MongoDB journal与oplog解惑
journal
journal 是 MongoDB 存储引擎层的概念,目前 MongoDB主要支持 mmapv1、wiredtiger、mongorocks 等存储引擎,都支持配置journal。
MongoDB 所有的数据写入、读取最终都是调存储引擎层的接口来存储、读取数据,journal 是存储引擎存储数据时的一种辅助机制。
默认情况下mongodb每100毫秒往journal文件中flush一次数据,不过这是在数据文件和journal文件处于同一磁盘卷上的情况,而如果数据文件和journal文件不在同一磁盘卷上时,默认刷新输出时间是30毫秒。不过这个毫秒值是可以修改的,可修改范围是2~300,值越低,刷新输出频率越高,数据安全度也就越高,但磁盘性能上的开销也更高。
以wiredtiger 为例,如果不配置 journal,写入 wiredtiger 的数据,并不会立即持久化存储;而是每分钟会做一次全量的checkpoint(storage.syncPeriodSecs配置项,默认为1分钟),将所有的数据持久化。如果中间出现宕机,那么数据只能恢复到最近的一次checkpoint,这样最多可能丢掉1分钟的数据。
所以建议「一定要开启journal」,开启 journal 后,每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。这样即使出现宕机,启动时 Wiredtiger 会先将数据恢复到最近的一次checkpoint的点,然后重放后续的 journal 操作日志来恢复数据。
journal文件是以“j._”开头命名的,且是append only的,如果1个journal文件满了1G大小,mongodb就会新创建一个journal文件来使用,一旦某个journal文件所记载的写操作都被使用过了,mongodb就会把这个journal文件删除。通常在journal文件所在的文件夹下,只会存在2~3个journal文件,除非你使用mongodb每秒都写入大量的数据。而使用 smallfiles 这个运行时选项可以将journal文件大小减至128M大小。
MongoDB 里的 journal 行为 主要由2个参数控制,storage.journal.enabled 决定是否开启journal,storage.journal.commitInternalMs 决定 journal 刷盘的间隔,默认为100ms,用户也可以通过写入时指定 writeConcern 为 {j: ture} 来每次写入时都确保 journal 刷盘。
oplog
oplog 是 MongoDB 主从复制层面的一个概念,通过 oplog 来实现复制集节点间数据同步,客户端将数据写入到 Primary,Primary 写入数据后会记录一条 oplog,Secondary 从 Primary(或其他 Secondary )拉取 oplog 并重放,来确保复制集里每个节点存储相同的数据。
oplog 在 MongoDB 里是一个普通的 capped collection,对于存储引擎来说,oplog只是一部分普通的数据而已。
MongoDB 的一次写入
MongoDB 复制集里写入一个文档时,需要修改如下数据
- 将文档数据写入对应的集合
- 更新集合的所有索引信息
- 写入一条oplog用于同步
上面3个修改操作,需要确保要么都成功,要么都失败,不能出现部分成功的情况,否则
- 如果数据写入成功,但索引写入失败,那么会出现某个数据,通过全表扫描能读取到,但通过索引就无法读取
- 如果数据、索引都写入成功,但 oplog 写入不成功,那么写入操作就不能正常的同步到备节点,出现主备数据不一致的情况
MongoDB 在写入数据时,会将上述3个操作放到一个 wiredtiger 的事务里,确保「原子性」。
beginTransaction();
writeDataToColleciton();
writeCollectionIndex();
writeOplog();
commitTransaction();
wiredtiger 提交事务时,会将所有修改操作应用,并将上述3个操作写入到一条 journal 操作日志里;后台会周期性的checkpoint,将修改持久化,并移除无用的journal。
从数据布局看,oplog 与 journal 的关系
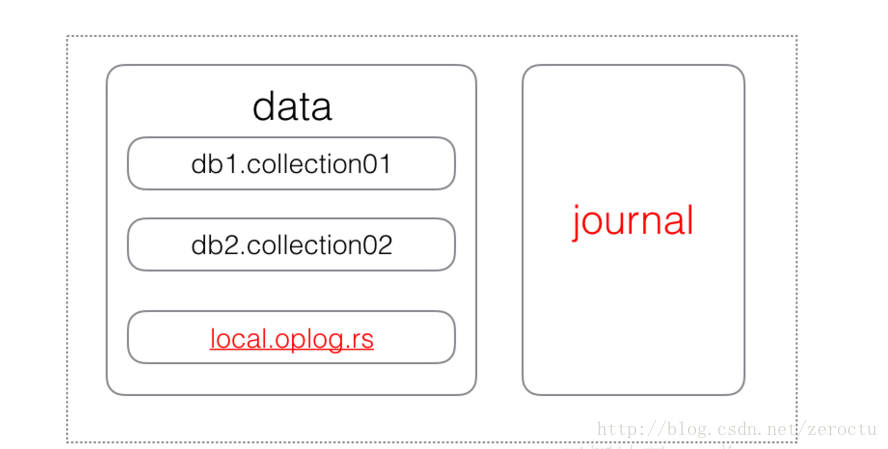
谁先写入??
- oplog 与 journal 是 MongoDB 里不同层次的概念,放在一起比先后本身是不合理的。
- oplog 在 MongoDB 里是一个普通的集合,所以 oplog 的写入与普通集合的写入并无区别。
- 一次写入,会对应数据、索引,oplog的修改,而这3个修改,会对应一条journal操作日志。
MongoDB journal与oplog解惑的更多相关文章
- MongoDB journal 与 oplog,究竟谁先写入?
MongoDB journal 与 oplog,谁先写入?最近经常被人问到,本文主要科普一下 MongoDB 里 oplog 以及 journal 这两个概念. journal journal 是 M ...
- MongoDB journal 与 oplog,究竟谁先写入?--转载
MongoDB journal 与 oplog,谁先写入?最近经常被人问到,本文主要科普一下 MongoDB 里 oplog 以及 journal 这两个概念. journal journal 是 M ...
- 转:MongoDB · 引擎特性 · journal 与 oplog,究竟谁先写入?
转:MongoDB · 引擎特性 · journal 与 oplog,究竟谁先写入? 数据库内核月报 链接:http://mysql.taobao.org/monthly/2018/05/07/ Mo ...
- 单台MongoDB实例开启Oplog
背景 随着数据的积累,MongoDB中的数据量越来越大,数据分析团队从数据库中抽取变化数据(假如依据栏位createdatetime,transdatetime),越来越困难.我们知道MongoDB的 ...
- mongodb:修改oplog.rs 的大小size
其内容字段说明: ts:操作日志的timestamp t: 未知? h:操作唯一随机值 v:oplog.rs的版本 op:操作类型: i:insert操作 u:update操作 d:delete操作 ...
- 云数据库MongoDB版清理oplog日志和compact命令详解
1.问题描述: 今天看到公司mongodb的oplog有点大,看到云数据库MongoDB版日志清理策略. MongoDB数据库在长期频繁地删除/写入数据或批量删除了大量数据,将产生很多物理空间碎片. ...
- MongoDB 如何保证 oplog 顺序?
MongoDB 复制集里,主备节点间通过 oplog 来同步数据,Priamry 上写入数据时,会记录一条oplog,Secondary 从 Primary 节点拉取 oplog并重放,以保证最终存储 ...
- mongodb的oplog遇到的问题
mongodb调整oplog的大小的方法 关闭当前服务器,将服务器以单机模式启动.这是一种方法,还有没有其他方法? mongodb实时扫描oplog,判断记录到哪个地方了 如果扫描oplog的程序挂掉 ...
- MongoDB副本集配置系列七:MongoDB oplog详解
1:oplog简介 oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的.每个节点都有oplog,记录这从主节点复制过来的信息,这样 ...
随机推荐
- Python 基础day3
1.简述bit,byte,kb,MB,GB,TB的关系 1TB=1024GB; 1GB=1024MB ; 1MB=1024kb: 1kb=1024byte ; 1byte=8bit 2.简述as ...
- foreman ubuntu16快速安装
Quickstart Guide The Foreman installer is a collection of Puppet modules that installs everything re ...
- Shiro自定义Realm时用注解的方式注入父类的credentialsMatcher
用Shiro做登录权限控制时,密码加密是自定义的. 数据库的密码通过散列获取,如下,算法为:md5,盐为一个随机数字,散列迭代次数为3次,最终将salt与散列后的密码保存到数据库内,第二次登录时将登录 ...
- TEST mathjax
这里是第一个公式 $ F = ma^2 $ \[ \text{Reinforcement Learning} \doteq \pi_* \\ \quad \updownarrow \\ \pi_* \ ...
- WPA2 Key Reinstallation 漏洞
漏洞形成: 必要条件1:WPA2 协议存在一个消息重放漏洞,导致多组相同数据被使用了相同的密钥加密. ciphertext = plaintext xor AES(key, IV||counter) ...
- 了解Git的工作区和暂存区
Git有工作区,暂存区之分. 1.工作区 我们电脑上的某个被Git管理的文件夹,就是一个工作区. 比如说我的GitWorkText文件夹,如图: 2.版本库(Repository) 在工作区有一个隐藏 ...
- paddle实践
Docker image阅读:https://github.com/PaddlePaddle/book/blob/develop/README.cn.md docker run -d -p 8888: ...
- c# 移动鼠标到指定位置
/// <summary> /// 引用user32.dll动态链接库(windows api), /// 使用库中定义 API:SetCursorPos /// </summary ...
- 获取Linux服务器基本信息的shell脚本
测试运行环境: SLES12SP2 #!/bin/bash #系统名称:os_type=$(uname -o | awk '{print " | "$0}') #系统位数:32/6 ...
- select标签(下拉菜单和列表)
下拉菜单和列表标签: <select> <option value="..." >选项</option> <option value=&q ...