Hadoop之HDFS文件系统(二)
HDFS客户端
通过IO流操作HDFS
HDFS文件上传
|
@Test public void putFileToHDFS() throws Exception{ // 1 创建配置信息对象 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"),configuration, "root"); // 2 创建输入流 FileInputStream inStream = new FileInputStream(new File("e:/hello.txt")); // 3 获取输出路径 String putFileName = "hdfs://hadoop102:9000/user/root/hello1.txt"; Path writePath = new Path(putFileName); // 4 创建输出流 FSDataOutputStream outStream = fs.create(writePath); // 5 流对接 try{ IOUtils.copyBytes(inStream, outStream, 4096, false); }catch(Exception e){ e.printStackTrace(); }finally{ IOUtils.closeStream(inStream); IOUtils.closeStream(outStream); } } |
HDFS文件下载
|
@Test public void getFileToHDFS() throws Exception{ // 1 创建配置信息对象 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"),configuration, "root"); // 2 获取读取文件路径 String filename = "hdfs://hadoop102:9000/user/root/hello1.txt"; // 3 创建读取path Path readPath = new Path(filename); // 4 创建输入流 FSDataInputStream inStream = fs.open(readPath); // 5 流对接输出到控制台 try{ IOUtils.copyBytes(inStream, System.out, 4096, false); }catch(Exception e){ e.printStackTrace(); }finally{ IOUtils.closeStream(inStream); } } |
定位文件读取(数据是分块存储,每一块为128M,数据大小超过这个值,就会存在多块)
下载第一块
|
@Test // 定位下载第一块内容 public void readFileSeek1() throws Exception { // 1 创建配置信息对象 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root"); // 2 获取输入流路径 Path path = new Path("hdfs://hadoop102:9000/user/atguigu/tmp/hadoop-2.7.2.tar.gz"); // 3 打开输入流 FSDataInputStream fis = fs.open(path); // 4 创建输出流 FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part1"); // 5 流对接 byte[] buf = new byte[1024]; for (int i = 0; i < 128 * 1024; i++) { fis.read(buf); fos.write(buf); } // 6 关闭流 IOUtils.closeStream(fis); IOUtils.closeStream(fos); } |
下载第二块
|
@Test // 定位下载第二块内容 public void readFileSeek2() throws Exception{ // 1 创建配置信息对象 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root"); // 2 获取输入流路径 Path path = new Path("hdfs://hadoop102:9000/user/atguigu/tmp/hadoop-2.7.2.tar.gz"); // 3 打开输入流 FSDataInputStream fis = fs.open(path); // 4 创建输出流 FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part2"); // 5 定位偏移量(第二块的首位) fis.seek(1024 * 1024 * 128); // 6 流对接 IOUtils.copyBytes(fis, fos, 1024); // 7 关闭流 IOUtils.closeStream(fis); IOUtils.closeStream(fos); } |
合并文件
在window命令窗口中执行
type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1
HDFS的数据流
HDFS写数据流程
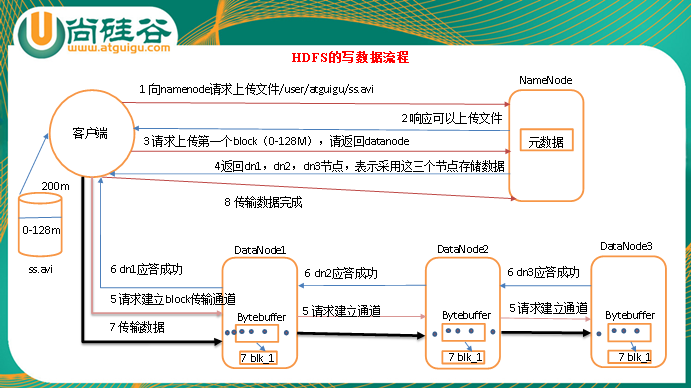
1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
HDFS读数据流程
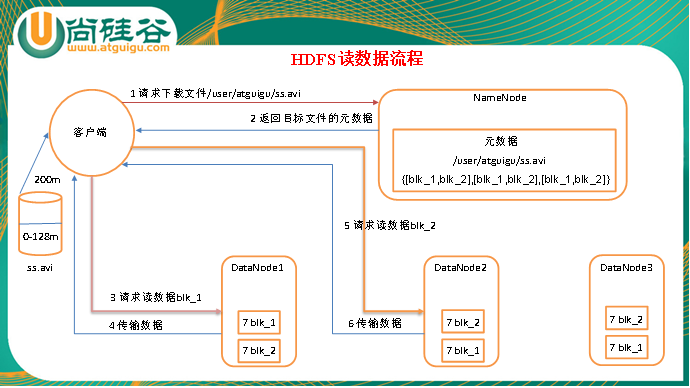
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
Hadoop之HDFS文件系统(二)的更多相关文章
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- Hadoop之HDFS(二)HDFS基本原理
HDFS 基本 原理 1,为什么选择 HDFS 存储数据 之所以选择 HDFS 存储数据,因为 HDFS 具有以下优点: 1.高容错性 数据自动保存多个副本.它通过增加副本的形式,提高容错性. 某一 ...
- Hadoop点滴-HDFS文件系统
1.HDFS中,目录作为元数据,保存在namenode中,而非datanode中 2.HDFS的文件权限模型与POSIX的权限模式非常相似,使用 r w x 3.HDFS的文件执行权限(X)可以 ...
- Hadoop之HDFS文件系统
概念 HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件:其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色. HDFS的设计适合一次写入,多次读出的场景,且不 ...
- hadoop中HDFS文件系统 nameNode出现的问题 nameNode无法打开
1,修改core-site.xml文件,先改成localhost,将所有进程关闭stop-all.sh(或者是先关闭所有进程,然后再修改文件),然后重启,在修改core-site.xml文件成ip地址 ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法
Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. fs.listFiles方法,返回Loc ...
随机推荐
- 【原】iOS开发进阶(唐巧)读书笔记(二)
第三部分:iOS开发底层原理 1.Objective-C对象模型 1.1 isa指针 NSObject.h部分代码: NS_ROOT_CLASS @interface NSObject <NSO ...
- <编译原理 - 函数绘图语言解释器(1)词法分析器 - python>
<编译原理 - 函数绘图语言解释器(1)词法分析器 - python> 背景 编译原理上机实现一个对函数绘图语言的解释器 - 用除C外的不同种语言实现 解释器分为三个实现块: 词法分析器: ...
- travis-ci + php + casperjs 持续集成
.travis.yml 文件添加内容: sudo: required language: php php: - 5.5 before_script: - npm install -g casperjs ...
- Leetcode Tags(2)Array
一.448. Find All Numbers Disappeared in an Array 给定一个范围在 1 ≤ a[i] ≤ n ( n = 数组大小 ) 的 整型数组,数组中的元素一些出现了 ...
- PHP限制上传文件大小
在php.ini中修改如下变量,如要限制为100M upload_max_filesize = 100M post_max_size = 100M 重启Apache
- vue中改变数组的值视图无变化
今天开发的时候遇到一个多选取消点击状态的,渲染的时候先默认都选中,然后可以取消选中,自建了一个全为true的数组,点击时对应下标的arr[index]改为false,数据改变了状态没更新,突然想起来单 ...
- Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException 异常
Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException 报此异常是应为有相同的bean ...
- Centos7 基础命令与软件的安装
本人小白一枚正在老男孩培训,所以从现在开始把我学到的知识都分享给大家,该随笔会一直更新 centos7基础命令与软件 ps:命令与参数之间必须加上空格,安装成功时最后一行会有 Complete! ...
- const var let 三者的区别
1.const定义的变量不可以修改,而且必须初始化. ;//正确 const b;//错误,必须初始化 console.log('函数外const定义b:' + b);//有输出值 b = ; con ...
- 在VMware下进行的CentOS7操作系统虚拟机的安装
一.VMware虚拟机的安装 首先你需要拥有一款软件VMware,这是一款虚拟机安装软件.Vmware比起Vbox收费较贵,占用资源大,但是拥有大量的资源以及拥有克隆技术,适合新手学习使用,较为专业. ...