回归(Regression)
回归(Regression)
生活中的很多事物之间是相互影响的,如商品的质量跟用户的满意度密切相关。而回归分析是要分析两个事物间的因果关系,即哪一个是自变量和因变量,以及自变量和因变量之间的关系;回归有着较多的实际应用场景,如分析天气和空气中跟物质含量跟PM2.5浓度的关系,在分析出这一关系后,即可以用来预测未来某一时刻的PM2.5;如在无人车中,分析无人车红外线感测值、各个方向的视觉图等与方向盘角度之间的关系;
回归案例分析
分析神奇宝贝自身各个属性(也称作特征)跟进化后CP(Combat Power)值之间的关系;神奇宝贝是一个对象,我们可用通过这个对象的各个属性来对其进行描述。神奇宝贝的各种属性有:进化前的CP值、物种、生命值、体重、高度;
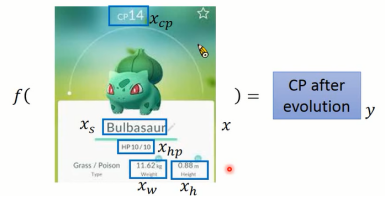
图1-1 神奇宝贝CP值预测
模型选择
我们需要用一个函数来表示神奇宝贝各个属性和进化后CP值的关系,但函数有千千万万,该如何选择?可以选择一个的线性函数来尝试,由于不知道那些属性跟最终的变量有真正关系,因此可以先只用一个可能有关系的变量进行尝试;最后的函数形式如(1)所示

数据收集
在确定模型的结构后,需要确定模型的参数w,b;而模型参数是要从数据集中来拟合出来。由于模型的结构为(1),因此模型的输入为进化前的CP值,输出为进化后的CP值,数据集 。为了方便直观查看变量间的关系,往往需要对数据进行可视化
。为了方便直观查看变量间的关系,往往需要对数据进行可视化
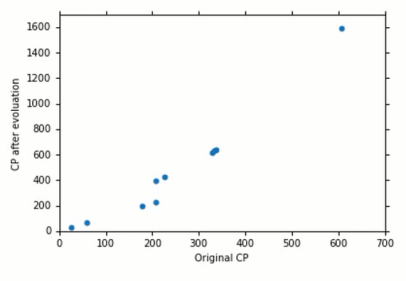
图1-2 进化前后CP值数据集
函数评估
我们最终的目的是要求解出(1)中的参数w,b;但w,b的取值是无限的,而哪一个取值才是最好的呢?损失函数(Loss Function)可以用来评估w,b取值的好坏。我们希望的是w,b能够使输出的 跟
跟 尽可能的相近,因此损失函数可以定义为
尽可能的相近,因此损失函数可以定义为

参数优化
在确定好损失函数后,我们希望的是w,b能够使L(w,b)最小化,表明实际输出值和 最接近。最佳的w,b用w*,b*来表示即
最接近。最佳的w,b用w*,b*来表示即

我们可以枚举所有的(w,b)来确定(w*,b*),只是这样太过麻烦甚至无法实现。因此需要有其他方法。当然也可以通过解线性方程来进行求解,而另外一种更加通用的解法就是梯度下降(Gradient Descent)。使用梯度下降的前提是L(w,b)为连续可微的!
w,b参数的更新形式为(4),

w,b的更新就是减去对应的偏导数;其中 为学习率,控制着w,b的收敛速度;
为学习率,控制着w,b的收敛速度;
泛化测试(Generalization Testing)
虽然在训练集上的,误差值已经优化的最小;但是,我们更关心的是训练出来后整个模型的泛化能力,即在测试集上对模型的预测误差进行测试;有时候我们的模型在训练集上已经训练到最好,但在测试集上却表现的很糟糕,这种现象称作“过拟合”。
模型迭代
在模型选择时,我们只是考虑最为简单的线性模型。因此,可以增加整个模型的复杂程度,例如可能增加二次式使模型可以表示曲线

在确定新的模型结构后,就可进行参数优化、泛化测试;虽然增加模型的复杂度,能够使模型在训练集上的误差减少,但是却可能会增加“过拟合”的情况。因此,复杂的模型并不总是带来更好的结果。
技巧使用
数据增加
我们在单独考虑进化前的CP值跟进化后CP值之间的关系,并且在只有10个数据集的情况下进行模型设计。因此需要数据集的数量,并进行可视化,如图1-3所示

图1-3 数据集可视化
显然,在增加数据后,整个数据的分布就完全不是一条直线能够去拟合的。如果你对数据足够敏感的话,会发现神奇宝贝的物种对整个数据分布其很大影响,如图1-4所示;

图1-4 物种对数据集分布影响
正则化(Regularization)
如果我们不是神奇宝贝的专家,那么依旧可行的方法是将所有你能够想到的属性都加到模型中,去设计出一个非常复杂的模型。通常,复杂的模型容易出现过拟合。当出现过拟合时,该怎么办?
对Loss Function进行调整,之前设定的损失函数为(2),现在我们增加多个属性,并对(2)进行调整

其中,前一项表示实际值和训练集之间的误差,而加入后一项的目的在于使wi尽可能小;使wi尽可能小是为了使得整个损失函数的平滑性更好。平滑性指的是当函数的输入发生变化时,对函数输出的变化尽可能小;因此,平滑性可以使得当训练集中存在噪音时,这些噪音数据对整个模型的影响会比较小。

图1-5 正则化对训练和测试的影响
从图1-5我们发现,当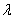 的值越大,训练误差也就增加,这是因为当值越大,
的值越大,训练误差也就增加,这是因为当值越大, 对整个损失函数的值影响越大;当的值越大,测试误差是先减少后增加,我们希望模型的平滑性可以适当增加,但不用过于平滑。因为,直线是最平滑的,但是最平滑的直线却什么都表示不了。
对整个损失函数的值影响越大;当的值越大,测试误差是先减少后增加,我们希望模型的平滑性可以适当增加,但不用过于平滑。因为,直线是最平滑的,但是最平滑的直线却什么都表示不了。
增加正则化是使损失函数的平滑性更好,因此后一项不需要写成 ,因为增加b并不会改变函数的平滑性,只是使函数上下移动而已。
,因为增加b并不会改变函数的平滑性,只是使函数上下移动而已。
参考资料
回归(Regression)的更多相关文章
- 浅谈回归Regression(一)
一.什么是回归? 孩子的身高是否与父母有关? 实际上,父母和孩子的身高是受到回归效应影响的.在时间纵轴上受影响.具有随机性的事物,无不遵循这一规律. 只要数据足够大,人类的身高或者智商,都有趋于平均值 ...
- 利用Caffe做回归(regression)
Caffe应该是目前深度学习领域应用最广泛的几大框架之一了,尤其是视觉领域.绝大多数用Caffe的人,应该用的都是基于分类的网络,但有的时候也许会有基于回归的视觉应用的需要,查了一下Caffe官网,还 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- 回归(regression)、梯度下降(gradient descent)
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: 上次写过一篇 ...
- 回归regression
X-Y存在某种映射关系,回归:确定出关系模型.
- 回归(regression)与分类(classification)的区别
术语监督学习,意指给出一个算法,需要部分数据集已经有正确的答案. " 分类和回归的区别在于输出变量的类型. 定量输出称为回归,或者说是连续变量预测:定性输出称为分类,或者说是离散变量预测. ...
- Machine Learning in Action -- 回归
机器学习问题分为分类和回归问题 回归问题,就是预测连续型数值,而不像分类问题,是预测离散的类别 至于这类问题为何称为回归regression,应该就是约定俗成,你也解释不通 比如为何logistic ...
- 【Todo】【转载】Spark学习 & 机器学习(实战部分)-监督学习、分类与回归
理论原理部分可以看这一篇:http://www.cnblogs.com/charlesblc/p/6109551.html 这里是实战部分.参考了 http://www.cnblogs.com/shi ...
- 【IUML】回归和梯度下降
回归(Regression) 在数学上来说是给定一个点集,能够用一条曲线去拟合之,如果这个曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归,回归还有很多的变种,如local ...
- 从损失函数优化角度:讨论“线性回归(linear regression)”与”线性分类(linear classification)“的联系与区别
1. 主要观点 线性模型是线性回归和线性分类的基础 线性回归和线性分类模型的差异主要在于损失函数形式上,我们可以将其看做是线性模型在多维空间中“不同方向”和“不同位置”的两种表现形式 损失函数是一种优 ...
随机推荐
- 阿里云Ubuntu配置安装MQTT服务器
先来说说mqtt协议: MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)是IBM开发的一个即时通讯协议,它比较适合于在低带宽.不可靠的网络的进行远程 ...
- vue项目中的路由守卫
路由守卫的意义就相当于一个保安一样,作用很大,在实际的项目中运用也是不少,也就是当客户在登陆自己账号的时候,有可能存在客户有啥事的时候,自己后台或者pc的关闭全部浏览器,没有点击退出登录,或者在退出登 ...
- Spark算子使用
一.spark的算子分类 转换算子和行动算子 转换算子:在使用的时候,spark是不会真正执行,直到需要行动算子之后才会执行.在spark中每一个算子在计算之后就会产生一个新的RDD. 二.在编写sp ...
- 总结(2019CSP之后),含题解
从\(\mathcal{CSP}\) 爆炸 到现在,已经有\(3\)个月了.这三个月间,我--这个小蒟蒻又接触了许多听不懂的东西 \(\mathcal{No.}1\) 字符串\(\mathcal{ha ...
- python后端开发面试总结
网络协议 通信计算机双方必须共同遵从的一组约定,只有遵守这个约定,计算机之间才能相互通信交流 TCP / IP TCP/IP(传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇.TC ...
- CentOS7上安装jdk,mysql
最近笔者的云服务器由于中毒,重装系统了... 所以就记录下所有服务的搭建过程吧 1.安装jdk 在oracle上下载linux系统的jdk,笔者这里使用的是1.8 https://www.oracle ...
- 牛客网NC15二叉树的层次遍历
题目 给定一个二叉树,返回该二叉树层序遍历的结果,(从左到右,一层一层地遍历) 例如: 给定的二叉树是{3,9,20,#,#,15,7}, 该二叉树层序遍历的结果是 [ [3], [9,20], [1 ...
- Openstack dashboard 仪表盘服务 (八)
Openstack dashboard 仪表盘服务 (八) # 说明: 这个部分将描述如何在控制节点上安装和配置仪表板.dashboard仅在核心服务中要求认证服务.你可以将dashboard与其他服 ...
- 使用Jenkins+Pipline 持构建自动化部署之安卓源码打包、测试、邮件通知
一.引言 Jenkins 2.x的精髓是Pipeline as Code,那为什么要用Pipeline呢?jenkins1.0也能实现自动化构建,但Pipeline能够将以前project中的配置信息 ...
- 简要MR与Spark在Shuffle区别
一.区别 ①本质上相同,都是把Map端数据分类处理后交由Reduce的过程. ②数据流有所区别,MR按map, spill, merge, shuffle, sort, r educe等各阶段逐一实现 ...