python XML文件解析:用ElementTree解析XML
Python标准库中,提供了ET的两种实现。一个是纯Python实现的xml.etree.ElementTree,另一个是速度更快的C语言实现xml.etree.cElementTree。请记住始终使用C语言实现,因为它的速度要快很多,而且内存消耗也要少很多。如果你所使用的Python版本中没有cElementTree所需的加速模块,你可以这样导入模块
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
xml file
<?xml version="1.0"?>
<doc>
<branch name="codingpy.com" hash="1cdf045c">
text,source
</branch>
<branch name="release01" hash="f200013e">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
<branch name="invalid">
</branch>
</doc>
1、将XML文档解析为树(tree)
加载这个文档,并进行解析
>>> import xml.etree.ElementTree as ET >>> tree = ET.ElementTree(file='doc1.xml')
获取根元素(root element):
>>> tree.getroot() <Element 'doc' at 0x11eb780>
根元素(root)是一个Element对象,看根元素都有哪些属性:
>>> root = tree.getroot()
>>> root.tag, root.attrib
('doc', {})
根元素并没有属性。与其他Element对象一样,根元素也具备遍历其直接子元素的接口:
>>> for child_of_root in root:
... print child_of_root.tag, child_of_root.attrib
...
branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
branch {'hash': 'f200013e', 'name': 'release01'}
branch {'name': 'invalid'}
还可以通过索引值来访问特定的子元素:
>>> root[0].tag, root[0].text
('branch', '\n text,source\n ')
2、查找需要的元素
Element对象有一个iter方法,可以对某个元素对象之下所有的子元素进行深度优先遍历(DFS)。ElementTree对象同样也有这个方法。下面是查找XML文档中所有元素的最简单方法:
>>> for elem in tree.iter():
... print elem.tag, elem.attrib
...
doc {}
branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
branch {'hash': 'f200013e', 'name': 'release01'}
sub-branch {'name': 'subrelease01'}
branch {'name': 'invalid'}
可以对树进行任意遍历——遍历所有元素,查找出自己感兴趣的属性。但是ET可以让这个工作更加简便、快捷。iter方法可以接受tag名称,然后遍历所有具备所提供tag的元素:
>>> for elem in tree.iter(tag='branch'):
... print elem.tag, elem.attrib
...
branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
branch {'hash': 'f200013e', 'name': 'release01'}
branch {'name': 'invalid'}
3、支持通过XPath查找元素
使用XPath查找感兴趣的元素,更加方便。Element对象中有一些find方法可以接受Xpath路径作为参数,find方法会返回第一个匹配的子元素,findall以列表的形式返回所有匹配的子元素, iterfind则返回一个所有匹配元素的迭代器(iterator)。ElementTree对象也具备这些方法,相应地它的查找是从根节点开始的。
下面是一个使用XPath查找元素的示例:
>>> for elem in tree.iterfind('branch/sub-branch'):
... print elem.tag, elem.attrib
...
sub-branch {'name': 'subrelease01'}
上面的代码返回了branch元素之下所有tag为sub-branch的元素。接下来查找所有具备某个name属性的branch元素:
>>> for elem in tree.iterfind('branch[@name="release01"]'):
... print elem.tag, elem.attrib
...
branch {'hash': 'f200013e', 'name': 'release01'}
4、构建XML文档
利用ET,很容易就可以完成XML文档构建,并写入保存为文件。ElementTree对象的write方法就可以实现这个需求。
一般来说,有两种主要使用场景。一是你先读取一个XML文档,进行修改,然后再将修改写入文档,二是从头创建一个新XML文档。
修改文档的话,可以通过调整Element对象来实现。请看下面的例子:
>>> root = tree.getroot()
>>> del root[2]
>>> root[0].set('foo', 'bar')
>>> for subelem in root:
... print subelem.tag, subelem.attrib
...
branch {'foo': 'bar', 'hash': '1cdf045c', 'name': 'codingpy.com'}
branch {'hash': 'f200013e', 'name': 'release01'}
在上面的代码中,我们删除了root元素的第三个子元素,为第一个子元素增加了新属性。这个树可以重新写入至文件中。最终的XML文档应该是下面这样的:
>>> import sys
>>> tree.write(sys.stdout)
<doc>
<branch foo="bar" hash="1cdf045c" name="codingpy.com">
text,source
</branch>
<branch hash="f200013e" name="release01">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
</doc>
请注意,文档中元素的属性顺序与原文档不同。这是因为ET是以字典的形式保存属性的,而字典是一个无序的数据结构。当然,XML也不关注属性的顺序。
从头构建一个完整的文档也很容易。ET模块提供了一个SubElement工厂函数,让创建元素的过程变得很简单:
>>> a = ET.Element('elem')
>>> c = ET.SubElement(a, 'child1')
>>> c.text = "some text"
>>> d = ET.SubElement(a, 'child2')
>>> b = ET.Element('elem_b')
>>> root = ET.Element('root')
>>> root.extend((a, b))
>>> tree = ET.ElementTree(root)
>>> tree.write(sys.stdout)
<root><elem><child1>some text</child1><child2 /></elem><elem_b /></root>
拿例子敲下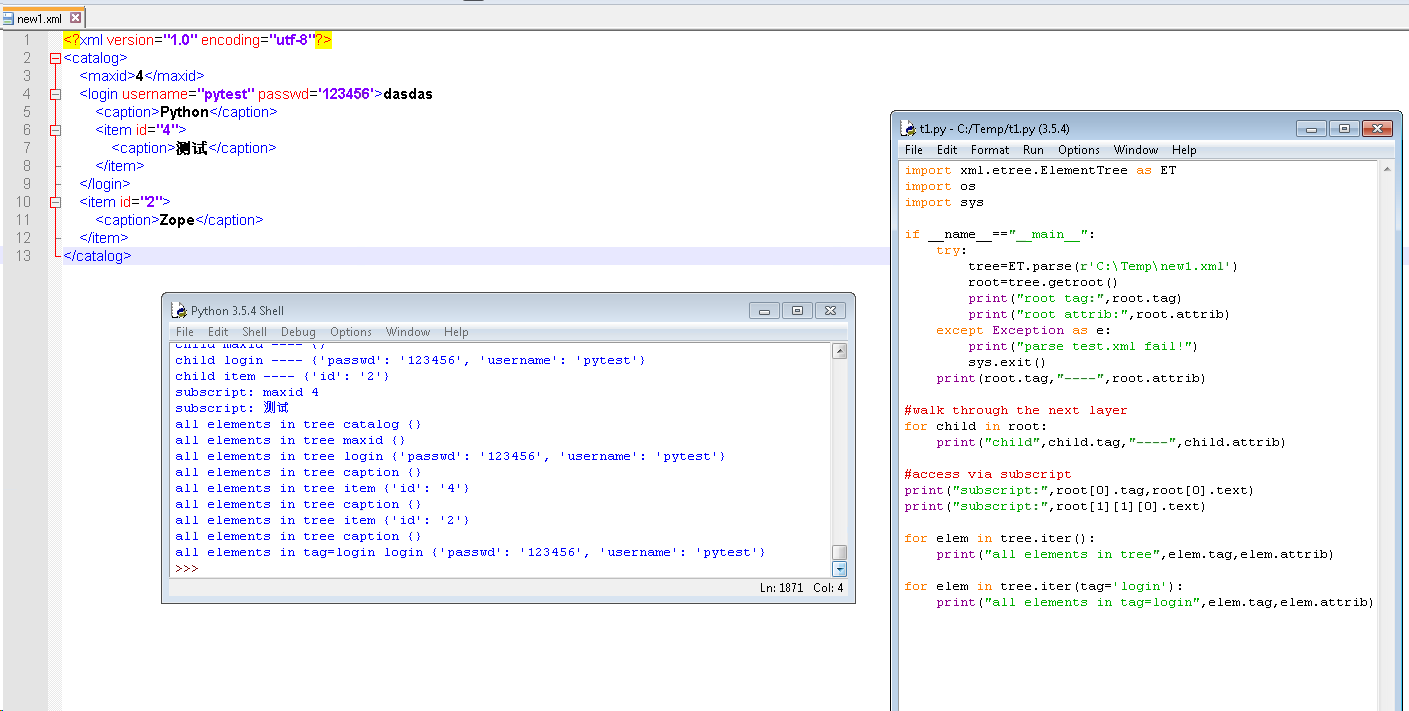
python XML文件解析:用ElementTree解析XML的更多相关文章
- Spring如何解析XML文件——Spring源码之XML初解析
首先,在我的这篇博客中已经说到容器是怎么初步实现的,并且要使用XmlBeanDefinitionReader对象对Xml文件进行解析,那么Xml文件是如何进行解析的,将在这片博客中进行一些陈述. 数据 ...
- 如何在web.xml文件中引入其他的xml文件(拆分web.xml)
转载自:http://www.blogjava.net/jiangjf/archive/2009/04/09/264685.html 最近在做一个Servlet+javaBean的项目,服务器用的是t ...
- Spring框架找不到 applicationContext.xml文件,可能是由于applicationContext.xml文件的路径没有放在根目录下造成的
Spring框架找不到 applicationContext.xml文件,可能是由于applicationContext.xml文件的路径没有放在根目录下造成的
- python解析xml文件时使用ElementTree和cElementTree的不同点;iter
在python中,解析xml文件时,会选用ElementTree或者cElementTree,那么两者有什么不同呢? 1.cElementTree速度上要比ElementTree快,比较cElemen ...
- Python解析xml文件遇到的编码解析的问题
使用python对xml文件进行解析的时候,假设xml文件的头文件是utf-8格式的编码,那么解析是ok的,但假设是其它格式将会出现例如以下异常: xml.parsers.expat.ExpatErr ...
- xml文件的生成与解析
生成方法一:同事StringBuffer类对xml文件格式解析写入 package com.steel_rocky.xml; import android.app.Activity; import a ...
- 使用XML序列化器生成XML文件和利用pull解析XML文件
首先,指定XML格式,我指定的XML格式如下: <?xml version='1.0' encoding='utf-8' standalone='yes' ?> <message&g ...
- XML文件的创建和解析笔记
解析XML的四种方法 XML现在已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便.对于XML本身的语法知识与技术细节,需要阅读相关的技术文献,这 ...
- 解析XML文件之使用SAM解析器
XML是一种常见的传输数据方式,所以在开发中,我们会遇到对XML文件进行解析的时候,本篇主要介绍使用SAM解析器,对XML文件进行解析. SAX解析器的长处是显而易见的.那就是SAX并不须要将全部的文 ...
- XML概念定义以及如何定义xml文件编写约束条件java解析xml DTD XML Schema JAXP java xml解析 dom4j 解析 xpath dom sax
本文主要涉及:xml概念描述,xml的约束文件,dtd,xsd文件的定义使用,如何在xml中引用xsd文件,如何使用java解析xml,解析xml方式dom sax,dom4j解析xml文件 XML来 ...
随机推荐
- bug:使用UIImageView+AFNetworking 图片不能正常显示的原因
今天调的东西涉及到图片加载,我刚看了下项目里以前导入了SDWebImage库,又发现整个就一个地方使用到了SDWebImage异步加载图片的方法,感觉占体积又鸡肋,干脆去掉,用UIImageView+ ...
- 使用github的srs代码,搭建 RTMP_Server
1. 搭建RTMP服务器 1> 获取开源代码SRS. git clone https://github.com/ossrs/srs 下载源码后,按照如下文档安装https://github.co ...
- (1.7)mysql profiles分析
mysql profiles分析 作用:记录会话查询SQL所用时间 1.开启 2.使用 [2.1]先使用一个查询 [2.2]然后再运行 show profiles; [2.3]查看执行过程中每个状态和 ...
- df 查看磁盘大小
[root@salt-server- sh]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/VolGroup-lv_roo ...
- 中文全文检索讯搜xunsearch安装
Xunsearch (迅搜)是一套免费开源的专业中文全文检索解决方案,简单易用而且 功能强大.性能卓越能轻松处理海量数据的全文检索.它包含后端索引.搜索服务程序和前端 脚本语言编写的开发工具包(称之为 ...
- UIDatePicker封装
#import <UIKit/UIKit.h> #import <objc/runtime.h> @protocol datePickerViewDelegate <NS ...
- 下载pywin32
下载pywin32 链接:sourceforge.net/projects/pywin32/files/ 1.找到一个pywin32的文件夹 2.下一级目录里面有多个文件夹. 3.打开Build222 ...
- https://github.com/Lushenggang/show-pdf在线浏览pdf文件在线浏览pdf文件
在线浏览pdf文件 https://github.com/Lushenggang/show-pdf https://github.com/Lushenggang/show-pdf
- sap 程序之间的相互调用
1:首先进入到local object 目录下. 右键>create >function group,创建一个函数组. 右键创建类其它的东西 2:在创建的function group(fu ...
- Wix制作安装包
Wix制作安装包,找起资料来很费劲,记录一下: Product.wxs,该文件只能制作出msi形式的安装包,不能做到自动检测framework. <?xml version="1.0& ...