python爬虫笔记之re.match匹配,与search、findall区别
为什么re.match匹配不到?re.match匹配规则怎样?(捕一下seo)
re.match(pattern, string[, flags])
pattern为匹配规则,即输入正则表达式。
string为,待匹配的文本或字符串。
网上的定义【 从要匹配的字符串的头部开始,当匹配到string的尾部还没有匹配结束时,返回None;
当匹配过程中出现了无法匹配的字母,返回None。】
但我觉得要强调关键一句【仅从要匹配的字符串头部开始匹配!】
看看例子,你就明白了!!!想用的话,一定要看!

出现<_src.SRE_Match object at .....>表示匹配成功。
出现None表示,匹配失败或未匹配到。
总结:re.match只从待匹配的字符串或文本的开头开始匹配,即如果匹配的字符串不在开头,而是在中间或结尾,则无法匹配!
———————————————————分割线——————————————————
顺便对比下re.match、re.search、re.findall的区别
match()函数只在string的开始位置匹配(例子如上图)。
search()会扫描整个string查找匹配,会扫描整个字符串并返回第一个成功的匹配。

re.findall()将返回一个所匹配的字符串的字符串列表。

———————————————————分割线——————————————————
《用python写网络爬虫》中1.4.4链接爬虫中,下图为有异议代码

这里的输出经测试,根本啥也没有,如下图

查了很久,应该是因为re.match一直匹配不到数据引起的,毕竟他只匹配开头。
我将re.match改为re.search,再测试,可正常下载
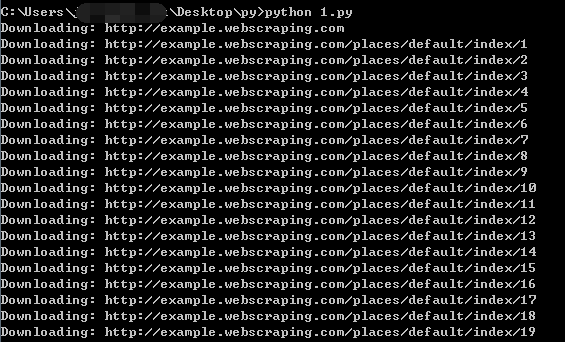
分析:可能是由于书编写时,http://example.webscraping.com/页面所带的链接都是:/index/1、/index/2……且输入匹配表达式为 【 /(index/view) 】,使用的是re.match匹配,如果匹配上述的url则没问题,而现在该网站页面所带的链接为:/places/default/index/1、/places/default/index/2……所以,上文讲到的re.match的特点,从开头开始匹配,则这时候re.match就会一直匹配不上!我将它换位re.search就可以解决这个问题了。
如有错误,麻烦及时指正,谢谢!
python爬虫笔记之re.match匹配,与search、findall区别的更多相关文章
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC) 提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行. 课程为:北京理工大学-嵩天-P ...
- Python学习笔记——基础篇【第五周】——正在表达式(re.match与re.search的区别)
目录 1.正在表达式 2.正则表达式常用5种操作 3.正则表达式实例 4.re.match与re.search的区别 5.json 和 pickle 1.正则表达式 语法: import re # ...
- python爬虫笔记Day01
python爬虫笔记第一天 Requests库的安装 先在cmd中pip install requests 再打开Python IDM写入import requests 完成requests在.py文 ...
- 正则表达式中 re.match与re.search的区别
标签: 本文和大家分享的主要是python正则表达式中re.match函数与re.search方法的相关用法及异同点,希望通过本文的分享,能对大家有所帮助. re.match函数 re.match 尝 ...
- re.match与re.search的区别
re.match与re.search的区别 re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None:而re.search匹配整个字符串,直到找到一个匹配. 实 ...
- PYTHON 爬虫笔记四:正则表达式基础用法
知识点一:正则表达式详解及其基本使用方法 什么是正则表达式 正则表达式对子符串操作的一种逻辑公式,就是事先定义好的一些特定字符.及这些特定字符的组合,组成一个‘规则字符串’,这个‘规则字符串’用来表达 ...
- Python爬虫笔记安装篇
目录 爬虫三步 请求库 Requests:阻塞式请求库 Requests是什么 Requests安装 selenium:浏览器自动化测试 selenium安装 PhantomJS:隐藏浏览器窗口 Ph ...
- Python爬虫笔记技术篇
目录 前言 requests出现中文乱码 使用代理 BeautifulSoup的使用 Selenium的使用 基础使用 Selenium获取网页动态数据赋值给BeautifulSoup Seleniu ...
随机推荐
- Android零基础入门第26节:layout_gravity和gravity大不同
原文:Android零基础入门第26节:layout_gravity和gravity大不同 上一期我们一起学习了LinearLayout线性布局的方向.填充模型和权重,本期来一起学习LinearLay ...
- UWP ListView嵌套ListView
要求:加载全部的订单,每个订单里面有一个或者多个产品,在列表中要展现出来, 1. xaml界面 步骤:1.这里使用的是x:bind绑定所以要引入实体类命名空间(OrderList集合中类的命名空间): ...
- PRML Chapter4
超平面(hyperplane) 超平面:超平面是n维欧氏空间中余维度等于一的线性子空间,也就是说必须是(n-1)维度.这是平面中的直线.三维空间中平面的推广(n大于3才被称为"超" ...
- jQuery仪表盘指示器动画插件 6种仪表样式
土豆网同步更新:http://www.tudou.com/plcover/VHNh6ZopQ4E/ 使用HTML 创建Mac OS App 视频教程. 官方QQ群: (1)App实践出真知 434 ...
- Topshelf结合Quartz.NET实现服务端定时调度任务
这周接受到一个新的需求:一天内分时间段定时轮询一个第三方WebAPI,并保存第三方WebAPI结果. 需求分析:分时段.定时开启.定时结束.轮询.主要工作集中在前三个上,轮询其实就是个Http请求,比 ...
- linux下视频传输测试
本文博客链接:http://blog.csdn.net/jdh99,作者:jdh,转载请注明. 在上一篇<ubuntu下基于qt+OpenCV控制摄像头>的基础上测试了视频传输. 环境:主 ...
- 检索 COM 类工厂中 CLSID 为 {{10020200-E260-11CF-AE68-00AA004A34D5}} 的组件时失败解决办法
检索 COM 类工厂中 CLSID 为 {10020200-E260-11CF-AE68-00AA004A34D5} 的组件时失败,解决方法如下: 第一步:首先将msvcr71.dll, SQLDM ...
- PHP学习(一)
// php注释: // 单行注释 /*多行注释 多行注释*/ /** *姓名:李华 *时间:2016年 *内容:文档注释 */ #这是脚本注释--以下是注释代码 /*php的数据类型: 标量类型(4 ...
- 【实战】SpringBoot + KafKa
1.配置pom包 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId& ...
- 【MYSQL】mysql大数据量分页性能优化
转载地址: http://www.cnblogs.com/lpfuture/p/5772055.html https://www.cnblogs.com/shiwenhu/p/5757250.html ...