MySQL索引的使用是怎么样的?5个点轻松掌握!
一、前言
在MySQL中进行SQL优化的时候,经常会在一些情况下,对MySQL能否利用索引有一些迷惑。
譬如:
MySQL 在遇到范围查询条件的时候就停止匹配了,那么到底是哪些范围条件?
MySQL 在LIKE进行模糊匹配的时候又是如何利用索引的呢?
MySQL 到底在怎么样的情况下能够利用索引进行排序?
今天,我将会用一个模型,把这些问题都一一解答,让你对MySQL索引的使用不再畏惧。
二、知识补充
key_len
EXPLAIN执行计划中有一列 key_len 用于表示本次查询中,所选择的索引长度有多少字节,通常我们可借此判断联合索引有多少列被选择了。
在这里 key_len 大小的计算规则是:
一般地,key_len 等于索引列类型字节长度,例如int类型为4 bytes,bigint为8 bytes;
如果是字符串类型,还需要同时考虑字符集因素,例如:CHAR(30) UTF8则key_len至少是90 bytes;
若该列类型定义时允许NULL,其key_len还需要再加 1 bytes;
若该列类型为变长类型,例如 VARCHAR(TEXT\BLOB不允许整列创建索引,如果创建部分索引也被视为动态列类型),其key_len还需要再加 2 bytes;
三、哪些条件能用到索引
首先非常感谢登博,给了我一个很好的启发,我通过他的文章_,然后结合自己的理解,制作出了这幅图:
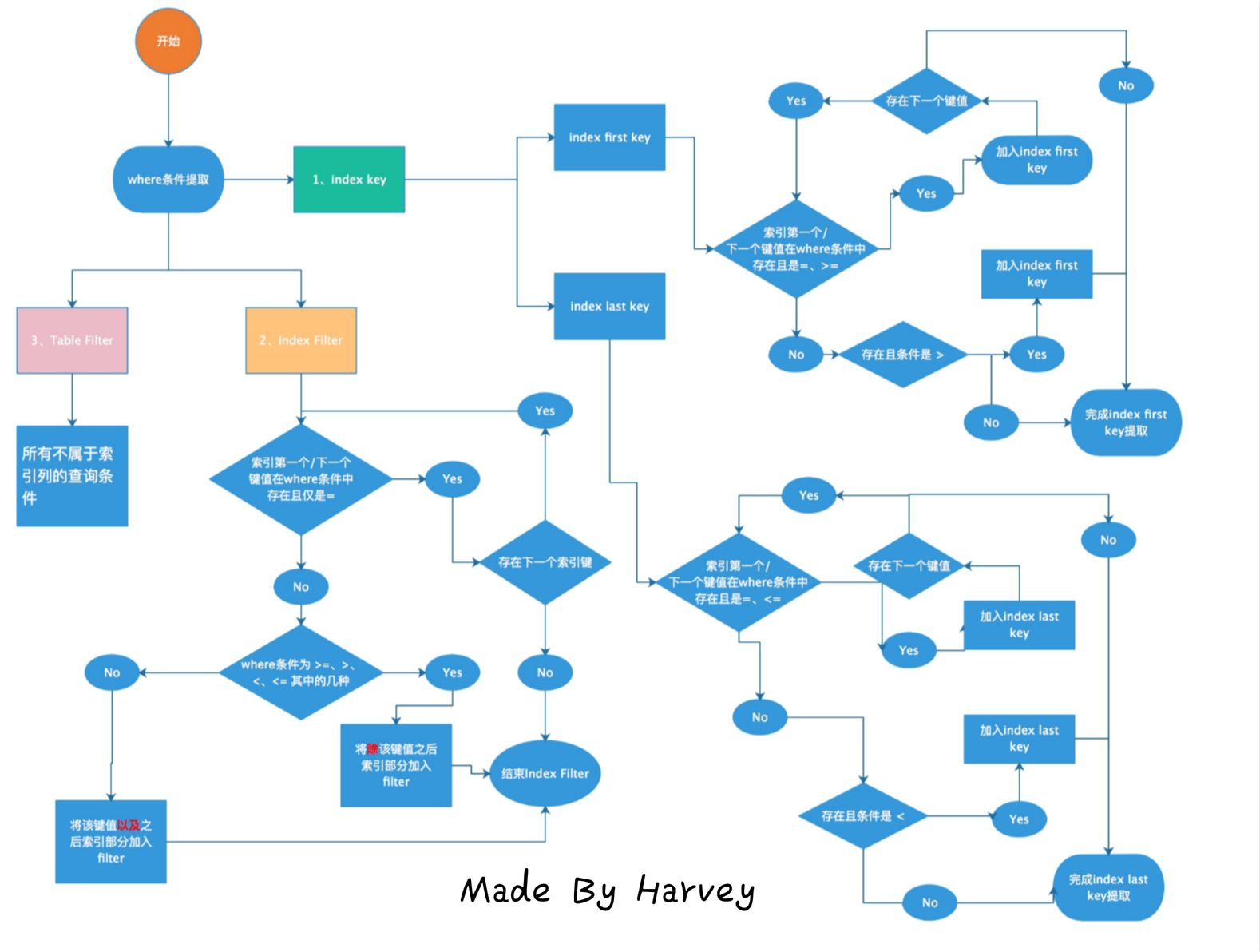
乍一看,是不是很晕,不急,我们慢慢来看
图中一共分了三个部分:
Index Key :MySQL是用来确定扫描的数据范围,实际就是可以利用到的MySQL索引部分,体现在Key Length。
Index Filter:MySQL用来确定哪些数据是可以用索引去过滤,在启用ICP后,可以用上索引的部分。
Table Filter:MySQL无法用索引过滤,回表取回行数据后,到server层进行数据过滤。
下面我们细细展开。
Index Key
Index Key是用来确定MySQL的一个扫描范围,分为上边界和下边界。
MySQL利用=、>=、> 来确定下边界(first key),利用最左原则,首先判断第一个索引键值在where条件中是否存在,如果存在,则判断比较符号,如果为(=,>=)中的一种,加入下边界的界定,然后继续判断下一个索引键,如果存在且是(>),则将该键值加入到下边界的界定,停止匹配下一个索引键;如果不存在,直接停止下边界匹配。
exp:
idx_c1_c2_c3(c1,c2,c3)
where c1>=1 and c2>2 and c3=1
--> first key (c1,c2)
--> c1为 '>=' ,加入下边界界定,继续匹配下一个
-->c2 为 '>',加入下边界界定,停止匹配
上边界(last key)和下边界(first key)类似,首先判断是否是否是(=,<=)中的一种,如果是,加入界定,继续下一个索引键值匹配,如果是(<),加入界定,停止匹配
exp:
idx_c1_c2_c3(c1,c2,c3)
where c1<=1 and c2=2 and c3<3
--> last key (c1,c2,c3)
--> c1为 '<=',加入上边界界定,继续匹配下一个
--> c2为 '='加入上边界界定,继续匹配下一个
--> c3 为 '<',加入上边界界定,停止匹配
注:这里简单的记忆是,如果比较符号中包含'='号,'>='也是包含'=',那么该索引键是可以被利用的,可以继续匹配后面的索引键值;如果不存在'=',也就是'>','<',这两个,后面的索引键值就无法匹配了。同时,上下边界是不可以混用的,哪个边界能利用索引的的键值多,就是最终能够利用索引键值的个数。
Index Filter
字面理解就是可以用索引去过滤。也就是字段在索引键值中,但是无法用去确定Index Key的部分。
exp:
idex_c1_c2_c3
where c1>=1 and c2<=2 and c3 =1
index key --> c1
index filter--> c2 c3
这里为什么index key 只是c1呢?因为c2 是用来确定上边界的,但是上边界的c1没有出现(<=,=),而下边界中,c1是>=,c2没有出现,因此index key 只有c1字段。c2,c3 都出现在索引中,被当做index filter.
Table Filter
无法利用索引完成过滤,就只能用table filter。此时引擎层会将行数据返回到server层,然后server层进行table filter。
四、Between 和Like 的处理
那么如果查询中存在between 和like,MySQL是如何进行处理的呢?
Between
where c1 between 'a' and 'b' 等价于 where c1>='a' and c1 <='b',所以进行相应的替换,然后带入上层模型,确定上下边界即可
Like
首先需要确认的是%不能是最在最左侧,where c1 like '%a' 这样的查询是无法利用索引的,因为索引的匹配需要符合最左前缀原则
where c1 like 'a%' 其实等价于 where c1>='a' and c1<'b' 大家可以仔细思考下。
五、索引的排序
在数据库中,如果无法利用索引完成排序,随着过滤数据的数据量的上升,排序的成本会越来越大,即使是采用了limit,但是数据库是会选择将结果集进行全部排序,再取排序后的limit 记录,而且MySQL 针对可以用索引完成排序的limit 有优化,更能减少成本。
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c1` int(11) NOT NULL DEFAULT '0',
`c2` int(11) NOT NULL DEFAULT '0',
`c3` int(11) NOT NULL DEFAULT '0',
`c4` int(11) NOT NULL DEFAULT '0',
`c5` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_c1_c2_c3` (`c1`,`c2`,`c3`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4
select * from t1;
+----+----+----+----+----+----+
| id | c1 | c2 | c3 | c4 | c5 |
+----+----+----+----+----+----+
| 1 | 3 | 3 | 2 | 0 | 0 |
| 2 | 2 | 4 | 5 | 0 | 0 |
| 3 | 3 | 2 | 4 | 0 | 0 |
| 4 | 1 | 3 | 2 | 0 | 0 |
| 5 | 1 | 3 | 3 | 0 | 0 |
| 6 | 2 | 3 | 5 | 0 | 0 |
| 7 | 3 | 2 | 6 | 0 | 0 |
+----+----+----+----+----+----+
7 rows in set (0.00 sec)
select c1,c2,c3 from t1;
+----+----+----+
| c1 | c2 | c3 |
+----+----+----+
| 1 | 3 | 2 |
| 1 | 3 | 3 |
| 2 | 3 | 5 |
| 2 | 4 | 5 |
| 3 | 2 | 4 |
| 3 | 2 | 6 |
| 3 | 3 | 2 |
+----+----+----+
7 rows in set (0.00 sec)
存在一张表,c1,c2,c3上面有索引,select c1,c2,c3 from t1; 查询走的是索引全扫描,因此呈现的数据相当于在没有索引的情况下select c1,c2,c3 from t1 order by c1,c2,c3; 的结果。
因此,索引的有序性规则是怎么样的呢?
c1=3 —> c2 有序,c3 无序
c1=3,c2=2 — > c3 有序
c1 in(1,2) —> c2 无序 ,c3 无序
有个小规律,idx_c1_c2_c3,那么如何确定某个字段是有序的呢?c1 在索引的最前面,肯定是有序的,c2在第二个位置,只有在c1 唯一确定一个值的时候,c2才是有序的,如果c1有多个值,那么c2 将不一定有序,同理,c3也是类似
六、小结
针对MySQL索引,我这边只是提到了在单表查询情况下的模型,通过这篇文章,想必大家应该了解到MySQL大部分情况下是如何利用索引的。
欢迎关注公众号:程序员追风,领取Java知识点学习思维导图总结+一线大厂Java面试题总结+一份300页pdf文档的Java核心知识点总结!
MySQL索引的使用是怎么样的?5个点轻松掌握!的更多相关文章
- 深入MySQL索引
MySQL索引作为数据库优化的常用手段之一在项目优化中经常会被用到, 但是如何建立高效索引,有效的使用索引以及索引优化的背后到底是什么原理?这次我们深入数据库索引,从索引的数据结构开始说起. 索引原理 ...
- MySQL 索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是 ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- [转]MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL索引类型总结和使用技巧以及注意事项
索引是快速搜索的关键.MySQL索引的建立对于MySQL的高效运行是很重要的.下面介绍几种常见的MySQL索引类型 在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytable ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- mysql索引总结----mysql 索引类型以及创建
文章归属:http://feiyan.info/16.html,我想自己去写了,但是发现此君总结的非常详细.直接搬过来了 关于MySQL索引的好处,如果正确合理设计并且使用索引的MySQL是一辆兰博基 ...
- Mysql 索引实现原理. 聚集索引, 非聚集索引
Mysql索引实现: B-tree,B是balance,一般用于数据库的索引.使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度.而B+tree是B-tree的一个变种,My ...
随机推荐
- 苹果电脑上folx下载器比迅雷还好用?
对于使用Mac电脑的小伙伴来说,除了迅雷以外,能够使用的下载工具非常少.小编也会经常被朋友问起,是否有好用的Mac下载工具推荐.小编都会毫不犹豫地推荐他们Folx,一款非常适用于Mac的下载工具.今天 ...
- css3系列之伪类选择器
Pseudo-Classes Selectors(伪类选择器) E:not(s) E:root E:target E:first-child E:last-child E:only-child E:n ...
- PHP获取数组中重复值的键值
$array = array ( 0=>'a', 1=>'b', 2=>'a', 5=>'b', 6=>'c', 40=>'d' ); $keyarr =[];$r ...
- 3. git命令行操作之远程库操作
3.1 基本操作 注册GitHub账号 在本地创建一个本地库并初始化 登录到gitHub创建一个远程库 注意:windows的凭据管理器中会保存github登录信息.如果要切换登录者,先删除相应凭据 ...
- C++基础知识篇:C++ 常量
常量是固定值,在程序执行期间不会改变.这些固定的值,又叫做字面量. 常量可以是任何的基本数据类型,可分为整型数字.浮点数字.字符.字符串和布尔值. 常量就像是常规的变量,只不过常量的值在定义后不能进行 ...
- java基础之一:基本数据类型
在java中有基本数据类型和引用类型两种,今天来说下基本数据类型和其对应的包装类的之间的关系. 一.概述 java中的基本数据类型有八种,分别是char.byte.short.int.long.flo ...
- AtomicInteger的addAndGet(int delta)与getAndAdd(int delta)有什么区别?
结论:区别仅在于返回的结果,修改的值是相同的,但是返回的值不同. 看一下源码注释 1 /** 2 * Atomically adds the given value to the current va ...
- 对 精致码农大佬 说的 Task.Run 会存在 内存泄漏 的思考
一:背景 1. 讲故事 这段时间项目延期,加班比较厉害,博客就稍微停了停,不过还是得持续的技术输出呀! 园子里最近挺热闹的,精致码农大佬分享了三篇文章: 为什么要小心使用 Task.Run [http ...
- OpenWrt下基于OLSR的Ad-Hoc组网实现网络摄像头多节点访问
文章目录 Ad-Hoc组网配置 摄像头端口映射 PC连接设置 结果 Ad-Hoc组网配置 参照博客 链接: link. 摄像头端口映射 这里使用到了海康网络摄像头,先将网络摄像头的网口连接到任意一个节 ...
- html标签学习2
input 系列 <form enctype="multipart/form-data"> <input type="text" name=& ...