sklearn preprocessing (预处理)
预处理的几种方法:标准化、数据最大最小缩放处理、正则化、特征二值化和数据缺失值处理。
知识回顾:

p-范数:先算绝对值的p次方,再求和,再开p次方。
数据标准化:尽量将数据转化为均值为0,方差为1的数据,形如标准正态分布(高斯分布)。
标准化(Standardization)
公式为:(X-X_mean)/X_std 计算时对每个属性/每列分别进行。
将数据按其属性(按列进行)减去其均值,然后除以其方差。最后得到的结果是,对每个属性/每列来说所有数据都聚集在0附近,方差值为1。
sklearn中preprocessing库里面的scale函数使用方法:
sklearn.preprocessing.scale(X, axis=0, with_mean=True, with_std=True, copy=True)
根据参数不同,可以沿任意轴标准化数据集。
参数:
- X:数组或者矩阵
- axis:int类型,初始值为0,axis用来计算均值和标准方差。如果是0,则单独的标准化每个特征(列),如果是1,则标准化每个观测样本(行)。
- with_mean:boolean类型,默认为True,表示将数据均值规范到0。
- with_std:boolean类型,默认为True,表示将数据方差规范到1。
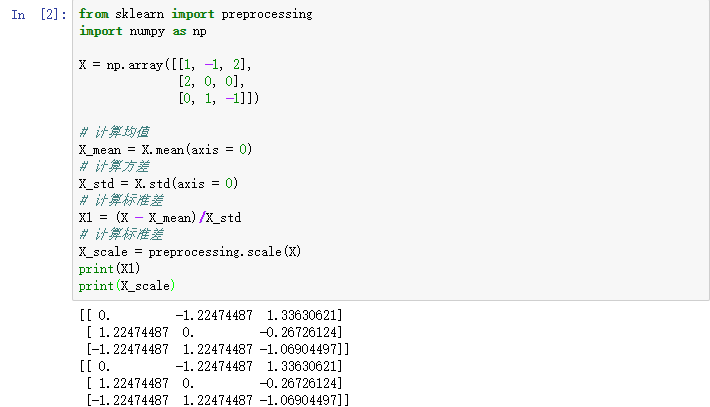
范例:假设现在构造一个数据集X,然后想要将其标准化。
方法一:使用sklearn.preprocessing.scale()函数
方法说明:
- X.mean(axis=0)用来计算数据X每个特征的均值;
- X.std(axis=0)用来计算数据X每个特征的方差;
- preprocessing.scale(X)直接标准化数据X。
方法二:sklearn.preprocessing.StandardScaler类
sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
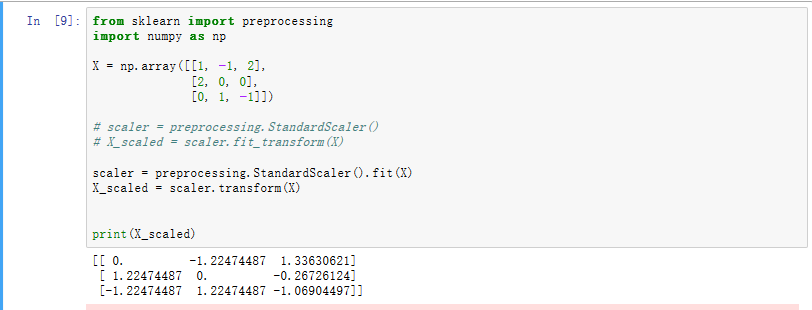
scaler = preprocessing.StandardScaler()
X_scaled = scaler.fit_transform(X)scaler = preprocessing.StandardScaler().fit(X)
X_scaled = scaler.transform(X)
上面两段代码等价。
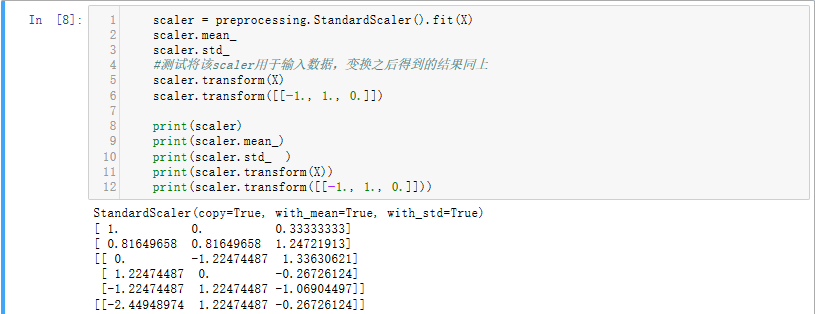
转换器(Transformer)主要有三个方法:
fit():训练算法,拟合数据
transform():标准化数据
fit_transform():先拟合数据,再标准化。
sklearn preprocessing (预处理)的更多相关文章
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
- sklearn学习笔记(一)——数据预处理 sklearn.preprocessing
https://blog.csdn.net/zhangyang10d/article/details/53418227 数据预处理 sklearn.preprocessing 标准化 (Standar ...
- Python数据预处理(sklearn.preprocessing)—归一化(MinMaxScaler),标准化(StandardScaler),正则化(Normalizer, normalize)
关于数据预处理的几个概念 归一化 (Normalization): 属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现. 常 ...
- sklearn preprocessing 数据预处理(OneHotEncoder)
1. one hot encoder sklearn.preprocessing.OneHotEncoder one hot encoder 不仅对 label 可以进行编码,还可对 categori ...
- sklearn数据预处理-scale
对数据按列属性进行scale处理后,每列的数据均值变成0,标准差变为1.可通过下面的例子加深理解: from sklearn import preprocessing import numpy as ...
- sklearn数据预处理
一.standardization 之所以标准化的原因是,如果数据集中的某个特征的取值不服从标准的正太分布,则性能就会变得很差 ①函数scale提供了快速和简单的方法在单个数组形式的数据集上来执行标准 ...
- Scikit-learn Preprocessing 预处理
本文主要是对照scikit-learn的preprocessing章节结合代码简单的回顾下预处理技术的几种方法,主要包括标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 数学基础 均 ...
- 数据规范化——sklearn.preprocessing
sklearn实现---归类为5大类 sklearn.preprocessing.scale()(最常用,易受异常值影响) sklearn.preprocessing.StandardScaler() ...
- sklearn 数据预处理1: StandardScaler
作用:去均值和方差归一化.且是针对每一个特征维度来做的,而不是针对样本. [注:] 并不是所有的标准化都能给estimator带来好处. “Standardization of a dataset i ...
随机推荐
- amoeba读写分离
第一单元 高性能mysql读写分离的实现 5.1 mysql读写分离 5.1.1 mysql读写分离概述 5.1.2 mysql读写分离原理 5.2 mysql读写分离配置 ...
- VisualSVN Server 服务器搭建 和 TortoiseSVN的配置和使用方法
摘自:https://blog.csdn.net/litaoshoujiao/article/details/8526136 一.VisualSVN Server的配置和使用方法[服务器端] 安装好V ...
- 怎样从外网访问内网SQLServer数据库?
本地安装了一个SQLServer数据库,只能在局域网内访问到,怎样从外网也能访问到本地的SQLServer数据库呢?本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动SQLServer数据 ...
- 每日linux命令学习-grep模式检索
grep模式检索指令包括grep,egrep,和fgrep,.Linux系统使用正则表达式优化文本检索,所以在此,笔者首先学习了一下正则表达式. 1. 正则表达式 正则表达式使用被称为元字符(Meta ...
- jsoi r2d1t3的50分
#include<bits/stdc++.h> using namespace std; int n,r,x,y; double ans; double dis(int x,int y){ ...
- Lucene的入门
Lucene准备 Lucene可以在官网上下载,我这里已经下载好了,用的是4.10.3版本的, 解压以后的文件为: 如果没有使用maven管理的话,就需要引入这三个jar包,实现lucene功能. 我 ...
- django实现类似触发器的效果
https://blog.csdn.net/pushiqiang/article/details/50652080?utm_source=blogxgwz1 https://blog.csdn.net ...
- Fiddler(一)Fiddler介绍及应用场景
Fiddler是一款网络抓包工具,抓包可以是抓取电脑端请求的数据,还可以抓取移动端(手机APP)的数据包,可以监控HTTP和HTTPS的流量,可以通过浏览器或者客户端软件向服务器发送的HTTP或者HT ...
- 关于actor模型
actor model是1973年就提出的一个分布式并发编程模型,在erlang语言中得到广泛支持和应用.目前Java中也出现了很多支持actor模型的库:akka.killim.jetlang等等, ...
- py4CV例子2.5车牌识别和svm算法重构
1.什easypr数据集: ) ) ] all_label_list = temp[:, ] n_sample = , ) matcher = cv2.FlannBasedMatcher(flann ...