基于Hadoop伪分布式集群搭建Spark
一、前置安装
1)JDK
2)Hadoop伪分布式集群
二、Scala安装
1)解压Scala安装包
2)环境变量
SCALA_HOME = C:\ProgramData\scala-2.10.6
Path = %SCALA_HOME%\bin
3)测试
三、Spark安装
1)解压Spark安装包
2)环境变量
SPARK_HOME = C:\ProgramData\spark-1.6.-bin-hadoop2.
Path = %SPARK_HOME%\bin
3)测试
http://localhost:4040/jobs/

四、运行wordcounut程序
1)启动Hadoop集群
cd C:\ProgramData\hadoop-2.7.\sbin
C:\ProgramData\hadoop-2.7.\sbin>start-all.cmd
C:\ProgramData\hadoop-2.7.\sbin>jps
2)创建word.txt

3.1)读取Hadoop的HDFS文件运行WordCount
1、上传word.txt到Hdfs
hadoop fs -put C:\Projects\WordCount\word.txt /Demo/word.txt
2、启动spark-shell
3、输入Scala命令
sc.textFile("hdfs://localhost:9000/Demo/word.txt").flatMap(x => x.split("\t")).map(x=>(x,1)).reduceByKey(_+_).collect()



3.2)读取本地文件运行WordCount
1、启动spark-shell
2、输入Scala命令
sc.textFile("file:///C:/Projects/WordCount/word.txt").flatMap(x => x.split("\t")).map(x=>(x,)).reduceByKey(_+_).collect()


五、Spark部署运行
cmd --> spark-submit(无需spark-shell)
spark-submit --executor-memory 1G --num-executors 8 --class main.MrDemo D:\Projects\IdeaProjects\MyTest\out\artifacts\MyTest_jar\MyTest.jar 2018072712

六、Python下Spark开发环境搭建(PySpark)
Blog:https://www.cnblogs.com/guozw/p/10046156.html
1)安装Anaconda3-2019.03-Windows-x86_64(python 3.7.3)
2)下载spark-2.4.2-bin-hadoop2.7.tgz,解压,然后将spark目录下的pyspark文件夹(C:\ProgramData\spark-2.4.2-bin-hadoop2.7\python\pyspark)复制到python安装目录(C:\ProgramData\Anaconda3\Lib\site-packages)里
注意:Spark与Python版本要对应 - Python 2.7.5/3.5.2 + Spark 2.2.1 (pip install pyspark==2.2.1);Python 3.7.3 + spark-2.4.2-bin-hadoop2.7.tgz (pyspark 2.4.2)
3)安装py4j:Anaconda Prompt --> 安装py4j库
pip install py4j
4)新建一个PYTHONPATH的系统变量
PATHONPATH=%SPARK_HOME%\python;%SPARK_HOME%\python\lib\py4j-0.9-src.zip
5)PyCharm-->File-->Settings-->Project Interpreter-->Show All-->+-->System Interpreter-->选择:C:\ProgramData\Anaconda3\python.exe
6)PyCharm下编写WordCount测试
1、创建Session
from pyspark.sql import SparkSession
# appName中的内容不能有空格,否则报错
spark = SparkSession.builder.master("local[*]").appName("WordCount").getOrCreate()
#获取上下文
sc = spark.sparkContext
带有空格报错情况如下:

2、创建上下文
# 第一种方式
conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf)
# 第二种方式
sc=SparkContext('local','test')
3、实例
# 实例1 - 读取文件并打印
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf) rdd = sc.textFile('d:/scala/log.txt')
print(rdd.collect())

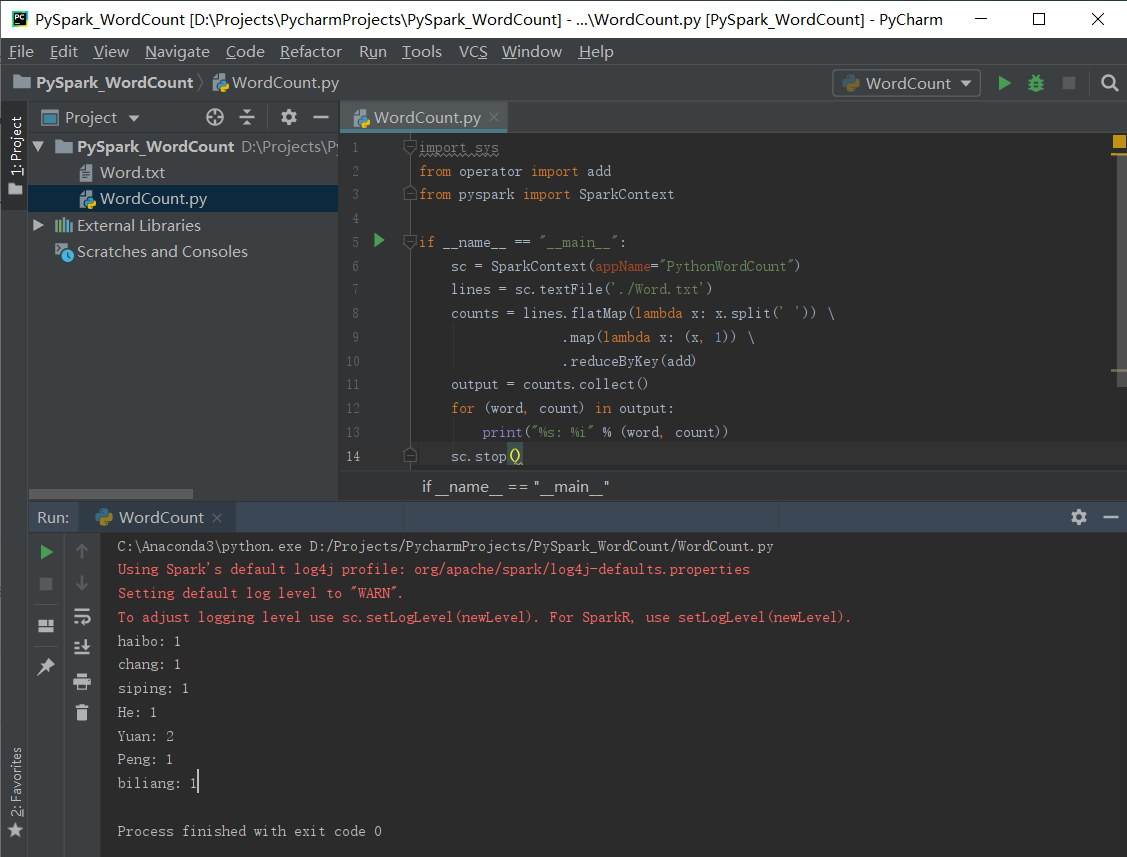
# 实例2 - WordCount
import sys
from operator import add
from pyspark import SparkContext if __name__ == "__main__":
sc = SparkContext(appName="PythonWordCount")
lines = sc.textFile('./Word.txt')
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, )) \
.reduceByKey(add)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
sc.stop()
问题:
Java.util.NoSuchElementException: key not found: _PYSPARK_DRIVER_CALLBACK_HOST
原因:版本不兼容,PySpark的版本与Spark不匹配
解决:查看Spark版本,例如为2.1.0,则使用Pip安装PySpark时,带上版本号
pip install pyspark==2.1.2 # 皆为2.1版本
✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡Anaconda3.7与Anaconda3.5切换✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡
win+R输入cmd进入命令行,跳转到Anaconda的安装目录,然后执行
cd C:\ProgramData\Anaconda3
cd C:\ProgramData\Anaconda3.5
python .\Lib\_nsis.py mkmenus

然后再点击Anaconda Prompt,即切换到当前Python环境
✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡
基于Hadoop伪分布式集群搭建Spark的更多相关文章
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- zookeeper伪分布式集群搭建
zookeeper集群搭建注意点: 配置数据文件myid1/2/3对应server.1/2/3 通过zkCli.sh -server [ip]:[port]检测集群是否 ...
随机推荐
- Linux网络编程一、tcp三次握手,四次挥手
一.TCP报文格式 (图片来源网络) SYN:请求建立连接标志位 ACK:应答标志位 FIN:断开连接标志位 二.三次握手,数据传输,四次挥手 (流程图,图片来源于网络) (tcp状态转换图,图片来源 ...
- js获取用户当前页面复制的内容并修改
如果只是单纯的获取页面上复制的内容可以使用window.getSelection()来获取选中的内容,在执行复制操作就可以了,但是如果想修改复制的内容可以先获取要复制的内容修改之后再用document ...
- Charles中文破解版下载安装及使用教程
下载地址:https://pan.baidu.com/s/1praYZAw23psZLi59hKJjqw 一. 简介及安装 Charles 是在 PC 端常用的网络封包截取工具,但它不仅仅能在pc端使 ...
- POJ2942Knights of the round table
这题第一次做的人一般是颓题解的. 首先我们转化一下问题,既然厌恶的人不能一起出席,是一种不传递关系,我们构建补图,这样补图的边表示两个骑士可以同时出席. 此时,由于只能有奇数个人参加,则我们要找出奇环 ...
- DB 分库分表的基本思想和切分策略
DB 分库分表的基本思想和切分策略 一.基本思想 Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题.不太严格的讲,对于海量数据的 ...
- Maximum upload size exceede上传文件大小超出解决
在这里记录三种方法, 努力提高自己的姿势水平 application.yml配置 spring: servlet: multipart: enabled: true max-file-size: 10 ...
- vue 的多页面应用
vue-cli3 中构建多页面的应用 第一步:先创建一个 vue-cli3 的项目:vue create app 然后运行项目:npm run serve 现在开始多页面的应用: 首先在 src 的目 ...
- koa 基础(二十三)封装 DB 库 --- 应用
1.根目录/module/config.js /** * 配置文件 */ var app = { dbUrl: 'mongodb://127.0.0.1:27017/?gssapiServiceNam ...
- [学习笔记] Tangent Distance
Tangent Distance 简介 切空间距离可以用在KNN方法中度量距离,其解决的是图像经过有限变换之后还能否被分类正确,例如.对一张数字为5的手写数字图片,将其膨胀后得到图像p1,此时KNN还 ...
- java二进制工具
可以运用jdk工具监控java应用性能,再配合 jmeter 进行了一个长时间的加压,在加压过程中重点关注了系统资源的使用情况 D:\Program Files (x86)\Java\jdk1.8.0 ...