Docker搭建Hadoop环境
文章目录
Docker搭建Hadoop环境
Hadoop集群环境配置起来相当繁琐,并且在学习Hadoop过程中没有一般不会去使用多台设备进行分布式集群配置。因此在一台机器上配置Hadoop分布式集群时通常采用虚拟机来模拟多台设备,但虚拟机较为占用系统资源,开多个虚拟机(模拟Hadoop集群通常使用3个,一个master,两个slave)对内存要求比较高,因此笔者就想是否能通过Docker来配置Hadoop,并且通过Jetbrains IDEA来连接Docker容器调试MapReduce程序。经过一番折腾,成功地搭建了Docker+IDEA的Hadoop环境。在此将结合网上其他一些教程和自己的经验讲配置过程记录下来。
注意:文中多次提到容器终端是hadoop-master这个容器的终端
Docker的安装与使用
建议在Ubuntu上配置以下内容,因为我自己在Windows上多次尝试配置,都出现Datanode启动不了的情况,同样的步骤在Ubuntu上就没有问题。
看了一些Docker教程,笔者认为菜鸟教程里的Docker教程不错,包含安装过程和一些基础命令,在这里就不赘述了,读者自行查看 菜鸟教程- Docker,另外建议将Docker的镜像源修改为国内镜像源,下载速度会更快。
拉取镜像
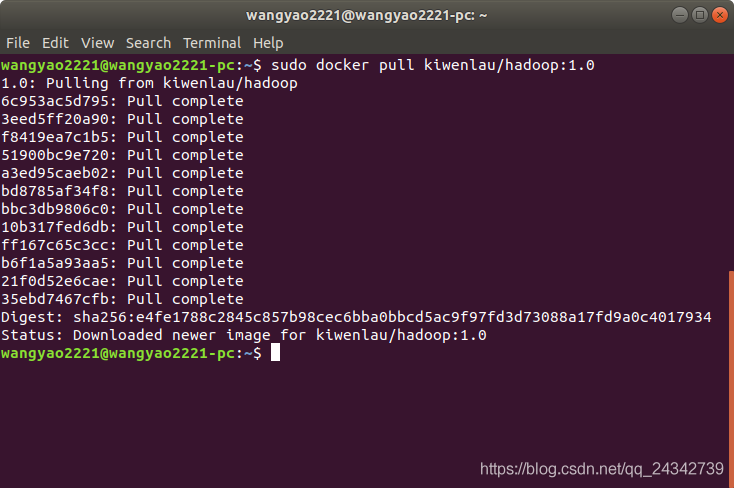
镜像,是 Docker 的核心,可以通过从远程拉取镜像即可配置好我们所需要的环境,我们这次需要的是 Hadoop 集群的镜像。我们使用kiwenlau/hadoop:1.0这个镜像。
sudo docker pull kiwenlau/hadoop:1.0
显示以下信息说明拉去镜像成功
克隆配置脚本
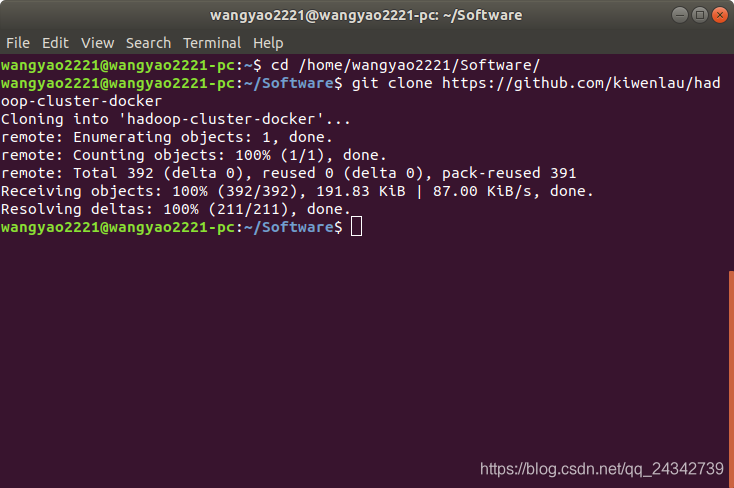
这一步是从github上克隆配置脚本,脚本的内容是使用kiwenlau/hadoop:1.0配置mater、slave1、slave2三个容器,其中slave数量可以修改:
git clone https://github.com/kiwenlau/hadoop-cluster-docker
切换到合适的路径在进行克隆,显示以下信息说明克隆完成
创建网桥
由于Hadoop的master节点需要与slave节点通信,需要在各个主机节点配置节点IP,为了不用每次启动都因为IP改变了而重新配置,在此配置一个Hadoop专用的网桥,配置之后各个容器的IP地址就能固定下来。
sudo docker network create --driver=bridge hadoop
出现以下信息说明网桥创建完成

执行脚本
此时可以通过前面步骤克隆下来的脚本进行容器创建了,首先看一下脚本内容

为了后续通过IDEA连接IDEA,需要修改脚本,添加一个端口映射,将容器的9000端口映射到本地的9000端口,在-p 8088:8088 \下添加一行如下图所示

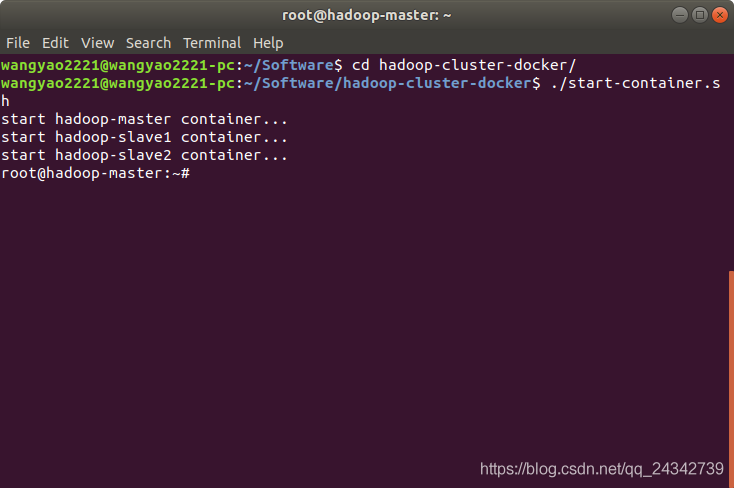
执行脚本,脚本在创建完容器之后进入了容器的终端
Docker命令补充
1、切换到本地终端而不关闭容器:快捷键Ctrl+P+Q,前一个步骤进入了容器的终端,如果我们想在这个窗口执行本地命令,而不想关闭当前容器,可以使用这个快捷前切换回本地终端,如下图所示:
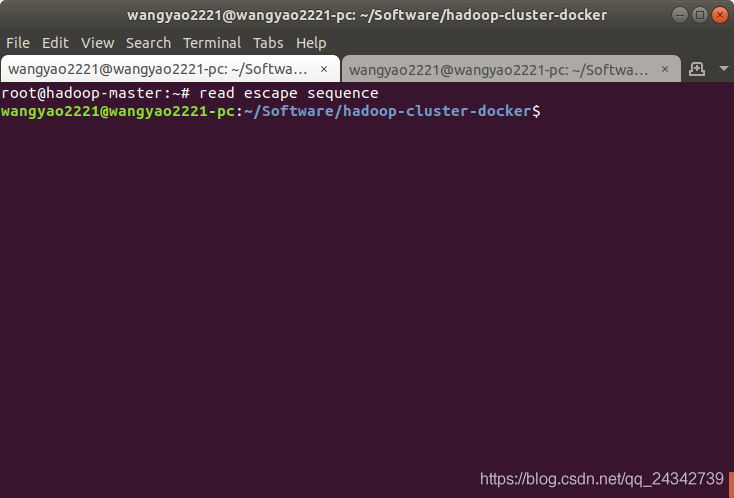
也可以通过新建一个终端窗口通过以下attach命令来进入容器终端,这种方式更方便一点,不需要使用命令来回切换终端
2、进入容器终端:在一个容器启动的情况下,我们想从本地终端切换到容器终端,可以使用docker的attach命令来切换:
# sudo docker attach [container-id]
sudo docker attach hadoop-master
3、以上两条是我们在后续步骤要多次用到的,在此提出,其他Docker命令请查看 菜鸟教程- Docker。
更换镜像源
- 在下一步中需要安装vim,在安装vim前需要执行sudo apt-get update更新软件源,这一步如果使用默认镜像源(国外源),更新速度会很慢,因此最好在次之前配置国内镜像源。
- 由于更换镜像源需要复制镜像源到文件中,而容器中只有vi(非vim)编辑器,vi的粘贴很难用(我不会用),所有采用在本机创建一个镜像源文件,然后通过Docker命令移动到Docker容器中的方法来修改镜像源文件。
首先新开一个本地终端,创建一个sources.list文件
gedit sources.list
- 将以下内容复制进去
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
- 在容器终端下备份一下sources.list文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.copy
- 在本地终端使用Docker命令将本地文件复制到Docker容器里
sudo docker cp sources.list hadoop-master:/etc/apt
- 最后在容器终端更新一下软件源
sudo apt-get update
安装vim
- 由于kiwenlau/hadoop:1.0这个镜像是没有安装vim编辑器,因此我们需要先把vim装上,方便后续查看文件,执行以下安装命令即可
# 安装vim
sudo apt-get install vim
启动Hadoop
在前面一个步骤的最后进入了Hadoop容器的终端(master节点),因为是已经配置好Hadoop的容器,所以可以直接使用Hadoop,在容器根目录下有一个启动Hadoop的脚本,脚本代码如下,启动了dfs和yarn:
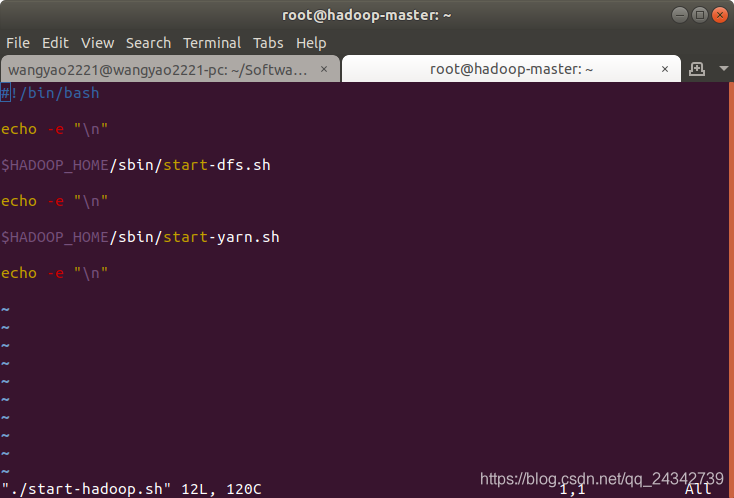
- 通过以下命令执行:
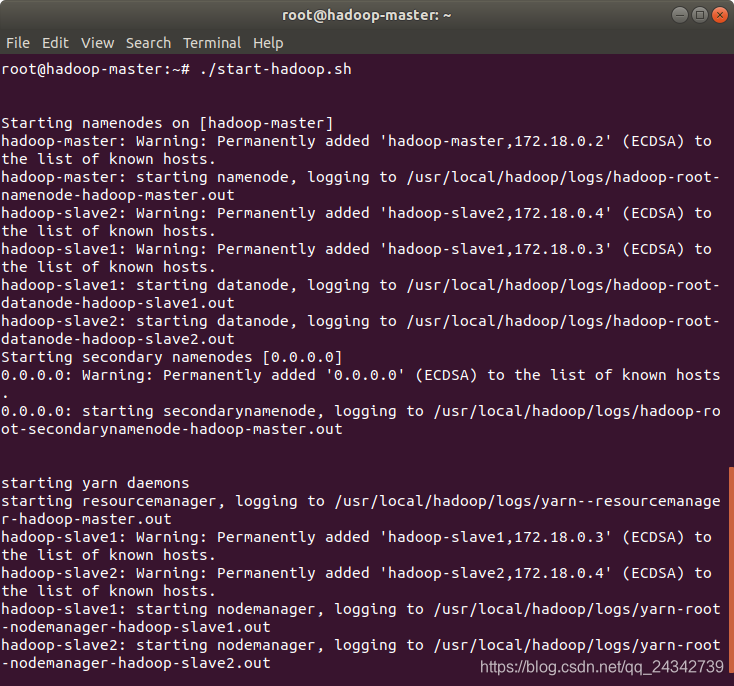
./start-hadoop.sh
出现以下信息说明Hadoop启动成功
测试Word Count
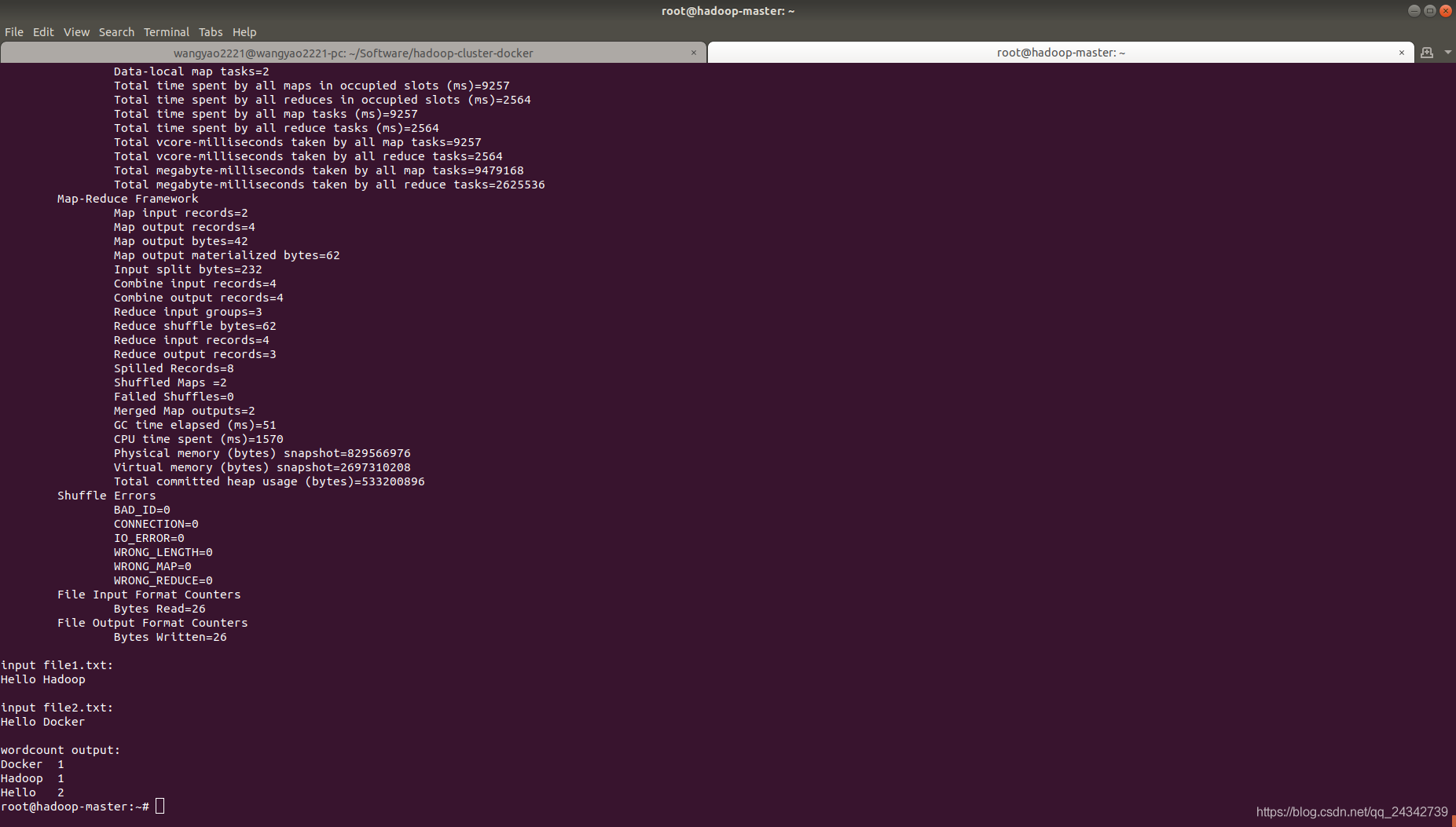
根目录下还有一个测试WordCount程序的脚本,WordCount是Hadoop里“Hello World”程序,是一个用于文本字符统计的MapReduce程序,先来看一下run-wordcount.sh这个脚本的内容,脚本往hdfs里添加了数据文件,然后执行了Hadoop里的例子hadoop-mapreduce-examples-2.7.2-sources.jar:

- 执行脚本
./run-wordcount.sh
输出结果没有报异常,且结果如下则WordCount程序执行成功
查看Web管理页面
- Name Node:[Your IP Address]:50070/
- 进入页面可以看到各节点的情况,注意如果Summary下的节点信息异常(容量为0、Live Nodes为0等)可能是配置过程出现了问题。
- 在导航栏的Utilities中有两个选项Browse the file system和Logs,前者是查看hdfs文件系统的,后者是查看Hadoop运行日志的,出现任何异常时可以在日志中查看,看能否找出异常原因。

- Resource Manager: [Your IP Address]:8088/
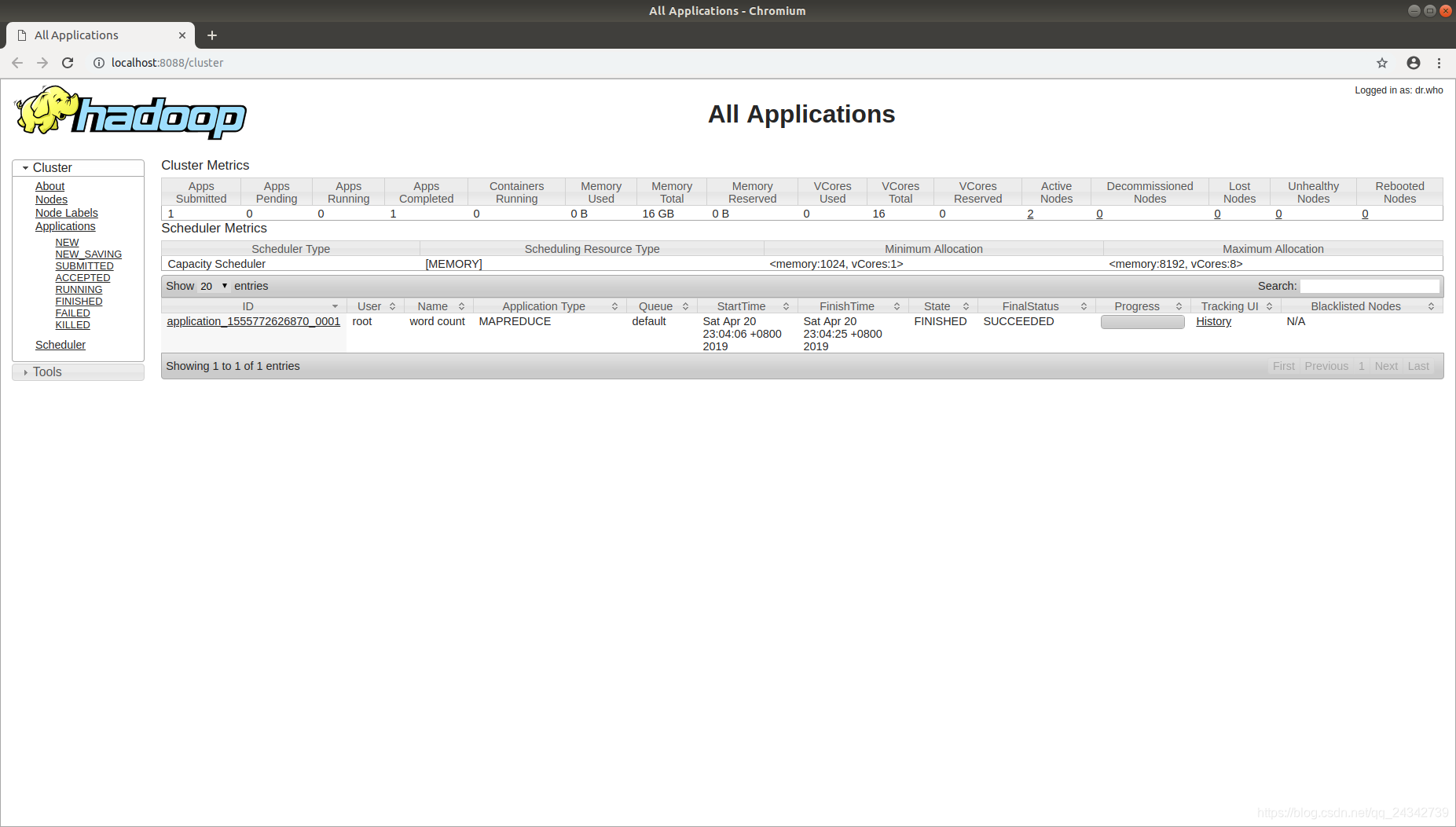
- 容器的IP可以在启动容器时的输出信息里找到,或者在开启的本地端口映射的情况下使用本地浏览器,IP使用localhost
Docker配置Hadoop环境的过程到此就结束了,下一篇IDEA调试Docker上的Hadoop会介绍如何在IDEA连接Docker配置的Hadoop容器,并且调试的文章,以便于Hadoop的深入学习。
参考”从 0 开始使用 Docker 快速搭建 Hadoop 集群环境“:https://www.jianshu.com/p/b75f8bc9346d
转载https://blog.csdn.net/qq_24342739/article/details/89420496
Docker搭建Hadoop环境的更多相关文章
- 使用docker搭建hadoop环境,并配置伪分布式模式
docker 1.下载docker镜像 docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop:latest 注:此镜像为阿里云个人上传镜 ...
- Docker 构建Hadoop环境
参考如下文章: Docker安装Hadoop Docker在本地搭建Hadoop分布式集群 Docker快速搭建Hadoop测试环境 从0开始用docker搭建 hadoop分布式环境 Docker- ...
- 使用docker搭建hadoop分布式集群
使用docker搭建部署hadoop分布式集群 在网上找了非常长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,仅仅能自己写一个了. 一:环境准备: 1:首先要有一个Cento ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- 基于Docker搭建Hadoop+Hive
为配合生产hadoop使用,在本地搭建测试环境,使用docker环境实现(主要是省事~),拉取阿里云已有hadoop镜像基础上,安装hive组件,参考下面两个专栏文章: 克里斯:基于 Docker 构 ...
- mac下通过docker搭建LEMP环境
在mac下通过docker搭建LEMP环境境 1.安装virtualbox.由于docker是在lxc环境的容器 2.安装boot2docker,用于与docker客户端通讯 > brew up ...
- 【一】、搭建Hadoop环境----本地、伪分布式
## 前期准备 1.搭建Hadoop环境需要Java的开发环境,所以需要先在LInux上安装java 2.将 jdk1.7.tar.gz 和hadoop 通过工具上传到Linux服务器上 3. ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- 【Devops】【docker】【CI/CD】1.docker搭建Gitlab环境
CI/CD[持续化集成/持续化交付] docker搭建Gitlab环境 1.查询并拉取gitlab镜像 docker search gitlab docker pull gitlab/gitlab-c ...
随机推荐
- springboot源码解析-管中窥豹系列之web服务器(七)
一.前言 Springboot源码解析是一件大工程,逐行逐句的去研究代码,会很枯燥,也不容易坚持下去. 我们不追求大而全,而是试着每次去研究一个小知识点,最终聚沙成塔,这就是我们的springboot ...
- PTA甲级—STL使用
1051 Pop Sequence (25分) [stack] 简答的栈模拟题,只要把过程想清楚就能做出来. 扫描到某个元素时候,假如比栈顶元素还大,说明包括其本身的在内的数字都应该入栈.将栈顶元素和 ...
- hdu4126Genghis Khan the Conqueror (最小生成树+树形dp)
Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 327680/327680 K (Java/Others) Total Submiss ...
- poj2411 Mondriaan's Dream (用1*2的矩形铺)
Description Squares and rectangles fascinated the famous Dutch painter Piet Mondriaan. One night, af ...
- 1.PowerShell DSC概述
什么是PowerShell DSC DSC 是一个声明性平台,用于配置.部署和管理系统. PowerShell PowerShell 是构建于 .NET 上基于任务的命令行 shell 和脚本语言. ...
- requests -- Python
使用requests方法后,会返回一个response对象,其存储了服务器响应的内容:如下r表示get请求后的响应对象r = requests.get('http://hz.58.com/sale.s ...
- 什么样的 SQL 不走索引
参考: MySQL 索引优化全攻略 索引建立的规则 1.能创建唯一索引就创建唯一索引 2.为经常需要排序.分组和联合操作的字段建立索引 3.为常作为查询条件的字段建立索引 如果某个字段经常用来做查询条 ...
- 网站日志统计以及SOA架构
网站日志统计相关术语 PV(Page View):页面浏览量或点击量,衡量用户访问的网页数量 UV(Unique Visitor):独立设备的访问次数,根据客户端发送的 Cookie 区分 IP(In ...
- Kubernets二进制安装(3)之准备签发证书环境
1.在mfyxw50机器上分别下载如下几个文件:cfssl.cfssl-json.cfssl-certinfo cfssl下载连接地址: https://pkg.cfssl.org/R1.2/cfss ...
- 1.利用consul实现k8s服务自动发现
标题 : 1.利用consul实现k8s服务自动发现 目录 : 微服务架构设计 序号 : 1 ] } } ] } } - consul自身支持ACL,但目前,Helm图表不支持其中一些功能,需要额 ...