Windows环境编译Spark源码
一、下载源码包
1. 下载地址有官网和github:
http://spark.apache.org/downloads.html
https://github.com/apache/spark
Linux服务器上直接下载:wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0.tgz
2. 解压源码
二、解压环境
需要maven、jdk、git、scala、hadoop环境,并配置环境变量。
二、使用Maven编译Spark
先找到解压后的spark文件里的pom.xml把maven、jdk、scala、hadoop改成当前安装的版本。如图:
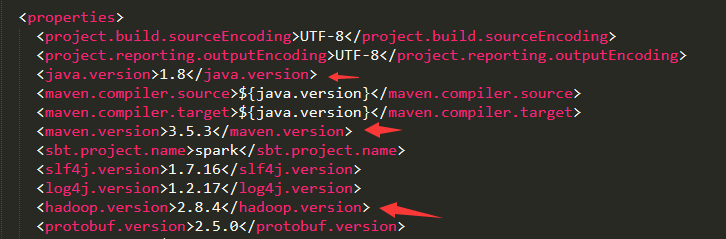
maven库的地址建议换成阿里的地址:http://maven.aliyun.com/nexus/content/groups/public
在编译过程需要保证编译机器的是联网的,以保证Maven从网上下载其依赖包。另外,编译前需要设置JVM内存大小,否则在编译过程中,会由于默认内存小而出现内存溢出的错误。编译执行脚本如下,其中,参数-P表示激活依赖的程序及版本,-Dskip Tests表示编译时跳过测试环节。
1、设置maven内存的环境变量
MAVEN_OPTS=-Xmx2g -XX:MaxPermSize=2048M -XX:ReservedCodeCacheSize=2048M
2、右击spark-2.4.0文件夹,选择Git Bash here,弹出git窗口,输入以下命令:
./build/mvn -Pyarn -Phadoop-2.8.4 -Dhadoop.version=2.8.4 -DskipTests clean package
整个编译过程编译了约29个任务,每个版本的数量不同。如果是已经下载依赖包的情况,则编译耗时1分钟左右。由于编译过程中需要下载较多的依赖包,因此整个编译时间取决于网速,最终编译完成后的文件夹大约为899MB。整个编译可能会很长,要耐心等待。
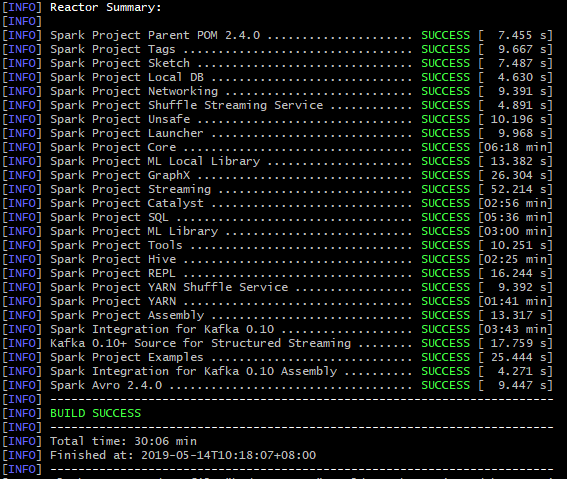
最终成功结果如下图:
如果在编译过程中出现了错误,解决后再重新执行编译命令:
错误1:Failed to collect dependencies at org.jpmml:pmml-model:jar:1.2.15
Could not resolve dependencies for project org.apache.spark:spark-core_2.11:jar:2.4.0
这两种都是依赖包下载失败,为了避免重新跑脚本还会失败浪费时间,建议使用idea加载jar包,或者到maven官网手动下载好放到maven本地库里。
错误2:有时第二次编译时,会删除源码包里面target里面的文件失败,可以手动删除,或者重新解压个新的spark源码文件,再编译。
Windows环境编译Spark源码的更多相关文章
- 编译spark源码及塔建源码阅读环境
编译spark源码及塔建源码阅读环境 (一),编译spark源码 1,更换maven的下载镜像: <mirrors> <!-- 阿里云仓库 --> <mirror> ...
- Spark 学习(三) maven 编译spark 源码
spark 源码编译 scala 版本2.11.4 os:ubuntu 14.04 64位 memery 3G spark :1.1.0 下载源码后解压 1 准备环境,安装jdk和scala,具体参考 ...
- Spark笔记--使用Maven编译Spark源码(windows)
1. 官网下载源码 source code,地址: http://spark.apache.org/downloads.html 2. 使用maven编译: 注意在编译之前,需要设置java堆大小以及 ...
- Windows使用Idea编译spark源码
1. 环境准备 JDK1.8 Scala2.11.8 Maven 3.3+ IDEA with scala plugin 2. 下载spark源码 下载地址 https://archive.apach ...
- window环境下使用sbt编译spark源码
前些天用maven编译打包spark,搞得焦头烂额的,各种错误,层出不穷,想想也是醉了,于是乎,换种方式,使用sbt编译,看看人品如何! 首先,从官网spark官网下载spark源码包,解压出来.我这 ...
- 编译Spark源码
Spark编译有两种处理方式,第一种是通过SBT,第二种是通过Maven.作过Java工作的一般对于Maven工具会比较熟悉,这边也是选用Maven的方式来处理Spark源码编译工作. 在开始编译工作 ...
- Windows下编译live555源码
Windos下编译live555源码 环境 Win7 64位 + VS2012 步骤 1)源码下载并解压 在官网上下载最新live555源码,并对其进行解压. 2)VS下建立工程项目 新建Win32项 ...
- Spark—编译Spark源码
Spark版本:Spark-2.1.0 Hadoop版本:hadooop-2.6.0-cdh5.7.0 官方文档:http://spark.apache.org/docs/latest/buildin ...
- windows环境中hbase源码编译遇到的问题
转载请注明出处 问题一 [ERROR] Failed to execute goal org.codehaus.mojo:findbugs-maven-plugin:3.0.0:findbugs (d ...
随机推荐
- Linux终端音乐播放器cmus攻略: 操作歌单
目录 1. 安装 2. 操作说明 2.1. *PlayList歌单 2.2. 其他 3. 视图切换 4. 使响应Media/play按键 4.1. 编译安装 cmus是一款开源的终端音乐播放器.它小巧 ...
- Webapi管理和性能测试工具WebBenchmark
WebBenchmark是一款基于开源通讯组件Beetlex扩展的Webapi管理和性能测试工具,在传统工具中一般管理工具缺乏性能压测能力或有性能测试的缺少管理功能:WebBenchmark的设计目标 ...
- 理解ASCII,Unicode和UTF-8关系
前言:之前一直就好奇这个问题,但是一直没解决,今天我总算明白了,感谢大佬们的科普 转自:https://blog.csdn.net/Deft_MKJing/article/details/794604 ...
- adb devices 不能连接设备 could not install *smartsocket* listener
cmd以管理员身份运行命令adb devices 或adb reverse tcp:8081 tcp:8081,无法连接设备,出现上图信息. 输入命令:adb kill-server 再输入:adb ...
- day12 文件操作(下)
目录 一.x模式(控制文件操作模式,与rwa同级) 1 特点 2 格式 二.b模式(控制文件读写内容的模式,与t同级) 1.b模式和t模式的区别 2 b模式应用 3 循环读取文件 三.文件操作的其他方 ...
- Django的Cookie Session和自定义分页
cookie Cookie的由来 大家都知道HTTP协议是无状态的. 无状态的意思是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接关系,它不会受前面的请求响应情况直接影响,也不 ...
- YAML 语言教程与使用案例
YAML语言教程与使用案例,如何编与读懂写YAML文件. YAML概要 YAML 是 “YAML Ain’t a Markup Language”(YAML 不是一种标记语言)的递归缩写.在开发的这种 ...
- python之爬虫(八)BeautifulSoup库的使用
上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器. beautifulSoup ...
- 集合-ConcurrentLinkedQueue 源码解析
问题 (1)ConcurrentLinkedQueue是阻塞队列吗? (2)ConcurrentLinkedQueue如何保证并发安全? (3)ConcurrentLinkedQueue能用于线程池吗 ...
- oop的三种设计模式(单例、工厂、策略)
参考网站 单例模式: 废话不多说,我们直接上代码: <?php /** 三私一公 *私有的静态属性:保存类的单例 *私有的__construct():阻止在类的外部实例化 *私有的__clone ...