VMwareWorkstation 平台 Ubuntu14 下安装配置 伪分布式 hadoop
VMwareWorkstation平台Ubuntu14下安装配置伪分布式hadoop
安装VmwareStation
内含注册机。
链接:https://pan.baidu.com/s/1j-vKgDcMYyOYWg9QQs3FKg
提取码:byMB
下载与安装Ubuntu
在vmware下安装镜像的过程中能跳过直接跳过,在命令行界面如果卡住直接断网即可。网络问题在后面会得到解决。
配置共享文件夹
图片太糊了,下载这个文档清晰点。
链接:https://pan.baidu.com/s/1Ak4W03u3xeOFCJ8GBeEtiQ
提取码:byMB
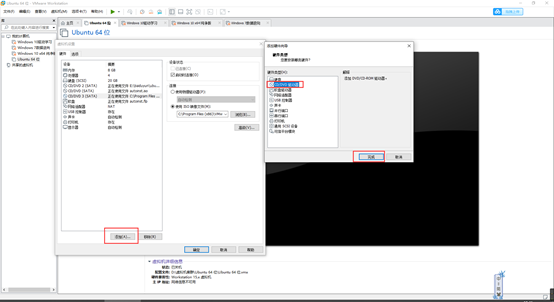

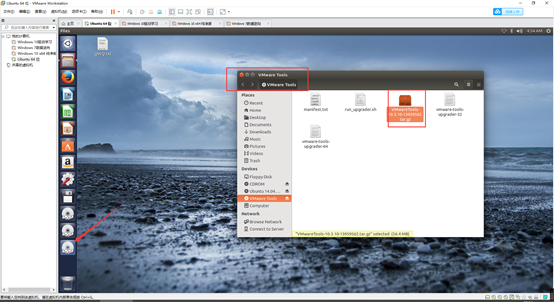
复制到桌面后
tar zxf /home/hadoop/Desktop/VMwareTools-8.8.2-590212.tar.gz #解压
cd /home/hadoop/Desktop/vmware-tools-distrib #打开目标文件夹
sudo ./vmware-install.pl #执行安装程序
虚拟机关机后设置共享文件夹
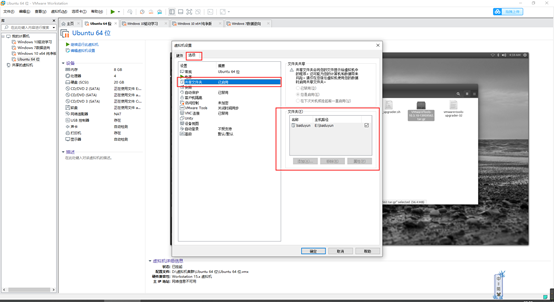
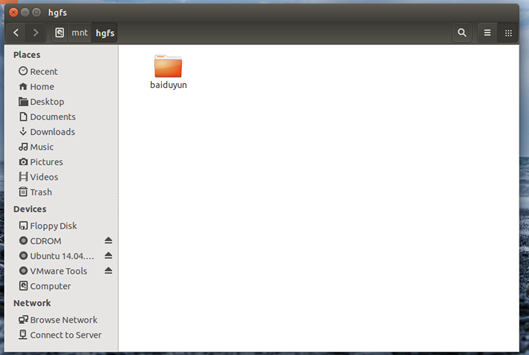
创建用户,授权
sudo useradd -m hadoop -s /bin/bash
sudo passwd Hadoop
sudo adduser hadoop sudo
更改下载源
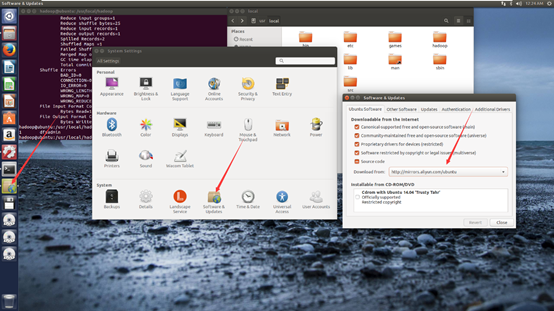
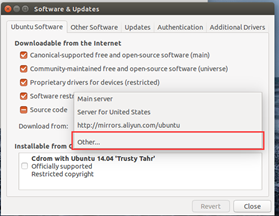

sudo apt-get update
配置安装SSH
sudo apt-get install openssh-server
ssh localhost
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
ssh localhost # 密钥登录
安装JDK
sudo apt-get install default-jre default-jdk
vim ~/.bashrc
在文件最前面添加如下单独一行
export JAVA_HOME=/usr/lib/jvm/default-java
source ~/.bashrc
安装hadoop
Hadoop2可以在http://mirror.bit.edu.cn/apache/hadoop/common/下载,下载后放进共享文件夹中
sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
测试是否安装成功
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
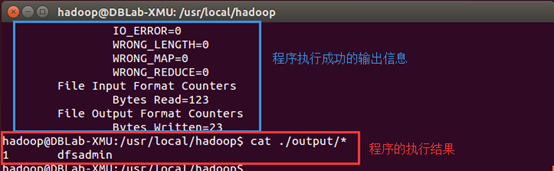
配置伪分布式hadoop
gedit ./etc/hadoop/core-site.xml
修改
<configuration>
</configuration>
为
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
gedit ./etc/hadoop/hdfs-site.xml
修改
<configuration>
</configuration>
为
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
cd /usr/local/hadoop #执行 NameNode 的格式化:
./bin/hdfs namenode -format
cd /usr/local/hadoop #开启 NameNode 和 DataNode 守护进程。
./sbin/start-dfs.sh
测试是否配置伪分布式hadoop成功
终端输入 jps

运行伪分布式实例
cd /usr/local/Hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
./bin/hdfs dfs -cat output/*

VMwareWorkstation 平台 Ubuntu14 下安装配置 伪分布式 hadoop的更多相关文章
- Hadoop安装-单机-伪分布式简单部署配置
最近在搞大数据项目支持所以有时间写下hadoop随笔吧. 环境介绍: Linux: centos7 jdk:java version "1.8.0_181 hadoop:hadoop-3.2 ...
- caffe学习(1):多平台下安装配置caffe
如何在 centos 7.3 上安装 caffe 深度学习工具 有好多朋友在安装 caffe 时遇到不少问题.(看文章的朋友希望关心一下我的创业项目趣智思成) 今天测试并整理一下安装过程.我是在阿 ...
- 云计算课程实验之安装Hadoop及配置伪分布式模式的Hadoop
一.实验目的 1. 掌握Linux虚拟机的安装方法. 2. 掌握Hadoop的伪分布式安装方法. 二.实验内容 (一)Linux基本操作命令 Linux常用基本命令包括: ls,cd,mkdir,rm ...
- Ubuntu14.04 安装配置Hadoop2.6.0
目前关于Hadoop的安装配置教程书上.官方教程.博客都有很多,但由于对Linux环境的不熟悉以及各种教程或多或少有这样那样的坑,很容易导致折腾许久都安装不成功(本人就是受害人之一).经过几天不断尝试 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- Ubuntu14.04安装配置ndnSIM
Ubuntu14.04安装配置ndnSIM 预环境 Ubuntu14.04官方系统 请先使用sudo apt-get update更新一下源列表 安装步骤 安装boost-lib sudo apt-g ...
- (转载)Linux下安装配置MySQL+Apache+PHP+WordPress的详细笔记
Linux下安装配置MySQL+Apache+PHP+WordPress的详细笔记 Linux下配LMAP环境,花了我好几天的时间.之前没有配置过,网上的安装资料比较混乱,加上我用的版本问题,安装过程 ...
- linux 下安装配置jboss as7以及部署应用
linux 下安装配置jboss as7以及部署应用 1.测试平台及软件 centos 5.4 jdk-7u5-linux-i586.rpm jboss-as-7.1.1.Final.zip jbos ...
- Windows下安装配置MongoDB
Windows下安装配置MongoDB 一,介绍 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统.在高负载的情况下,添加更多的节点,可以保证服务器性能. MongoDB ...
随机推荐
- SQLServer之 Stuff和For xml path
示例 昨天遇到一个SQL Server的问题:需要写一个储存过程来处理几个表中的数据,最后问题出在我想将一个表的一个列的多行内容拼接成一行,比如表中有两列数据 : 类别 名称 AAA 企业1 AAA ...
- Win10-1909删除自带的微软输入法,添加美式键盘
删除自带 输入法切换
- 浅谈 WebRTC 的 Audio 在进入 Encoder 之前的处理流程
在 WebRTC 中,Audio 数据在被送入编码器之前,有 2 大部分需要特别关注,一是数据采集,二是 Audio Processing. 作者:方来,技术专家,从事 voip 应用开发. 数据采集 ...
- 开源编解码项目FFmpeg迎来20周年生日 凭一己之力养活全球无数播放器!
近日,开源编解码库项目FFmpeg迎来20周年生日. 2000.12.20-2020.12.20 可能很多人对于FFmpeg不是特别了解,那么以下几个名字是否大家或多或少都用过呢? 暴风影音.PotP ...
- SpringBoot 获取微信小程序openid
最近做一个项目用到小程序,为了简化用户啊登录,通过获取小程序用户的openid来唯一标示用户. 1.官方教程 2.具体步骤 3.具体实现 4.可能出现的错误 5.代码下载 1.官方教程 先来看看官方怎 ...
- 简述java多态
一.多态性: 1.java实现多态的前提:继承.覆写: 2.覆写调用的前提:看new是哪个类的对象,而后看方法是否被子类覆写,若覆写则调用覆写的方法,若没覆写则调用父类的方法: 二.多态性组成: 1方 ...
- JavaDailyReports10_17
学习JavaWeb第一天 输出我的第一个HelloWorld! 1 <%@ page language="java" import="java.util.*&quo ...
- Vue从零开发SPA项目
所谓SPA(single page web application),就是单页面项目的意思. vue的亮点就是我们只需要关注数据的变化,下面演示一下从零开始创建一个独立项目,并且能自定义路由,提交表单 ...
- Vue知识点精简汇总
一. 组件component 1. 什么是组件? 组件(Component)是 Vue.js 最强大的功能之一.组件可以扩展 HTML 元素,封装可重用的代码组件是自定义元素(对象) 2. 定义组件的 ...
- 柔性分布式事务关于异步解决方案MQ版
上述思想本质是 二阶段提交变体 1,2是prepare阶段 4是commit阶段 存在问题 MQ提供半消息支持 生产者提供消息回查功能 发送方多次半消息到MQSERVER 消费方会多次消费消息 生产 ...