深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数、模型在训练集和测试集拟合效果、交叉验证、激活函数和优化算法的选择等。
那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以分别从训练集和测试集上看到这个模型造成的损失大小(loss),还有它的精确率(accuracy)。
目录
前言
- 最初可从分析数据集的特征,选择适合的函数以及优化器。
- 其次,模型在训练集上的效果。至少模型在训练集上得到理想的效果,模型优化方向:激活函数(activation function)、学习率(learning rate)。
- 再者,模型在训练集上得到好的效果之后,对测试集上的拟合程度更为重要,因为我们训练之后目的就是去预测并达到好的结果。模型优化方向:正则化(regularization)、丢弃参数(dropout)、提前停止训练(early stopping)。
以下介绍具体的方法和过程,图文结合,一目了然,这样方便学习记忆!
1、定义模型函数
衡量方法通常用到真实f与预测f*的方差(variance)和偏差(bias),最后对数据集的拟合程度可分为4种情况。如下:
| bias/variance | low | high |
| low | √ | 模型过于复杂 |
| high | 模型过于简单 | × |
这好比数据模型预测对准靶心后的偏移和分散程度,期望达到的效果就是(low,low),模型的偏差相当于与目标的偏离程度,而方差就是数据之间的分散程度。

定义一个模型函数后结果会遇到(low,high)和(high,low),显然,如果是(high,high)说明函数完全与模型不匹配,可重新考虑其他函数模型。那出现其他情况如何评估这个函数呢?
- 小偏差,大方差:所谓模型过拟合,在训练数据上得到好的效果,而在测试集上效果并不满意。优化方向:增加数据量;数据正则化处理。增加数据可以提高模型的鲁棒性,不被特殊数据影响整个模型的偏向;正则化是另一种方法,为了减小variance,但直接影响到bias,需要权衡。
- 大偏差,小方差:模型过于简单,在训练上没有得到好的效果。优化:增加模型参数(特征),更好去拟合数据。
2、交叉验证(Cross-validation)
在训练一个模型时候,通常会将数据分为:训练集,测试集,开放集(小型训练集)。这里交叉验证是在训练集上进行的,选择最优模型。
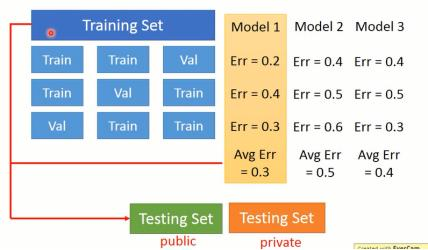
假设一个划分为:
| training-set | testing-set |
| 90% | 10% |
这里进行十折交叉验证,每一轮训练去9份数据作为训练集,1份作为测试集,并且每一轮的训练集与测试集对换,实现了所有数据都作为样本训练,所得到的模型避免了过拟合与低拟
合的问题。
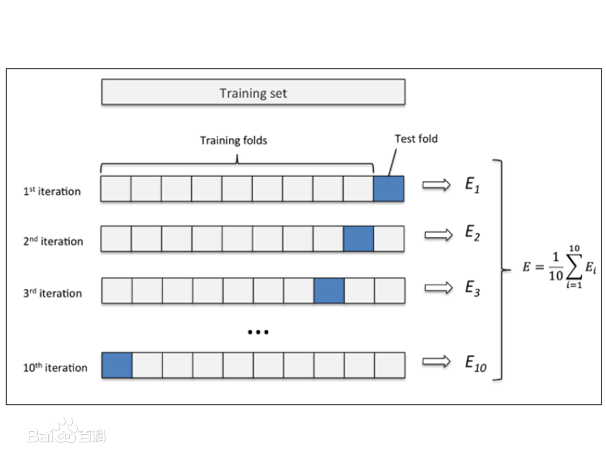
K折交叉验证类似。
优点:
(1)每一轮训练中几乎所有的样本数据用于训练模型,这样最接近原始样本的分布,评估所得的结果比较可靠。
(2)训练模型过程中较少随机特殊因素会影响实验数据,鲁棒性更好。
3、优化算法
模型优化算法选择根据要训练的模型以及数据,选择合适的算法,常用优化算法有:Gradient descent,Stochastic gradient descent,Adagrad,Adam,RMSprop。
前两种算法原理好理解,这里给出后面三种的算法原理如图,具体就不介绍了,写代码时候通常直接指定算法就行,算法原理理解就OK啦。
Adagrad

RMSprop

Adam

4、激活函数(activation)
选择合适的激活函数对模型训练也有很大的影响,需要适应训练任务,比如任务是二分类、多分类或许更新参数梯度问题等。常用的有:sigmoid、tanh、relu、softmax。
sigmoid
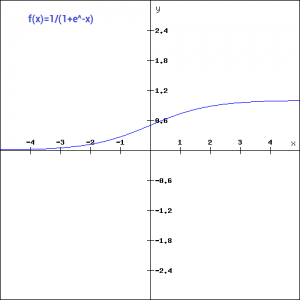
功能特点:平滑函数,连续可导,适合二分类,存在梯度消失问题。
tanh
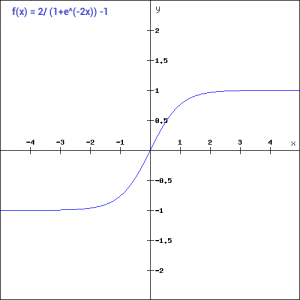
功能特点:与sigmoid相同的缺点,存在梯度消失,梯度下降的速度变慢。一般用在二分问题输出层,不在隐藏层中使用。
relu
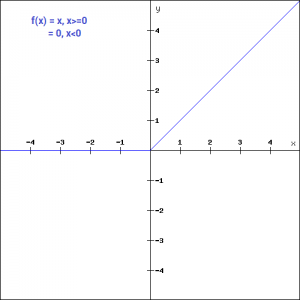
功能特点:ReLU在神经网络中使用最广泛的激活函数。根据图像x负半轴的特点,relu不会同时激活所有的神经元,如果输入值是负的,ReLU函数会转换为0,而神经元不被激活。这意味着,在一段时间内,只有少量的神经元被激活,神经网络的这种稀疏性使其变得高效且易于计算。
softmax
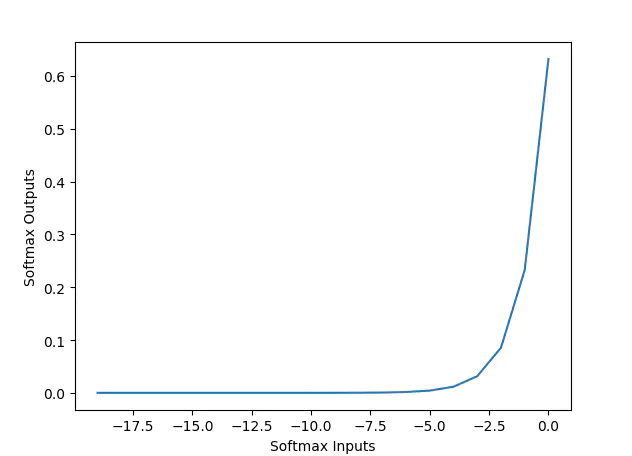
功能特点:又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。softmax通常在分类器的输出层使用。
在模型训练任务中激活函数通过指定选择,我们理解原理后帮助选择正确的函数,具体无需自己实现。
5、dropout
它解决深度神经网络的过拟合(overfitting)和梯度消失(gradient vanishing)问题,简单理解就是,当模型在训练集上得到较好的效果,而在测试集效果并不乐观,此时使用dropout对训练时候的参数进行优化调整(减少训练时候的参数),在学习过程中通过将隐含层的部分权重或输出随机归零,降低节点间的相互依赖性,使得模型在测试集上得到较好的结果的一种方法。相当于运用新的神经网络结构训练模型,在模型训练时候可在每一层指定设计。
6、early stopping
在训练时候观察模型在training-set和testing-set上的损失(loss),我们想要得到的模型是在测试时候损失误差更小,训练时候在训练集上可能不是最好的效果,所以需要提前停止保证了模型预测得到较好的结果。理解如图:

模型训练实战案例
(X_train, Y_train), (X_test, Y_test) = load_data()
model = keras.Sequential()
model.add(Dense(input_dim=28 * 28, units=690,
activation='relu')) # tanh activation:Sigmoid、tanh、ReLU、LeakyReLU、pReLU、ELU、maxout、softmax
model.add(Dense(units=690, activation='relu'))
model.add(Dense(units=690, activation='relu')) # tanh model.add(Dense(units=10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy']) # loss:mse,categorical_crossentropy,optimizer: rmsprop 或 adagrad、SGD(此处推荐)
model.fit(X_train, Y_train, batch_size=100, epochs=20)
result = model.evaluate(X_train, Y_train, batch_size=10000)
print('Train ACC:', result[1])
result = model.evaluate(X_test, Y_test, batch_size=10000)
print('Test ACC:', result[1])
案例中深度学习模型调优总结:
前三层sigmoid,输出层softmax,损失函数categorical_crossentropy,优化器SGD,训练集上达到86%
前三层换为relu,隐藏层加10层,其他不变,训练集上达到99.97%,测试集上95.9%,不加10层,Train-acc:100%,Test-acc:95.54%
优化器adam,训练速度提高,99.98%和96.7%
上面模型调优的理论方法,理解之后进行实战演练,可参考上一篇文章《mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)》,自行根据理论方法对模型进行调优,体验一下简单深度学习模型训练和模型调优的过程!
我的博客园:https://www.cnblogs.com/chenzhenhong/p/13437132.html
深度学习模型调优方法(Deep Learning学习记录)的更多相关文章
- 深度学习笔记之关于总结、展望、参考文献和Deep Learning学习资源(五)
不多说,直接上干货! 十.总结与展望 1)Deep learning总结 深度学习是关于自动学习要建模的数据的潜在(隐含)分布的多层(复杂)表达的算法.换句话来说,深度学习算法自动的提取分类需要的低层 ...
- 【deep learning学习笔记】注释yusugomori的DA代码 --- dA.h
DA就是“Denoising Autoencoders”的缩写.继续给yusugomori做注释,边注释边学习.看了一些DA的材料,基本上都在前面“转载”了.学习中间总有个疑问:DA和RBM到底啥区别 ...
- (转)分布式深度学习系统构建 简介 Distributed Deep Learning
HOME ABOUT CONTACT SUBSCRIBE VIA RSS DEEP LEARNING FOR ENTERPRISE Distributed Deep Learning, Part ...
- 英特尔深度学习框架BigDL——a distributed deep learning library for Apache Spark
BigDL: Distributed Deep Learning on Apache Spark What is BigDL? BigDL is a distributed deep learning ...
- [置顶]
Deep Learning 学习笔记
一.文章来由 好久没写原创博客了,一直处于学习新知识的阶段.来新加坡也有一个星期,搞定签证.入学等杂事之后,今天上午与导师确定了接下来的研究任务,我平时基本也是把博客当作联机版的云笔记~~如果有写的不 ...
- 【deep learning学习笔记】Recommending music on Spotify with deep learning
主要内容: Spotify是个类似酷我音乐的音乐站点.做个性化音乐推荐和音乐消费.作者利用deep learning结合协同过滤来做音乐推荐. 详细内容: 1. 协同过滤 基本原理:某两个用户听的歌曲 ...
- paper 149:Deep Learning 学习笔记(一)
1. 直接上手篇 台湾李宏毅教授写的,<1天搞懂深度学习> slideshare的链接: http://www.slideshare.net/tw_dsconf/ss-62245351? ...
- 【deep learning学习笔记】注释yusugomori的RBM代码 --- 头文件
百度了半天yusugomori,也不知道他是谁.不过这位老兄写了deep learning的代码,包括RBM.逻辑回归.DBN.autoencoder等,实现语言包括c.c++.java.python ...
- Neural Networks and Deep Learning学习笔记ch1 - 神经网络
近期開始看一些深度学习的资料.想学习一下深度学习的基础知识.找到了一个比較好的tutorial,Neural Networks and Deep Learning,认真看完了之后觉得收获还是非常多的. ...
随机推荐
- 数据库04 /多表查询、pymysql模块
数据库04 /多表查询.pymysql模块 目录 数据库04 /多表查询.pymysql模块 1. 笛卡尔积 2. 连表查询 2.1 inner join 内连接 2.2 left join 左连接 ...
- 机器学习实战基础(三十五):随机森林 (二)之 RandomForestClassifier 之重要参数
RandomForestClassifier class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’g ...
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
- 前端06 /JavaScript之BOM、DOM
前端06 /JavaScript 目录 前端06 /JavaScript 昨日内容回顾 js的引入 js的编程要求 变量 输入输出 基础数据类型 number string boolean null ...
- 阻止 iPhone 视频自动全屏
最近一年都在做直播,遭video 全屏的问题困扰了很久.下面将阻止 ios视频自动全屏的办法写出来.添加 playsinline 和 webkit-playsinline="true&quo ...
- Shaderlab-10chapter-立方体纹理、玻璃效果
10.1.1天空盒子 window - Lighting - skyMaterial 创建mat,shader选自带的6 side shader 确保相机选skybox 如果某个相机需要覆盖,添加sk ...
- mysql实现主从复制/主从同步
业务场景 小公司业务代码存于一个服务器上,而这个服务器有的时候回宕机,导致业务停顿,造成影响.这个时候 就需要做高可用 两个ngix+两个tomcat+两个mysql实现高可用,避免单点问题.中间使用 ...
- Linux基础入门(一)初识Shell
Linux基础入门(一)初识Shell shell是什么 Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁.Shell 既是一种命令语言,又是一种程序设计语言. Shell ...
- 如果你每次面试前都要去背一篇Spring中Bean的生命周期,请看完这篇文章
前言 当你准备去复习Spring中Bean的生命周期的时候,这个时候你开始上网找资料,很大概率会看到下面这张图: 先不论这张图上是否全面,但是就说这张图吧,你是不是背了又忘,忘了又背? 究其原因在于, ...
- 【SpringBoot】 中时间类型 序列化、反序列化、格式处理
[SpringBoot] 中时间类型 序列化.反序列化.格式处理 Date yml全局配置 spring: jackson: time-zone: GMT+8 date-format: yyyy-MM ...