Nebula 架构剖析系列(零)图数据库的整体架构设计
Nebula Graph 是一个高性能的分布式开源图数据库,本文为大家介绍 Nebula Graph 的整体架构。
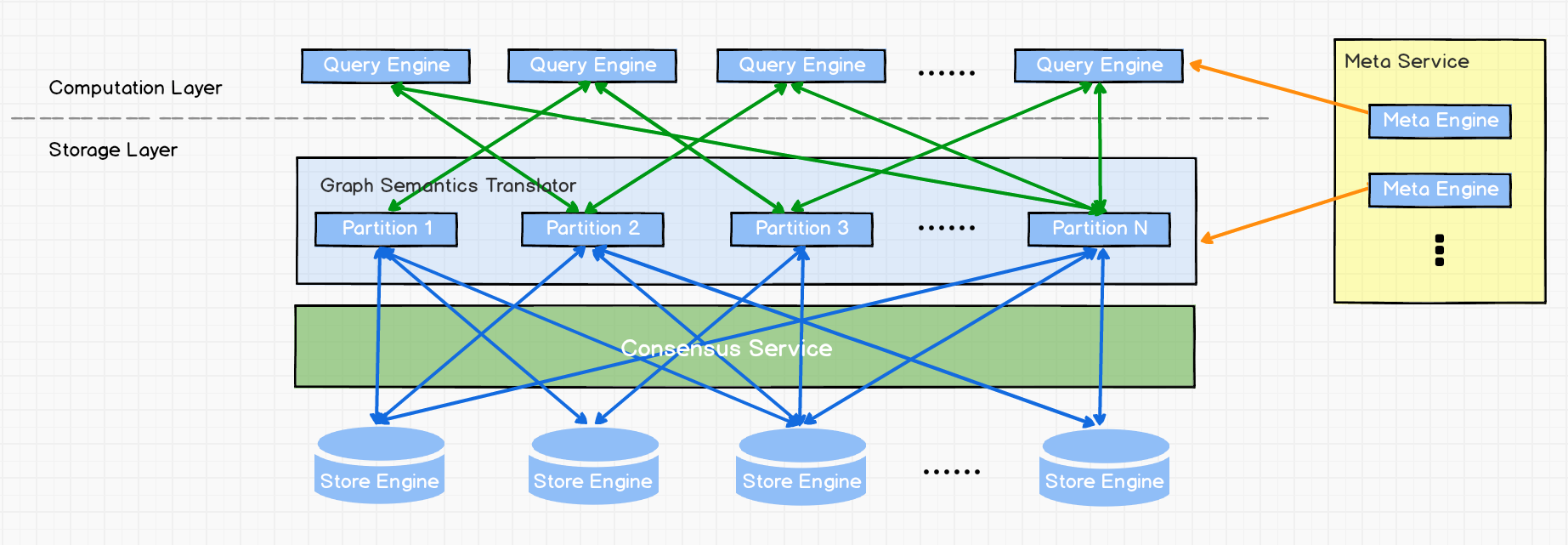
一个完整的 Nebula 部署集群包含三个服务,即 Query Service,Storage Service 和 Meta Service。每个服务都有其各自的可执行二进制文件,这些二进制文件既可以部署在同一组节点上,也可以部署在不同的节点上。
Meta Service
上图为 Nebula Graph 的架构图,其右侧为 Meta Service 集群,它采用 leader / follower 架构。Leader 由集群中所有的 Meta Service 节点选出,然后对外提供服务。Followers 处于待命状态并从 leader 复制更新的数据。一旦 leader 节点 down 掉,会再选举其中一个 follower 成为新的 leader。
Meta Service 不仅负责存储和提供图数据的 meta 信息,如 schema、partition 信息等,还同时负责指挥数据迁移及 leader 的变更等运维操作。
存储计算分离
在架构图中 Meta Service 的左侧,为 Nebula Graph 的主要服务,Nebula 采用存储与计算分离的架构,虚线以上为计算,以下为存储。
存储计算分离有诸多优势,最直接的优势就是,计算层和存储层可以根据各自的情况弹性扩容、缩容。
存储计算分离还带来的另一个优势:使水平扩展成为可能。
此外,存储计算分离使得 Storage Service 可以为多种类型的个计算层或者计算引擎提供服务。当前 Query Service 是一个高优先级的计算层,而各种迭代计算框架会是另外一个计算层。
无状态计算层
现在我们来看下计算层,每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 meta 信息,以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。
计算层的负载均衡有两种形式,最常见的方式是在计算层上加一个负载均衡(balance),第二种方法是将计算层所有节点的 IP 地址配置在客户端中,这样客户端可以随机选取计算节点进行连接。
每个查询计算引擎都能接收客户端的请求,解析查询语句,生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器,最后再交由执行器执行。
Shared-nothing 分布式存储层
Storage Service 采用 shared-nothing 的分布式架构设计,每个存储节点都有多个本地 KV 存储实例作为物理存储。Nebula 采用多数派协议 Raft 来保证这些 KV 存储之间的一致性(由于 Raft 比 Paxo 更简洁,我们选用了 Raft )。在 KVStore 之上是图语义层,用于将图操作转换为下层 KV 操作。
图数据(点和边)是通过 Hash 的方式存储在不同 Partition 中。这里用的 Hash 函数实现很直接,即 vertex_id 取余 Partition 数。在 Nebula Graph 中,Partition 表示一个虚拟的数据集,这些 Partition 分布在所有的存储节点,分布信息存储在 Meta Service 中(因此所有的存储节点和计算节点都能获取到这个分布信息)。
附录
Nebula Graph GitHub 地址:https://github.com/vesoft-inc/nebula ,加入 Nebula Graph 交流群,请联系 Nebula Graph 官方小助手微信号:NebulaGraphbot
Nebula Graph:一个开源的分布式图数据库。
Nebula 架构剖析系列(零)图数据库的整体架构设计的更多相关文章
- Nebula 架构剖析系列(一)图数据库的存储设计
摘要 在讨论某个数据库时,存储 ( Storage ) 和计算 ( Query Engine ) 通常是讨论的热点,也是爱好者们了解某个数据库不可或缺的部分.每个数据库都有其独有的存储.计算方式,今天 ...
- Nebula 架构剖析系列(二)图数据库的查询引擎设计
摘要 上文(存储篇)说到数据库重要的两部分为存储和计算,本篇内容为你解读图数据库 Nebula 在查询引擎 Query Engine 方面的设计实践. 在 Nebula 中,Query Engine ...
- 一张图进阶 RocketMQ - 整体架构
前 言 三此君看了好几本书,看了很多遍源码整理的 一张图进阶 RocketMQ 图片链接,关于 RocketMQ 你只需要记住这张图!如果你第一次看到这个系列,墙裂建议你打开链接.觉得不错的话,记得点 ...
- 深度解读MRS IoTDB时序数据库的整体架构设计与实现
[本期推荐]华为云社区6月刊来了,新鲜出炉的Top10技术干货.重磅技术专题分享:还有毕业季闯关大挑战,华为云专家带你做好职业规划. 摘要:本文将会系统地为大家介绍MRS IoTDB的来龙去脉和功能特 ...
- RocketMQ架构原理解析(一):整体架构
RocketMQ架构原理解析(一):整体架构 RocketMQ架构原理解析(二):消息存储(CommitLog) RocketMQ架构原理解析(三):消息索引(ConsumeQueue & I ...
- Consul实现原理系列文章3: Consul的整体架构
工作中用到了Consul来做服务发现,之后一段时间里,我会陆续发一些文章来讲述Consul实现原理.在前几篇文章介绍完了Consul用到的两个关键性东西Raft和Gossip之后,这篇文章会讲述Con ...
- mysql 架构篇系列 1 复制原理和复制架构
一. 复制概述 mysql 从3.23版本开始提供复制功能,复制是指将主数据库的ddl和dml操作通过二进制日志传到复制服务器(也叫从服务器)上,然后在从服务器上对这些日志重新执行(也叫重做),从而使 ...
- Pick of the Week'19 | 图数据库 Nebula 第 47 周看点-- insert 的二三事
每周五 Nebula 为你播报每周看点,每周看点由本周大事件.用户问答.Nebula 产品动态和推荐阅读构成. 今天是 2019 年第 47 个工作周的周五,来和 Nebula 看看本周有什么图数据库 ...
- 初识分布式图数据库 Nebula Graph 2.0 Query Engine
摘要:本文主要介绍 Query 层的整体结构,并通过一条 nGQL 语句来介绍其通过 Query 层的四个主要模块的流程. 一.概述 分布式图数据库 Nebula Graph 2.0 版本相比 1.0 ...
随机推荐
- 【JavaScript】ESlint & Prettier & Flow组合,得此三神助,混沌归太清
Flow Flow的意义 Flow是faceBook开源的一个JavaScript静态类型检查工具,作用类似TypeScript,但是它不像TS那样是一门独立的语言,而是作为一个babel-plugi ...
- python 中的while循环、格式化、编码初始
while循环 循环:不断重复着某件事就是循环 while 关键字 死循环:while True: 循环体 while True: # 死循环# print("坚强")# pr ...
- 【Offer】[67] 【把字符串转换成整数】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 将一个字符串转换成一个整数(实现Integer.valueOf(string)的功能,但是string不符合数字要求时返回0),要求不能 ...
- StackOverflow 周报 - 高质量问题的问答(Java、Python)
这是 Stack Overflow 第三周周报,本周加入了 Python 的内容,原计划两篇 Java.两篇 Python.但明天过节所以今天就先把周报发了,两篇 Java.一篇 Python.公众号 ...
- PHP的调试环境程序集成包----phpStudy
PHP (超文本预处理器) PHP即“超文本预处理器”,是一种通用开源脚本语言.PHP是在服务器端执行的脚本语言,与C语言类似,是常用的网站编程语言.PHP独特的语法混合了C.Java.Perl以及 ...
- 在eclipse中引入mybatis和spring的约束文件
eclipse中引入mybatis约束文件步骤: 首先: config的key值 http://mybatis.org/dtd/mybatis-3-config.dtd mapper的key值 htt ...
- Winform中使用FastReport的DesignReport时怎样给通过代码Table添加数据
场景 FastReport安装包下载.安装.去除使用限制以及工具箱中添加控件: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/10 ...
- Java第二次作业第五题
自定义异常类,非法年龄类,并在person3类中使用此类,根据情况抛出异常,并进行处理. package naizi; class IllegalAgeException extends Except ...
- 跟我学SpringCloud | 第十八篇:微服务 Docker 化之基础环境
1. 容器化 Docker 的横空出世,给了容器技术带来了质的飞跃,Docker 标准化了服务的基础设施,统一了应用的打包分发,部署以及操作系统相关类库等,解决了测试生产部署时环境差异的问题.对于运维 ...
- 2019年9月3日安卓凯立德全分辨率(路况)夏季版C3551-C7M24-3K21J25懒人包
拷贝懒人包NaviOne文件夹到机器根目录或内存卡根目录下:安装其中的apk程序 2019凯立德C3551-C7M24-3K21J25新组合懒人包 [分辨率]:自适应 [适用系统]:Android2. ...