MongoDB journal与oplog解惑
journal
journal 是 MongoDB 存储引擎层的概念,目前 MongoDB主要支持 mmapv1、wiredtiger、mongorocks 等存储引擎,都支持配置journal。
MongoDB 所有的数据写入、读取最终都是调存储引擎层的接口来存储、读取数据,journal 是存储引擎存储数据时的一种辅助机制。
默认情况下mongodb每100毫秒往journal文件中flush一次数据,不过这是在数据文件和journal文件处于同一磁盘卷上的情况,而如果数据文件和journal文件不在同一磁盘卷上时,默认刷新输出时间是30毫秒。不过这个毫秒值是可以修改的,可修改范围是2~300,值越低,刷新输出频率越高,数据安全度也就越高,但磁盘性能上的开销也更高。
以wiredtiger 为例,如果不配置 journal,写入 wiredtiger 的数据,并不会立即持久化存储;而是每分钟会做一次全量的checkpoint(storage.syncPeriodSecs配置项,默认为1分钟),将所有的数据持久化。如果中间出现宕机,那么数据只能恢复到最近的一次checkpoint,这样最多可能丢掉1分钟的数据。
所以建议「一定要开启journal」,开启 journal 后,每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。这样即使出现宕机,启动时 Wiredtiger 会先将数据恢复到最近的一次checkpoint的点,然后重放后续的 journal 操作日志来恢复数据。
journal文件是以“j._”开头命名的,且是append only的,如果1个journal文件满了1G大小,mongodb就会新创建一个journal文件来使用,一旦某个journal文件所记载的写操作都被使用过了,mongodb就会把这个journal文件删除。通常在journal文件所在的文件夹下,只会存在2~3个journal文件,除非你使用mongodb每秒都写入大量的数据。而使用 smallfiles 这个运行时选项可以将journal文件大小减至128M大小。
MongoDB 里的 journal 行为 主要由2个参数控制,storage.journal.enabled 决定是否开启journal,storage.journal.commitInternalMs 决定 journal 刷盘的间隔,默认为100ms,用户也可以通过写入时指定 writeConcern 为 {j: ture} 来每次写入时都确保 journal 刷盘。
oplog
oplog 是 MongoDB 主从复制层面的一个概念,通过 oplog 来实现复制集节点间数据同步,客户端将数据写入到 Primary,Primary 写入数据后会记录一条 oplog,Secondary 从 Primary(或其他 Secondary )拉取 oplog 并重放,来确保复制集里每个节点存储相同的数据。
oplog 在 MongoDB 里是一个普通的 capped collection,对于存储引擎来说,oplog只是一部分普通的数据而已。
MongoDB 的一次写入
MongoDB 复制集里写入一个文档时,需要修改如下数据
- 将文档数据写入对应的集合
- 更新集合的所有索引信息
- 写入一条oplog用于同步
上面3个修改操作,需要确保要么都成功,要么都失败,不能出现部分成功的情况,否则
- 如果数据写入成功,但索引写入失败,那么会出现某个数据,通过全表扫描能读取到,但通过索引就无法读取
- 如果数据、索引都写入成功,但 oplog 写入不成功,那么写入操作就不能正常的同步到备节点,出现主备数据不一致的情况
MongoDB 在写入数据时,会将上述3个操作放到一个 wiredtiger 的事务里,确保「原子性」。
beginTransaction();
writeDataToColleciton();
writeCollectionIndex();
writeOplog();
commitTransaction();
wiredtiger 提交事务时,会将所有修改操作应用,并将上述3个操作写入到一条 journal 操作日志里;后台会周期性的checkpoint,将修改持久化,并移除无用的journal。
从数据布局看,oplog 与 journal 的关系
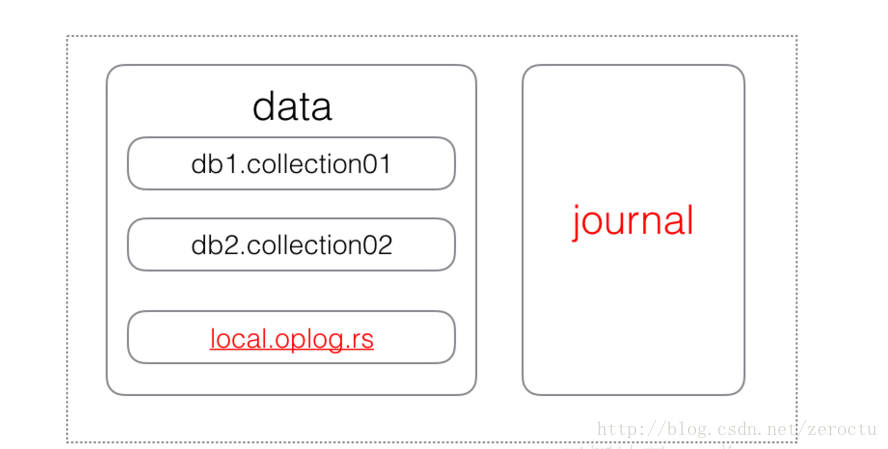
谁先写入??
- oplog 与 journal 是 MongoDB 里不同层次的概念,放在一起比先后本身是不合理的。
- oplog 在 MongoDB 里是一个普通的集合,所以 oplog 的写入与普通集合的写入并无区别。
- 一次写入,会对应数据、索引,oplog的修改,而这3个修改,会对应一条journal操作日志。
MongoDB journal与oplog解惑的更多相关文章
- MongoDB journal 与 oplog,究竟谁先写入?
MongoDB journal 与 oplog,谁先写入?最近经常被人问到,本文主要科普一下 MongoDB 里 oplog 以及 journal 这两个概念. journal journal 是 M ...
- MongoDB journal 与 oplog,究竟谁先写入?--转载
MongoDB journal 与 oplog,谁先写入?最近经常被人问到,本文主要科普一下 MongoDB 里 oplog 以及 journal 这两个概念. journal journal 是 M ...
- 转:MongoDB · 引擎特性 · journal 与 oplog,究竟谁先写入?
转:MongoDB · 引擎特性 · journal 与 oplog,究竟谁先写入? 数据库内核月报 链接:http://mysql.taobao.org/monthly/2018/05/07/ Mo ...
- 单台MongoDB实例开启Oplog
背景 随着数据的积累,MongoDB中的数据量越来越大,数据分析团队从数据库中抽取变化数据(假如依据栏位createdatetime,transdatetime),越来越困难.我们知道MongoDB的 ...
- mongodb:修改oplog.rs 的大小size
其内容字段说明: ts:操作日志的timestamp t: 未知? h:操作唯一随机值 v:oplog.rs的版本 op:操作类型: i:insert操作 u:update操作 d:delete操作 ...
- 云数据库MongoDB版清理oplog日志和compact命令详解
1.问题描述: 今天看到公司mongodb的oplog有点大,看到云数据库MongoDB版日志清理策略. MongoDB数据库在长期频繁地删除/写入数据或批量删除了大量数据,将产生很多物理空间碎片. ...
- MongoDB 如何保证 oplog 顺序?
MongoDB 复制集里,主备节点间通过 oplog 来同步数据,Priamry 上写入数据时,会记录一条oplog,Secondary 从 Primary 节点拉取 oplog并重放,以保证最终存储 ...
- mongodb的oplog遇到的问题
mongodb调整oplog的大小的方法 关闭当前服务器,将服务器以单机模式启动.这是一种方法,还有没有其他方法? mongodb实时扫描oplog,判断记录到哪个地方了 如果扫描oplog的程序挂掉 ...
- MongoDB副本集配置系列七:MongoDB oplog详解
1:oplog简介 oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的.每个节点都有oplog,记录这从主节点复制过来的信息,这样 ...
随机推荐
- springMVC拦截css与js等资源文件的解决
写了一个demo的ssm,使用jetty容器跑的,但是在页面的时候总是发现访问资源出现404. 换了多种写法不见效. 偶然发现日志中请求被springMVC拦截了,气死我了. 解决方式: Spring ...
- windows 访问局域网共享文件
直接在浏览器或资源管理器输入路径就OK file://10.16.73.129/FinTech/soft
- Java语法基础学习DayThree
一.流程控制语句补充 1.switch语句 格式: switch(表达式) { case 值1: 语句体1; break; case 值2: 语句体2; break; ... default: 语句体 ...
- shell脚本-实战防dos攻击
根据web日志或者或者网络连接数,监控当某个IP并发连接数或者短时内PV达到100,即调用防火墙命令封掉对应的IP,监控频率每隔3分钟.防火墙命令为:iptables -I INPUT -s 10.0 ...
- centos /data目录扩容
/data盘被日志撑死了,必须扩容 有一块现成的100G的/dev/sdb盘,但是mount到了/data/test目录下,而且还有应用程序在上面进行读写操作 1.先查看哪些应用程序 在占用磁盘 #f ...
- jq设置控件可用不可用
$("#tj").attr("disabled", true); //不可用 $("#tj").removeAttr("disab ...
- react-navigation实现页面框架(转载)
初始化一个RN项目 react-native init page_framework page.json { "name": "page_framework", ...
- 普通new和placement new的重载
对于自定义对象,我们可以重载普通new操作符,这时候使用new Test()时就会调用到我们重载的普通new操作符. 示例程序: #include <iostream> #include ...
- Samsung_tiny4412(驱动笔记06)----list_head,proc file system,GPIO,ioremap
/**************************************************************************** * * list_head,proc fil ...
- shell常用函数封装-main.sh
#!/bin/bash #sunlight sp monitor system #created on 2018/01/07#by chao.dong#used by sp servers consi ...