Hadoop之HDFS文件系统(二)
HDFS客户端
通过IO流操作HDFS
HDFS文件上传
|
@Test public void putFileToHDFS() throws Exception{ // 1 创建配置信息对象 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"),configuration, "root"); // 2 创建输入流 FileInputStream inStream = new FileInputStream(new File("e:/hello.txt")); // 3 获取输出路径 String putFileName = "hdfs://hadoop102:9000/user/root/hello1.txt"; Path writePath = new Path(putFileName); // 4 创建输出流 FSDataOutputStream outStream = fs.create(writePath); // 5 流对接 try{ IOUtils.copyBytes(inStream, outStream, 4096, false); }catch(Exception e){ e.printStackTrace(); }finally{ IOUtils.closeStream(inStream); IOUtils.closeStream(outStream); } } |
HDFS文件下载
|
@Test public void getFileToHDFS() throws Exception{ // 1 创建配置信息对象 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"),configuration, "root"); // 2 获取读取文件路径 String filename = "hdfs://hadoop102:9000/user/root/hello1.txt"; // 3 创建读取path Path readPath = new Path(filename); // 4 创建输入流 FSDataInputStream inStream = fs.open(readPath); // 5 流对接输出到控制台 try{ IOUtils.copyBytes(inStream, System.out, 4096, false); }catch(Exception e){ e.printStackTrace(); }finally{ IOUtils.closeStream(inStream); } } |
定位文件读取(数据是分块存储,每一块为128M,数据大小超过这个值,就会存在多块)
下载第一块
|
@Test // 定位下载第一块内容 public void readFileSeek1() throws Exception { // 1 创建配置信息对象 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root"); // 2 获取输入流路径 Path path = new Path("hdfs://hadoop102:9000/user/atguigu/tmp/hadoop-2.7.2.tar.gz"); // 3 打开输入流 FSDataInputStream fis = fs.open(path); // 4 创建输出流 FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part1"); // 5 流对接 byte[] buf = new byte[1024]; for (int i = 0; i < 128 * 1024; i++) { fis.read(buf); fos.write(buf); } // 6 关闭流 IOUtils.closeStream(fis); IOUtils.closeStream(fos); } |
下载第二块
|
@Test // 定位下载第二块内容 public void readFileSeek2() throws Exception{ // 1 创建配置信息对象 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root"); // 2 获取输入流路径 Path path = new Path("hdfs://hadoop102:9000/user/atguigu/tmp/hadoop-2.7.2.tar.gz"); // 3 打开输入流 FSDataInputStream fis = fs.open(path); // 4 创建输出流 FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part2"); // 5 定位偏移量(第二块的首位) fis.seek(1024 * 1024 * 128); // 6 流对接 IOUtils.copyBytes(fis, fos, 1024); // 7 关闭流 IOUtils.closeStream(fis); IOUtils.closeStream(fos); } |
合并文件
在window命令窗口中执行
type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1
HDFS的数据流
HDFS写数据流程
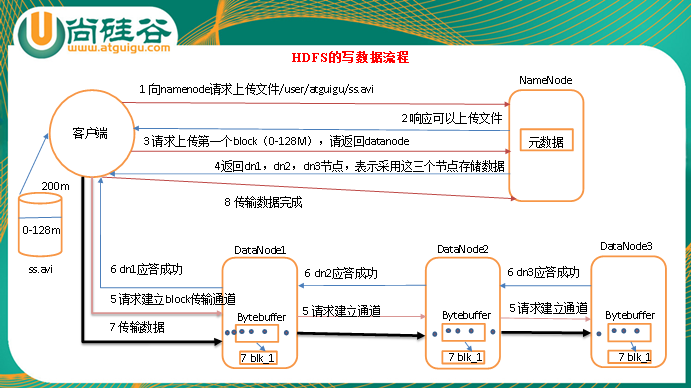
1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
HDFS读数据流程
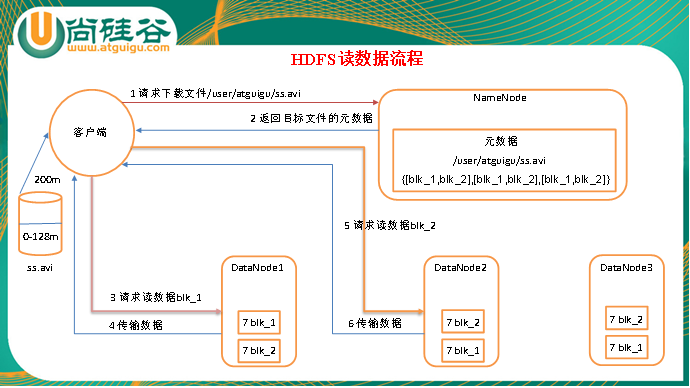
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
Hadoop之HDFS文件系统(二)的更多相关文章
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- Hadoop之HDFS(二)HDFS基本原理
HDFS 基本 原理 1,为什么选择 HDFS 存储数据 之所以选择 HDFS 存储数据,因为 HDFS 具有以下优点: 1.高容错性 数据自动保存多个副本.它通过增加副本的形式,提高容错性. 某一 ...
- Hadoop点滴-HDFS文件系统
1.HDFS中,目录作为元数据,保存在namenode中,而非datanode中 2.HDFS的文件权限模型与POSIX的权限模式非常相似,使用 r w x 3.HDFS的文件执行权限(X)可以 ...
- Hadoop之HDFS文件系统
概念 HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件:其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色. HDFS的设计适合一次写入,多次读出的场景,且不 ...
- hadoop中HDFS文件系统 nameNode出现的问题 nameNode无法打开
1,修改core-site.xml文件,先改成localhost,将所有进程关闭stop-all.sh(或者是先关闭所有进程,然后再修改文件),然后重启,在修改core-site.xml文件成ip地址 ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法
Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. fs.listFiles方法,返回Loc ...
随机推荐
- PHPStorm 10 配置PHPUnit
PHPStorm 10 配置PHPUnit PHPUnit的安装 自己用的是Xampp,PHPUnit好像自带不好用. 不说废话: 自己看 According to official site htt ...
- Java基础(二十二)集合(4)Set集合
Set集合为集类型.集是最简单的一种集合,存放于集中的对象不按特定方式排序,只是简单地把对象加入集合中.对集中存放的对象的访问和操作时通过对象的引用进行的,所以,在集中不能存放重复对象. Set接口实 ...
- 完美解决Python与anaconda之间的冲突问题
anaconda指的是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项.因为包含了大量的科学包,Anaconda 的下载文件比较大(约 515 MB),如果 ...
- (Git) 优秀Java,Vue项目推荐
Java 1.spring-boot-pay 地址:小柒2012/spring-boot-pay 这是一个支付案例,提供了包括支付宝.微信.银联在内的详细支付代码案例,对于有支付需求的小伙伴来说,这个 ...
- 前端技术之:常用webpack插件
1.html-webpack-plugin Simplifies creation of HTML files to serve your webpack bundles. 主页地址: https ...
- 一文搭建自己博客/文档系统:搭建,自动编译和部署,域名,HTTPS,备案等
本文纯原创,搭建后的博客/文档网站可以参考: Java 全栈知识体系.如需转载请说明原处. 第一部分 - 博客/文档系统的搭建 搭建博客有很多选择,平台性的比如: 知名的CSDN, 博客园, 知乎,简 ...
- Azure 上的物联网产品介绍
微软云Azure上物联网产品提供了从设备接入到设备与云的双向通信,到数据在云中存储,到数据分析,最后到数据展示的完整解决方案,本文主要介绍一些基本的概念,后续的章节中,会详细介绍每款产品的使用方法及步 ...
- RocketMQ实战:生产环境中,autoCreateTopicEnable为什么不能设置为true
1.现象 很多网友会问,为什么明明集群中有多台Broker服务器,autoCreateTopicEnable设置为true,表示开启Topic自动创建,但新创建的Topic的路由信息只包含在其中一台B ...
- 从壹开始 [ Ids4实战 ] 之五 ║ 多项目集成统一认证中心的思考
前言 哈喽大家好,好久都没有写文章了,这次又重新开始写技术文章了,半年前我还是一直保持每周都写文章的,后来是为了响应群友的号召,开始踏上了录制视频(https://www.bilibili.com/v ...
- php 下载图片并打包成Zip格式压缩包
前言:最近公司有个需要下载多个图片并打包成压缩包的需求,下面来看看具体是怎么做的 1.没什么说的,懒得说啥,直接看代码 /** * 下载图片并生成压缩包 * @param $data 图片数组,一维 ...