百万年薪python之路 -- MySQL数据库之 MySQL行(记录)的操作(二) -- 多表查询
MySQL行(记录)的操作(二) -- 多表查询
数据的准备
#建表
create table department(
id int,
name varchar(20)
);
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into department values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204)
;
#查看表结构和数据
mysql> desc department;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
mysql> desc employee;
+--------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(11) | YES | | NULL | |
| dep_id | int(11) | YES | | NULL | |
+--------+-----------------------+------+-----+---------+----------------+
mysql> select * from department;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
mysql> select * from employee;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
表department与employee1. 多表连接查询
# 重点: 外连接表的语法
select 字段列表
from 表1 inner|left|right|join 表2
on 表1.字段 = 表2.字段;1.1 笛卡尔积连接: 不适用任何匹配条件,将多张表所有的数据一一对于对应,生产一张大表.
图示笛卡尔积:
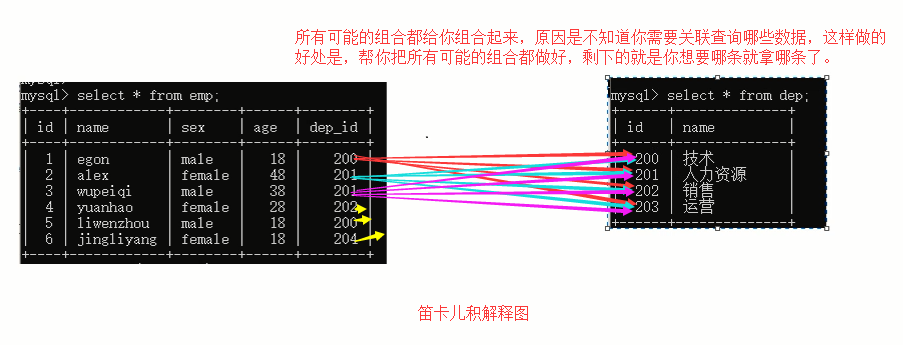
代码表示:
mysql> select * from employee,department;
结果:
+----+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 1 | egon | male | 18 | 200 | 201 | 人力资源 |
| 1 | egon | male | 18 | 200 | 202 | 销售 |
| 1 | egon | male | 18 | 200 | 203 | 运营 |
| 2 | alex | female | 48 | 201 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 2 | alex | female | 48 | 201 | 202 | 销售 |
| 2 | alex | female | 48 | 201 | 203 | 运营 |
| 3 | wupeiqi | male | 38 | 201 | 200 | 技术 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 202 | 销售 |
| 3 | wupeiqi | male | 38 | 201 | 203 | 运营 |
| 4 | yuanhao | female | 28 | 202 | 200 | 技术 |
| 4 | yuanhao | female | 28 | 202 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 4 | yuanhao | female | 28 | 202 | 203 | 运营 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 201 | 人力资源 |
| 5 | liwenzhou | male | 18 | 200 | 202 | 销售 |
| 5 | liwenzhou | male | 18 | 200 | 203 | 运营 |
| 6 | jingliyang | female | 18 | 204 | 200 | 技术 |
| 6 | jingliyang | female | 18 | 204 | 201 | 人力资源 |
| 6 | jingliyang | female | 18 | 204 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | 203 | 运营 |
+----+------------+--------+------+--------+------+--------------+但是我们知道这样的表太过于冗余,根本不是我们想看到的样子.
它应该时这样的:

我们的目标就是将两个分散出去的表,按照两者之间有关系的字段,能对应上的字段,把两者合并成一张表,这就是多表查询的一个本质。
怎么做呢?
来个where条件来筛选不就行了.
select * from employee, department where employee.dep_id = department.id;
结果:
+----+-----------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+-----------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
+----+-----------+--------+------+--------+------+--------------+
这就是我们想要的展现形式.但是有两个问题:
1. 我们左表employee表中的dep_id为204的那个数据没有了,右表department表的id为203的数据没有了,因为我们现在要的就是两表能对应上的数据一起查出来,那个204和203双方对应不上,有些场景可以符合,但还有一些场景就不符合了,如: 我想得到所有人的信息,就算它不属于任何一个职位.
2. 可读性不好,看图:

1.2 内连接: 只连接匹配的行
mysql> select * from employee inner join department on employee.dep_id = department.id where department.name = '技术';
+----+-----------+------+------+--------+------+--------+
| id | name | sex | age | dep_id | id | name |
+----+-----------+------+------+--------+------+--------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
+----+-----------+------+------+--------+------+--------+现在解决了第二个问题,把连表的操作和查询的操作分开了,可读性提高了...
1.3 外连接之左连接: 优先显示左表的全部记录
以左表为准,即找出所有员工信息,当然包括没有部门的员工
#本质就是:在内连接的基础上增加左边有右边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id;
+----+------------+--------------+
| id | name | depart_name |
+----+------------+--------------+
| 1 | egon | 技术 |
| 5 | liwenzhou | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 6 | jingliyang | NULL |
+----+------------+--------------+现在解决第一个问题, 解决一些需要像上方一样的显示.
1.4 外连接之右连接: 优先显示右表全部记录
#以右表为准,即找出所有部门信息,包括没有员工的部门
#本质就是:在内连接的基础上增加右边有左边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id;
+------+-----------+--------------+
| id | name | depart_name |
+------+-----------+--------------+
| 1 | egon | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 5 | liwenzhou | 技术 |
| NULL | NULL | 运营 |
+------+-----------+--------------+1.5 全外连接: 显示左右两表全部记录
全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果
#注意:mysql不支持全外连接 full JOIN
#强调:mysql可以使用此种方式间接实现全外连接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;
#查看结果
+------+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+------+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | 203 | 运营 |
+------+------------+--------+------+--------+------+--------------+
#注意 union与union all的区别:union会去掉相同的纪录,而union all 不会去掉相同的记录.
如:
+------+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+------+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| NULL | NULL | NULL | NULL | NULL | 203 | 运营 |
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | NULL | NULL |
+------+------------+--------+------+--------+------+--------------+2. 子查询
#1:子查询是将一个查询语句嵌套在另一个查询语句中。
#2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
#3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
#4:还可以包含比较运算符:= 、 !=、> 、<等1. 带in关键字的子查询
#查询平均年龄在25岁以上的部门名
select name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
#查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术');
#查看不足1人的部门名(子查询得到的是有人的部门id)
select name from department where id not in (select distinct dep_id from employee);2. 带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<>
#查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from emp where age > (select avg(age) from emp);
+---------+------+
| name | age |
+---------+------+
| alex | 48 |
| wupeiqi | 38 |
+---------+------+
2 rows in set (0.00 sec)
#查询大于部门内平均年龄的员工名、年龄
select t1.name,t1.age from emp t1
inner join
(select dep_id,avg(age) avg_age from emp group by dep_id) t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age; 3. 带exists关键字的子查询
exists关键字表示存在,在使用exists关键字时,内层查询语句不返回查询记录,而是返回一个真假值,True或False.
返回True时,外层查询语句可以运行查询,如果是False时,外层查询语句不运行查询.
#department表中存在dept_id=203,Ture
mysql> select * from employee
-> where exists
-> (select id from department where id=200);
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
#department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
Empty set (0.00 sec)百万年薪python之路 -- MySQL数据库之 MySQL行(记录)的操作(二) -- 多表查询的更多相关文章
- 百万年薪python之路 -- MySQL数据库之 MySQL行(记录)的操作(一)
MySQL的行(记录)的操作(一) 1. 增(insert) insert into 表名 value((字段1,字段2...); # 只能增加一行记录 insert into 表名 values(字 ...
- 百万年薪python之路 -- MySQL数据库之 永久修改字符串编码 与 忘了密码和修改密码
永久修改字符集编码的方法: 在mysql安装目录下创建一个my.ini(Windows下)文件,写入下面的配置,然后重启服务端. [client] #设置mysql客户端默认字符集 default-c ...
- 百万年薪python之路 -- MySQL数据库之 完整性约束
MySQL完整性约束 一. 介绍 为了防止不符合规范的数据进入数据库,在用户对数据进行插入.修改.删除等操作时,DBMS自动按照一定的约束条件对数据进行监测,使不符合规范的数据不能进入数据库,以确保数 ...
- 百万年薪python之路 -- MySQL数据库之 存储引擎
MySQL之存储引擎 一. 存储引擎概述 定义: 存储引擎是mysql数据库独有的存储数据.为数据建立索引.更新数据.查询数据等技术的实现方法 首先声明一点: 存储引擎这个概念只有MySQL才有. ...
- 百万年薪python之路 -- MySQL数据库之 常用数据类型
MySQL常用数据类型 一. 常用数据类型概览 # 1. 数字: 整型: tinyint int bigint 小数: float: 在位数比较短的情况下不精确 double: 在位数比较长的情况下不 ...
- 百万年薪python之路 -- 数据库初始
一. 数据库初始 1. 为什么要有数据库? 先来一个场景: 假设现在你已经是某大型互联网公司的高级程序员,让你写一个火车票购票系统,来hold住十一期间全国的购票需求,你怎么写? 由于在同一时 ...
- 百万年薪python之路 -- 并发编程之 协程
协程 一. 协程的引入 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两 ...
- 百万年薪python之路 -- 面向对象之 反射,双下方法
面向对象之 反射,双下方法 1. 反射 计算机科学领域主要是指程序可以访问.检测和修改它本身状态或行为的一种能力(自省) python面向对象中的反射:通过字符串的形式操作对象相关的属性.python ...
- MySQL数据库(四)—— 记录相关操作之插入、更新、删除、查询(单表、多表)
一.插入数据(insert) 1. 插入完整数据(顺序插入) 语法一: INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n); # 后面的值必须与字段 ...
随机推荐
- opencv之霍夫曼变换
霍夫变换不仅可以找出图片中的直线,也可以找出圆,椭圆,三角形等等,只要你能定义出直线方程,圆形的方程等等. 不得不说,现在网上的各种博客质量真的不行,网上一堆文章,乱TM瞎写,误人子弟.本身自己就没有 ...
- let与var的区别
1.let作用域局限于当前代码块 文章中//后面的均为打印结果 代码1: { var str1 = "小花"; let str2 = "小明"; console ...
- SharePoint 2013 Sandbox Solution
昨天在写SharePoint EventReceiver的时候遇到一个问题,创建了一个local farm SharePoint solution,添加了一个ItemAdded(SPItemEvent ...
- Windows定时备份Mysql数据库
1.新建批处理文件bat(随意命名:如auto_backup_mysql_data.bat) 2.在批处理文件里添加如下命令 %1 mshta vbscript:createobject(" ...
- Ng的数组绑定
tip:数据的定义需要在对应ts中进行,调用在html中 定义数组: ts中 public arr =["111","222","333"] ...
- 关于CSS书写规范、顺序
关于CSS的书写规范和顺序,是大部分前端er都必须要攻克的一门关卡,如果没有按照良好的CSS书写规范来写CSS代码,会影响代码的阅读体验.这里总结了一个CSS书写规范.CSS书写顺序供大家参考,这些是 ...
- centos7 安装 docker
一.概念 1.Docker引擎 (docker engine) 也称docker daemon,也称为docker服务,只要启动服务,就可以通过docker client发送相关docker命名,与d ...
- Knative 暂时不会捐给任何基金会 | 云原生生态周报 Vol. 22
作者 | 新胜.心贵.进超.元毅.衷源 业界要闻 谷歌:不会向任何基金会捐赠 Knative 自 Knative 项目开始以来,一直存在关于是否将 Knative 捐赠给基金会(例如 CNCF)的疑问 ...
- Scala 学习笔记之集合(2)
class StudentTT extends StudentT{ def sayBye(name: String, age: Int)(address: String){ println(" ...
- scalikejdbc 学习笔记(4)
Batch 操作 import scalikejdbc._ import scalikejdbc.config._ object BatchOperation { def main(args: Arr ...