和思考
4.1. 特征
在 RALM 中,我们用 user 特征来表示 item,取代 item 的语义、id、统计类特征,一方面可以得到 item 完整的历史行为表达,另一方面对缺乏丰富统计特征的 item 更加友好。
对于用户,我们用高阶连续特征作为用户特征,而没有使用用户的其他离散特征。是因为如果用低阶特征来表达用户群体,那么我们只能采取统计的方式来构造特征,这会丢失群体大部分信息。而经过表示学习的高阶特征其实已经包含了用户各类低阶特征的交叉,能更加全面地表达用户的信息。并且高阶特征有泛化性,避免表达陷入历史数据的记忆。
4.2. 模型调优
Look-alike learning 的模型很简单,而输入的用户特征又只有一种连续特征,因此很容易受到 User Representation 模型的影响,产生过拟合。我们采取的方式是共享两边全连接层的参数,并且加入 dropout,让模型结构更简单,一定程度上能走得更远。
另外,引入 stacking 的思路,将不同学习目标的其他用户表示 embeddings(如泛兴趣、关系链) concat 作为输入特征,共同训练是我们下一步目标,在 stacking model 中,这也是一个防止模型被带偏、让学习更充分的方法。
4.3. 冷启动曝光
虽然 RALM 计算相似度并不需要太多种子用户,但在 item 初次投放时(种子用户为0),我们仍需多 item 做初始曝光以获得最初的种子用户。线上我们使用语义特征与用户画像做了简单的 MLP 预估点击率作为曝光策略,当积累足够量(100以上)种子用户后即可进入 RALM 的正常预测流程。
5. 总结
RALM 实现了可实时扩展用户的 look-alike 算法,它通过 User Representation learning 和 Look-alike learning 捕捉种子用户群的 local/global 信息,并学习用户群与目标用户的相似度表示,更好地发掘长尾内容的受众用户。通过离线评估和线上 A/B test,RALM 在曝光、CTR、多样性等指标上均取得了更好的效果。注:论文中只用了少量特征学习 representation,效果会打折扣。
附录是 RALM 论文,欢迎大家交流和赐教。
6. 附录
[1].Real-time Attention Based Look-alike Model for Recommender System. https://arxiv.org/abs/1906.05022
14、RALM: 实时 look-alike 算法在推荐系统中的应用的更多相关文章
- 基于Spark机器学习和实时流计算的智能推荐系统
概要: 随着电子商务的高速发展和普及应用,个性化推荐的推荐系统已成为一个重要研究领域. 个性化推荐算法是推荐系统中最核心的技术,在很大程度上决定了电子商务推荐系统性能的优劣,决定着是否能够推荐用户真正 ...
- elasticsearch算法之推荐系统的相似度算法(一)
一.推荐系统简介 推荐系统主要基于对用户历史的行为数据分析处理,寻找得到用户可能感兴趣的内容,从而实现主动向用户推荐其可能感兴趣的内容: 从物品的长尾理论来看,推荐系统通过发掘用户的行为,找到用户的个 ...
- RALM: 实时 Look-alike 算法在微信看一看中的应用
嘉宾:刘雨丹 腾讯 高级研究员 整理:Jane Zhang 来源:DataFunTalk 出品:DataFun 注:欢迎关注DataFunTalk同名公众号,收看第一手原创技术文章. 导读:本次分享是 ...
- SVD在推荐系统中的应用详解以及算法推导
SVD在推荐系统中的应用详解以及算法推导 出处http://blog.csdn.net/zhongkejingwang/article/details/43083603 前面文章SVD原理及推 ...
- 基于Neo4j的个性化Pagerank算法文章推荐系统实践
新版的Neo4j图形算法库(algo)中增加了个性化Pagerank的支持,我一直想找个有意思的应用来验证一下此算法效果.最近我看Peter Lofgren的一篇论文<高效个性化Pagerank ...
- Spark/Scala实现推荐系统中的相似度算法(欧几里得距离、皮尔逊相关系数、余弦相似度:附实现代码)
在推荐系统中,协同过滤算法是应用较多的,具体又主要划分为基于用户和基于物品的协同过滤算法,核心点就是基于"一个人"或"一件物品",根据这个人或物品所具有的属性, ...
- 多维数组分解----SVD在推荐系统中的应用-
http://www.janscon.com/multiarray/rs_used_svd.html [声明]本文主要参考自论文<A SINGULAR VALUE DECOMPOSITION A ...
- NMF和SVD在推荐系统中的应用(实战)
本文以NMF和经典SVD为例,讲一讲矩阵分解在推荐系统中的应用. 数据 item\user Ben Tom John Fred item 1 5 5 0 5 item 2 5 0 3 4 item 3 ...
- RS:推荐系统中的数据稀疏和冷启动问题
如何在没有大量用户数据的情况下设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动问题. 冷启动问题主要分为三类: (1) 用户冷启动:如何给新用户做个性化推荐的问题,新用户刚使 ...
随机推荐
- selenium3 web自动化测试框架 四:Unittest介绍及项目实战中的运用
unittest介绍及运用,可以参考之前写的文章,除了未结合web自动化演示,基础知识都有了 https://www.cnblogs.com/wuzhiming/p/8858305.html unit ...
- Spring 多对对实体
package com.wangshenghua.entity; import java.io.Serializable; import java.util.Set; import javax.per ...
- 按css查询多个元素
示例2 查询多个元素 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <!DOC ...
- Net上传文件
Net上传文件 最近工作内容涉及到一点前端的内容,把学习到的内容记录下来,在今后的开发过程中,不要犯错.本篇只针对一些刚入职的小白及前端开发人员,大牛请绕道!~ 刚开始我们先不讲上传文件的防范问题,先 ...
- 获取radio点击事件
获取radio点击事件,不能用click(),而是用change(). $('input[name="options"]').change(function(){ console. ...
- js 实现数字格式化(货币格式)几种方法
// 方法一 function toThousands(num) { var result = [ ], counter = 0; num = (num || 0).toString().split( ...
- [转帖]删除一张大表时为什么undo占用空间接近原表两倍?
删除一张大表时为什么undo占用空间接近原表两倍? https://www.toutiao.com/i6736735016492990983/ 原创 波波说运维 2019-09-22 00:01:00 ...
- kubernetes ingress 在物理机上的nodePort和hostNetwork两种部署方式解析及比较
ingress controller在物理机上的两种部署方式 ingress controller(ingress-nginx)负责k8s中的7层负载均衡.其在物理机中有多种部署方式.本文中主要选择了 ...
- 《Mysql 事务 - 隔离》
一:事务概念 - ACID(Atomicity.Consistency.Isolation.Durability,即原子性.一致性.隔离性.持久性) 二:事务产生的问题 - 多个事务同时执行的时候 ...
- zabbix硬件监控以及服务
大家好今天给大家带来zabbix3.4.8监控主机,那么最近由于我个人的关系.没有及时的更新文章所以,很抱歉那么今天我分享的内容是zabbix3.4.8监控服务器.本章的具体监控服务器如下: 服务器的 ...