python+selenium自动化框架
---恢复内容开始---
主要使用的模块:
- selenium/webdriver模块(须准备Chrome驱动),主要用于调用浏览器实现自动点击。
- unittest模块,主要用于整合测试用例。
- xlrd模块,主要用于调用Excle获取测试数据。
- HTMLTestRunnerCN模块,主要用于生成测试报告。
框架分层思路:
- 常用函数层
- 测试数据层
- 测试元素层
- 测试用例层
- 测试结果层
详细解释层级划分:
一、常用函数层:主要写常用的一些类,方便后面调用,如:selenium调用浏览器、读取URL的EXCEL、读取用户数据的EXCEL等
二、测试数据层:主要存放一些用户数据/URL/测试数据等到EXCEL中方便后续调用 我这里存放的主要有:
- 测试网站的URL。
- 项目中不同权限用户的用户名和密码
- 常用配置文件信息
三、测试元素层:主要存放一些较长的Xpath和Css定位路径,使后续脚本简洁
四、测试用例层:主要使用unittest模块 创建测试用例:
class Test(unittest.TestCase):
def setUp(self):
self.flag = 1
self.ca = function.OpenChrome()
self.br = function.OpenChrome().open()
self.xpath = element.Element()
self.eid = element.ID()
self.css = element.Css()
self.temp = function.Openurl()
self.br.maximize_window()
#以上为定义unittest类,并在setUp中添加前置条件 def test_登录用户(self):...
def test_xxx(self):...
def test_xxx(self):...
def test_xxx(self):...
def test_xxx(self):...
#以上为使用test__xx函数逐个创建测试用例 def tearDown(self):
self.assertEqual(self.flag,1,msg="用例执行失败")
self.br.close()
#以上为添加后置条件,如:断言,关闭浏览器等
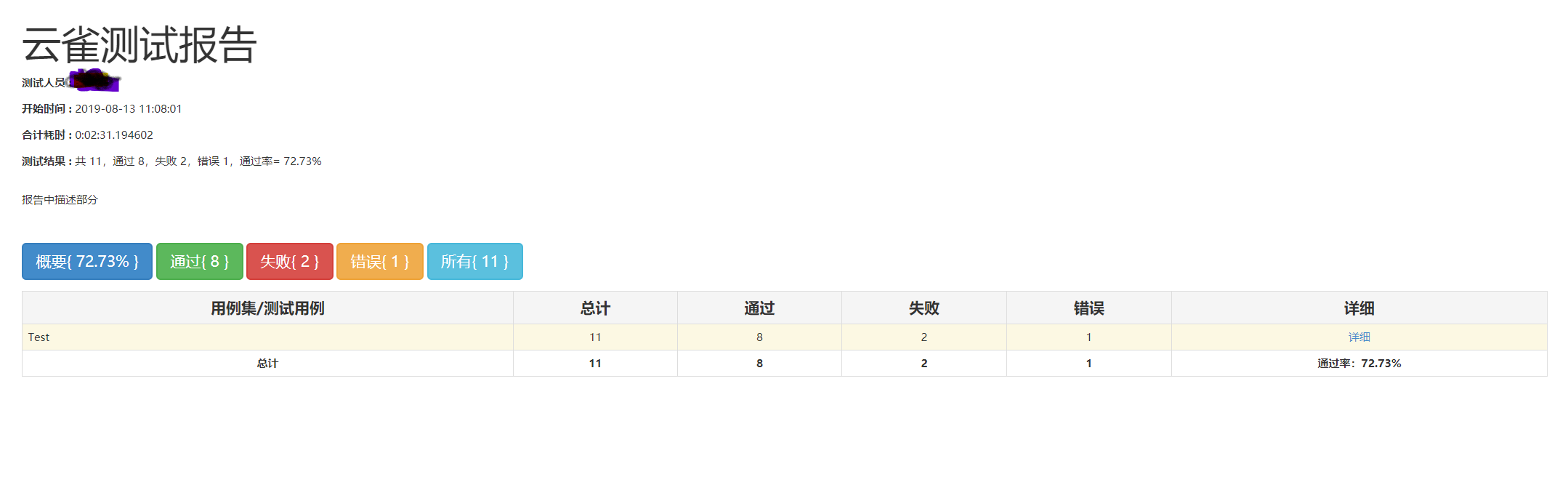
五、测试结果层:主要使用HTMLTestRunnerCN模块生成测试报告:
filepath = '../result/Yunque_result.html'
fp = open(filepath,'wb')
runner = HTMLTestRunnerCN.HTMLTestReportCN(stream=fp,title='xx测试报告',tester='测试人员',description = '报告中描述部分')
runner.run(suite)
测试结果如下图:
python+selenium自动化框架的更多相关文章
- python+selenium自动化框架搭建
环境及使用软件信息 python 3 selenium 3.13.0 xlrd 1.1.0 chromedriver HTMLTestRunner 说明: selenium/xlrd只需要再pytho ...
- python+selenium+unnittest框架
python+selenium+unnittest框架,以百度搜索为例,做了一个简单的框架,先看一下整个项目目录结构 我用的是pycharm工具,我觉得这个工具是天使,超好用也超好看! 这些要感谢原作 ...
- python selenium自动化点击页面链接测试
python selenium自动化点击页面链接测试 需求:现在有一个网站的页面,我希望用python自动化的测试点击这个页面上所有的在本窗口跳转,并且是本站内的链接,前往到链接页面之后在通过后退返回 ...
- python+selenium自动化登录dnf11周年活动界面领取奖励登录部分采坑总结[1]
背景: Dnf的周年庆活动之一,游戏在6月22日 06:00~6月23日 06:00之间登陆过游戏后可以于6月25日 16:00~7月04日 06:00领取奖励 目标:连续四天自动运行脚本,自动领取所 ...
- Python+selenium 自动化-启用带插件的chrome浏览器,调用浏览器带插件,浏览器加载配置信息。
Python+selenium 自动化-启用带插件的chrome浏览器,调用浏览器带插件,浏览器加载配置信息. 本文链接:https://blog.csdn.net/qq_38161040/art ...
- Python+Selenium自动化总结
Python+Selenium自动化总结 1.环境搭建 1.1.安装selenium模块文件 pip install selenium 1.2.安装ChromeDriver驱动 [1]下载安装Chro ...
- Python+Selenium自动化-定位一组元素,单选框、复选框的选中方法
Python+Selenium自动化-定位一组元素,单选框.复选框的选中方法 之前学习了8种定位单个元素的方法,同时webdriver还提供了8种定位一组元素的方法.唯一区别就是在单词elemen ...
- Python+Selenium自动化-模拟键盘操作
Python+Selenium自动化-模拟键盘操作 0.导入键盘类Keys() selenium中的Keys()类提供了大部分的键盘操作方法:通过send_keys()方法来模拟键盘上的按键. # ...
- Python+Selenium自动化-设置等待三种等待方法
Python+Selenium自动化-设置等待三种等待方法 如果遇到使用ajax加载的网页,页面元素可能不是同时加载出来的,这个时候,就需要我们通过设置一个等待条件,等待页面元素加载完成,避免出现 ...
随机推荐
- Erlang中的RSA签名
RSA签名校验 -spec check_rsa_sign(DataBin, Sign, RSAPublicKeyBin, DigestType) -> boolean when DataBin ...
- C# Post Get 方式发送请求
httpPost 方式发送请求 不带参数 /// <summary> /// 没有参数的post请求 /// </summary> public void HttpPostNo ...
- [币严区块链]ETH搭建节点区块数据同步的三种模式:full、fast、light
ETH 全节点Archive(归档)模式数据量增长图 上述图表可通过链接查看:https://etherscan.io/chartsync/chainarchive 通过上表,可以看到截止2019年 ...
- 每个Java开发人员都应该知道的10个基本工具
大家好,我们已经在2019年的第9个月,我相信你们所有人已经在2019年学到了什么,以及如何实现这些目标.我一直在写一系列文章,为你提供一些关于你可以学习和改进的想法,以便在2019年成为一个更好的. ...
- Hive入门--2.分区表 外部分区表 关联查询
1.查看mysql中metastore数据存储结构 Metastore中只保存了表的描述信息(名字,列,类型,对应目录) 使用SQLYog连接itcast05 的mysql数据库 查看hive数据库 ...
- TestNG(四) 基本注解BeforeSuite和AfterSuite
package com.course.testng; import org.testng.annotations.*; public class BasicAnnotation { @Test //最 ...
- 会用python把linux命令写一遍的人,进大厂有多容易?
看过这篇<2000字谏言,给那些想学Python的人,建议收藏后细看!>的读者应该都对一个命令有点印象吧?没错,就是 linux 中经常会用到的 ls 命令. 文章中我就提到如何提升自己的 ...
- 03 (H5*) Vue第三天
目录: 1:Vue-resource中的全局配置. 2:Vue动画2部曲 3:animate动画 4:钩子函数动画 5:组件三部曲,推荐使用template标签来创建组件模板 1:Vue-resour ...
- SSH Config 管理多主机
使用 一般我们使用ssh连接远程主机的时候,使用命令是: ssh root@ip ssh –i [identity-file] -p [port] user@hostname 但是如果ip地址过多,其 ...
- RocketMQ学习 -> NameServer路由中心
RocketMQ项目代码核心目录说明 broker:broker启动进程 client:消息客户端,包含消息生产者,消息消费者相关类 common:公共包 dev:开发者信息(非源代码) distri ...