组合数据类型,英文词频统计 python
练习:
总结列表,元组,字典,集合的联系与区别。列表,元组,字典,集合的遍历。
区别:
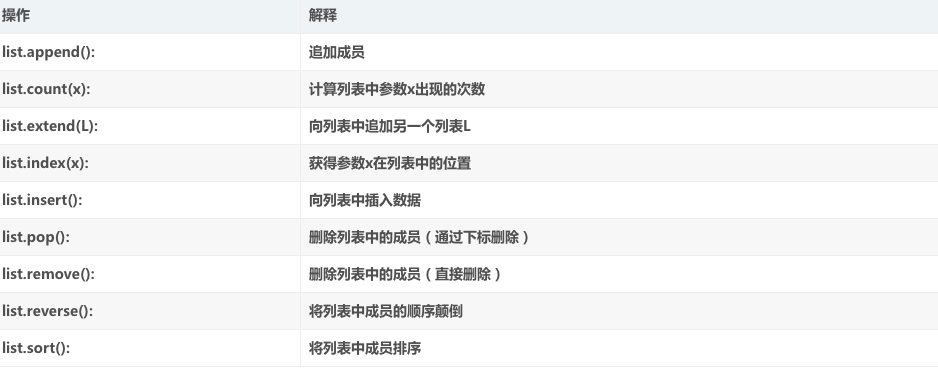
一、列表:列表给大家的印象是索引,有了索引就是有序,想要存储有序的项目,用列表是再好不过的选择了。在python中的列表很好区分,遇到中括号(即[ ]),都是列表,定义列表也是如此。列表中的数据可以进行增删查改等操作;
增加有两种表达方式(append()、expend()),关于append的用法如下(注:mylist定义的列表名称):不难看出,用append方法增加元素,不用给元素加中括号,而用extend方法加元素(一个元素可以不用中括号),(多个元素)必须要用一个中括号。
【mylist.append(5) >>>[1, 2, [3, 4], 5]
mylist.append([5]) >>>[1, 2, [3, 4], [5]]
mylist.extend([5]) >>> mylist.expand(1, 2, [3, 4], 5) 】
删除元素:del mylist[0] 既删除了mylist的第一个元素。
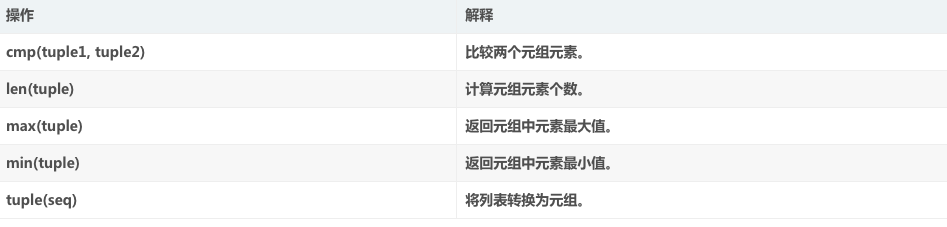
二、元组:元组给我的感觉,是列表的儿子,儿子终究是儿子,元组不可以进行删改,但可以查询、删除、增加。如以下代码所示(定义元组名字 yubin=("sun","yu","bin")):
删除元素:del yubin[0] ; 删除元素,查找元素是要用索引值,这点和列表list类似
索引元素:yubin.index["sun"] 索引元素,不是通过索引值来索引的,而是通过名字来索引的。
增加元素:yubin.append("az") 增加元素,这也和列表倒也没有太大的差别。

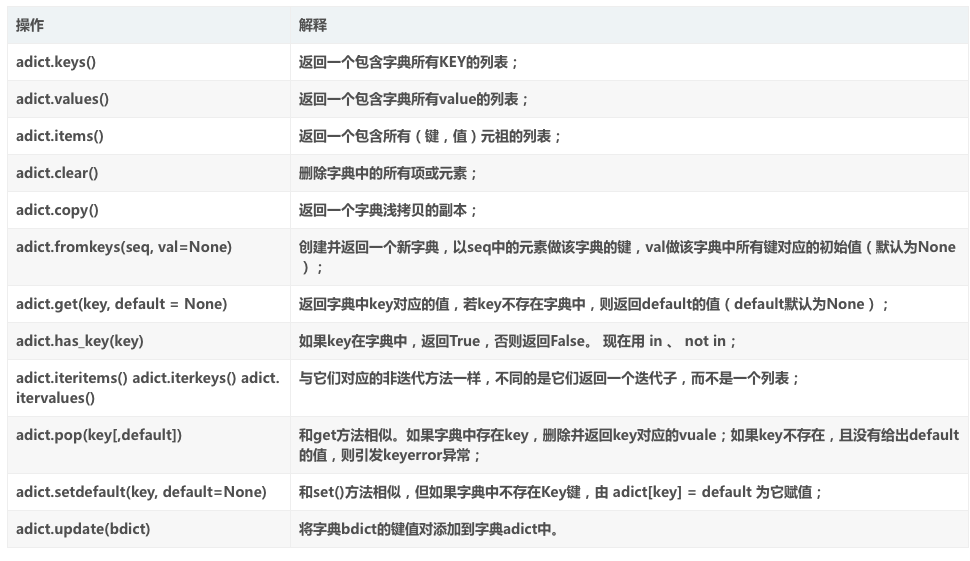
三、字典:字典是我用的最多的,说到字典,最离不开的就是“键值对”,键既是key,也是一个属性的名字,值就是这个属性的具体表现,可以是整型、字符型...字典没有排序,其输出的顺序也是按照先前定义时候的顺序输出。定义字典:sunyubin={"name":"sunyubin","age":22,"gender":"boy"}
删除元素:del.sunyubin[name]
四、集合:说到集合,首先想到就是set,其次是每个元素之间,用逗号(,)相隔。而且还不能有重复元素。
写入代码:
# 两种方法创建
set1 = set('kydaa')
set2 = {'abc', 'jaja', 'abc', 'kyda'}
print(set1)
print(set2)
输出代码:结构自动去重
{'a', 'y', 'd', 'k'}
{'jaja', 'abc', 'kyda'}
集合的方法:

英文词频统计:下载一首英文的歌词或文章str,分隔出一个一个的单词 list,统计每个单词出现的次数 dict。
有错误,在修改中
def getTxt():
txt = open("music").read()
txt = txt.lower()
for ch in '!"@#$%^&*()+,-./:;<=>?@[\\]_`~{|}':
txt.replace(ch," ")
return txt hamletTxt = getTxt() txtArr = hamletTxt.split() counts = {}
for word in txtArr:
counts[word] = counts.get(word,0)+1 countList = list(counts.items())
countList.sort(key=lambda x:x[1], reverse=True) for i in range(10):
word, count = countList[i]
print('{0:<10}{1:>5}'.format(word,count))
方法二:
with open('music','r') as f:
niubi = f.read()
niubi = niubi.lower()
print('全部转换为小写的结果:' + niubi + '\n')
for p in ''',.?!’':"“”-%$''':
niubi = niubi.replace(p, ' ')
print('分隔符替换为空格的结果:' + niubi + '\n')
split = niubi.split()
word = {}
for i in split:
count = niubi.count(i)
word[i] = count
words = '''
a an the in on to at and of is was are were i he she you your they us their our it or for be too do no
that s so as but it's don't
'''
prep = words.split()
for i in prep:
if i in word.keys():
del (word[i])
word = sorted(word.items(), key=lambda item: item[1], reverse=True)
for i in range(10):
print(word[i])
组合数据类型,英文词频统计 python的更多相关文章
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- Python——字符串、文件操作,英文词频统计预处理
一.字符串操作: 解析身份证号:生日.性别.出生地等. 凯撒密码编码与解码 网址观察与批量生成 2.凯撒密码编码与解码 凯撒加密法的替换方法是通过排列明文和密文字母表,密文字母表示通过将明文字母表向左 ...
- python字符串操作、文件操作,英文词频统计预处理
1.字符串操作: 解析身份证号:生日.性别.出生地等. 凯撒密码编码与解码 网址观察与批量生成 解析身份证号:生日.性别.出生地等 def function3(): print('请输入身份证号') ...
- 1.字符串操作:& 2.英文词频统计预处理
1.字符串操作: 解析身份证号:生日.性别.出生地等. ID = input('请输入十八位身份证号码: ') if len(ID) == 18: print("你的身份证号码是 " ...
- Programming | 中/ 英文词频统计(MATLAB实现)
一.英文词频统计 英文词频统计很简单,只需借助split断句,再统计即可. 完整MATLAB代码: function wordcount %思路:中文词频统计涉及到对"词语"的判断 ...
- python复合数据类型以及英文词频统计
这个作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753. 1.列表,元组,字典,集合分别如何增删改查及遍历. 列 ...
- 爬取腾讯网的热点新闻文章 并进行词频统计(Python爬虫+词频统计)
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:一棵程序树 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- python:Hamlet英文词频统计
#CalHamletV1.py def getText(): #定义函数读取文件 txt = open("hamlet.txt","r").read() txt ...
- 英文词频统计的java实现方法
需求概要 1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符. 2.统计英文单词在本文件的出现次数 3.将统计结果排序 4.显示排序结果 分析 1.读取文件可使用BufferedReader ...
随机推荐
- css3 居中(推荐弹性盒模型方式)
参考 http://www.zhihu.com/question/20774514 http://caibaojian.com/demo/flexbox/align-items.html 例子:ht ...
- unity中实现三个Logo图片进行3秒钟的若隐若现后互相切换Logo图片
private List<Sprite> storeTexture; public void Start() { storeTexture = new List<Sprite> ...
- 【原创】<Debug> QString
[问题1] 'class QString' has no member named 'toAscii' [解答] 把toAscii().data()改成toLatin1().data() 如果QStr ...
- Git的基本使用(github)
关于Git的基本使用: 上传本地文件到github仓库中 首先要有自己的github账号,新建仓库: saiku-3.9 其次 本地安装好 git , 在本地任意目录下新建目录 saiku-3.9, ...
- bluemix部署(二)构建kubernetes工作环境
本文接上篇.在bluemix中构建kubernetes容器. 1.创建集群 左上角的三横,选容器,然后创建集群. 注意区域,免费版,给个名字,创建集群吧. 继续正在部署,这个可能要15-30分钟,真不 ...
- Android : android 8.0 audio 接口分析
1.HIDL 的概念 HIDL 读作 hide-l,全称是 Hardware Interface Definition Language.它在 Android Project Treble 中被起草, ...
- html 经验之谈
- python笔记6-while、for循环
1.while--while循环之前,先判断一次,如果满足条件的话,再循环 #while循环 count=(input("请输入循环次数"))#计数器 while count< ...
- springboot学习章节代码-spring基础
1.DI package com.zhen.highlights_spring4.ch1.di; import org.springframework.stereotype.Service; /** ...
- HTML5中的data-*属性和jQuery中的.data()方法使用
原文地址链接:http://blog.csdn.net/fly_zxy/article/details/50687691: HTML5中的data-*属性 我们往往会根据需要在HTML标记上添加自定义 ...