聚类算法之K-means
想想常见的分类算法有决策树、Logistic回归、SVM、贝叶斯等。分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应。但是很多时候上述条件得不到满足,尤其是在处理海量数据的时候,如果通过预处理使得数据满足分类算法的要求,则代价非常大,想想如果给你50个G这么大的文本,里面已经分好词,这时需要将其按照给定的几十个关键字进行划分归类,监督学习的方法确实有点困难,而且也不划算,前期工作做得太多了。
这时候可以考虑使用聚类算法,我们只需要知道这几十个关键字是什么就可以了。聚类属于无监督学习,相比于分类,聚类不依赖预定义的类和类标号的训练实例。本文首先介绍聚类的基础——距离与相异度,然后介绍一种常见的聚类算法——K-means聚类。
在正式讨论聚类前,我们要先弄清楚一个问题:如何定量计算两个可比较元素间的相异度。前面的这些知识弄懂了,加上K-means的定义,基本上就可以大概理解K-means的算法了,不算一个特别难的算法。用通俗的话说,相异度就是两个东西差别有多大,例如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能我们直观感受到的。但是,计算机没有这种直观感受能力,我们必须对相异度在数学上进行定量定义。
设X={x1,x2,x3,,,,xn},Y={y1,y2,y3,,,,yn} ,其中X,Y是两个元素项,各自具有n个可度量特征属性,那么X和Y的相异度定义为:d=(X,Y)=f(X,Y)->R,其中R为实数域。也就是说相异度是两个元素对实数域的一个映射,所映射的实数定量表示两个元素的相异度。
下面介绍不同类型变量相异度计算方法。
标量
标量也就是无方向意义的数字,也叫标度变量。现在先考虑元素的所有特征属性都是标量的情况。例如,计算X={2,1,102}和Y={1,3,2}的相异度。一种很自然的想法是用两者的欧几里得距离来作为相异度,欧几里得距离的定义如下:

其意义就是两个元素在欧氏空间中的集合距离,因为其直观易懂且可解释性强,被广泛用于标识两个标量元素的相异度。将上面两个示例数据代入公式,可得两者的欧氏距离为:
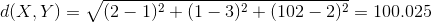
除欧氏距离外,常用作度量标量相异度的还有曼哈顿距离和闵可夫斯基距离,两者定义如下:
曼哈顿距离: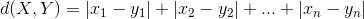
闵可夫斯基距离: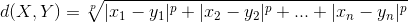
欧氏距离和曼哈顿距离可以看做是闵可夫斯基距离在p=2和p=1下的特例。
0-1规格化
下面要说一下标量的规格化问题。上面这样计算相异度的方式有一点问题,就是取值范围大的属性对距离的影响高于取值范围小的属性。例如上述例子中第三个属性的取值跨度远大于前两个,这样不利于真实反映真实的相异度,为了解决这个问题,一般要对属性值进行规格化。所谓规格化就是将各个属性值按比例映射到相同的取值区间,这样是为了平衡各个属性对距离的影响。通常将各个属性均映射到[0,1]区间,映射公式为:
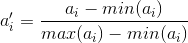
其中max(ai)和min(ai)表示所有元素项中第i个属性的最大值和最小值。例如,将示例中的元素规格化到[0,1]区间后,就变成了X’={1,0,1},Y’={0,1,0},重新计算欧氏距离约为1.732。
二元变量
所谓二元变量是只能取0和1两种值变量,有点类似布尔值,通常用来标识是或不是这种二值属性。对于二元变量,上一节提到的距离不能很好标识其相异度,我们需要一种更适合的标识。一种常用的方法是用元素相同序位同值属性的比例来标识其相异度。
设有X={1,0,0,0,1,0,1,1},Y={0,0,0,1,1,1,1,1},可以看到,两个元素第2、3、5、7和8个属性取值相同,而第1、4和6个取值不同,那么相异度可以标识为3/8=0.375。一般的,对于二元变量,相异度可用“取值不同的同位属性数/单个元素的属性位数”标识。
上面所说的相异度应该叫做对称二元相异度。现实中还有一种情况,就是我们只关心两者都取1的情况,而认为两者都取0的属性并不意味着两者更相似。例如在根据病情对病人聚类时,如果两个人都患有肺癌,我们认为两个人增强了相似度,但如果两个人都没患肺癌,并不觉得这加强了两人的相似性,在这种情况下,改用“取值不同的同位属性数/(单个元素的属性位数-同取0的位数)”来标识相异度,这叫做非对称二元相异度。如果用1减去非对称二元相异度,则得到非对称二元相似度,也叫Jaccard系数,是一个非常重要的概念。
分类变量
分类变量是二元变量的推广,类似于程序中的枚举变量,但各个值没有数字或序数意义,如颜色、民族等等,对于分类变量,用“取值不同的同位属性数/单个元素的全部属性数”来标识其相异度。
序数变量
序数变量是具有序数意义的分类变量,通常可以按照一定顺序意义排列,如冠军、亚军和季军。对于序数变量,一般为每个值分配一个数,叫做这个值的秩,然后以秩代替原值当做标量属性计算相异度。
向量
对于向量,由于它不仅有大小而且有方向,所以闵可夫斯基距离不是度量其相异度的好办法,一种流行的做法是用两个向量的余弦度量,这个应该大家都知道吧,其度量公式为:
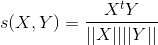
其中||X||表示X的欧几里得范数。要注意,余弦度量度量的不是两者的相异度,而是相似度!
什么是聚类?
所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。
与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域,相应的算法也非常的多。本文仅介绍一种最简单的聚类算法——k均值(k-means)算法。
k均值算法的计算过程非常直观:
1、从D中随机取k个元素,作为k个簇的各自的中心。
2、分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇。
3、根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。
4、将D中全部元素按照新的中心重新聚类。
5、重复第4步,直到聚类结果不再变化。
6、将结果输出。
时间复杂度:O(T*n*k*m)
空间复杂度:O(n*m)
n:元素个数,k:第一步中选取的元素个数,m:每个元素的特征项个数,T:第5步中迭代的次数
参考:
T2噬菌体(很多理解都是借鉴这位大牛的,还在阅读学习TA的其他博文)
聚类算法之K-means的更多相关文章
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 03-01 K-Means聚类算法
目录 K-Means聚类算法 一.K-Means聚类算法学习目标 二.K-Means聚类算法详解 2.1 K-Means聚类算法原理 2.2 K-Means聚类算法和KNN 三.传统的K-Means聚 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- Kmeans算法的K值和聚类中心的确定
0 K-means算法简介 K-means是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一. K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的 ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
随机推荐
- [The Preliminary Contest for ICPC Asia Nanjing 2019] A-The beautiful values of the palace(二维偏序+思维)
>传送门< 前言 这题比赛的时候觉得能做,硬是怼了一个半小时,最后还是放弃了.开始想到用二维前缀和,结果$n\leq 10^{6}$时间和空间上都爆了,没有办法.赛后看题解用树状数组,一看 ...
- CF803G - Periodic RMQ Problem 动态开点线段树 或 离线
CF 题意 有一个长度为n × k (<=1E9)的数组,有区间修改和区间查询最小值的操作. 思路 由于数组过大,直接做显然不行. 有两种做法,可以用动态开点版本的线段树,或者离线搞(还没搞)( ...
- Features Track 2018徐州icpc网络赛 思维
Morgana is learning computer vision, and he likes cats, too. One day he wants to find the cat moveme ...
- [NOI2001]炮兵阵地 题解
题意 我们先来了解一下基本的位运算 于( \(\bigwedge\) ),或 (\(\bigvee\) ) 异或(\(\bigoplus\)) 在下面我们用(&)代表于,(|)代表或 一道状压 ...
- Shiro实现用户对动态资源细粒度的权限校验
前言 在实际系统应用中,普遍存在这样的一种业务场景,需要实现用户对要访问的资源进行动态权限校验. 譬如,在某平台的商家系统中,存在商家.品牌.商品等业务资源.它们之间的关系为:一个商家可以拥有多个品牌 ...
- LeetCode - 字符串数字相乘与相加
43. 字符串相乘 给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式. 示例 1: 输入: num1 = "2& ...
- MySQL 数据库出现导入xls数据出现1062主从错误错误问题解决方案
今天把xls数据表导入MySQL数据库时发现出现1062错误 ,并且有20-700条数据一直导入不了所以开始找解决方案. 解决方案1: 数据库表设计问题导致相同字段的重复数据不能导入 解 ...
- Java,哈希码以及equals和==的区别
从开始学习Java,哈希码以及equals和==的区别就一直困扰着我. 要想明白equals和==的区别首先应该了解什么是哈希码,因为在jdk的类库中不管是object实现的equals()方法还是S ...
- springCloud相关学习资料
SpringCloud相关学习资料 SpringCloud资料参考: 1. 史上最简单的 SpringCloud 教程 | 终章 2. Spring Cloud基础教程 SpringCloud相关: ...
- sql 多行、一行 互转
原始数据: 期望数据: IF OBJECT_ID('temp_20170701','u') IS NOT NULL DROP TABLE temp_20170701 CREATE TABLE temp ...