Python——爬虫学习1
爬虫了解一下
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
Python的安装
本篇教程采用Python3 来写,所以你需要给你的电脑装上Python3才行。注意选择正确的版本,一般下载并且安装完成,pip也一起安装好了。
链接:https://pan.baidu.com/s/1xxM09dmiXjTIiqABsIZxTQ 密码:mjqc
安装过程就不在赘言。
python插件的安装
爬虫用到的插件可以通过强大的pip下载(一个用于下载插件的程序),位置在C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\Scripts\pip.exe
用到的插件包括lxml,beautifulsoup4,requests
按住win+r,输入cmd,安装插件的语法为:pip install 插件名称
运行cmd
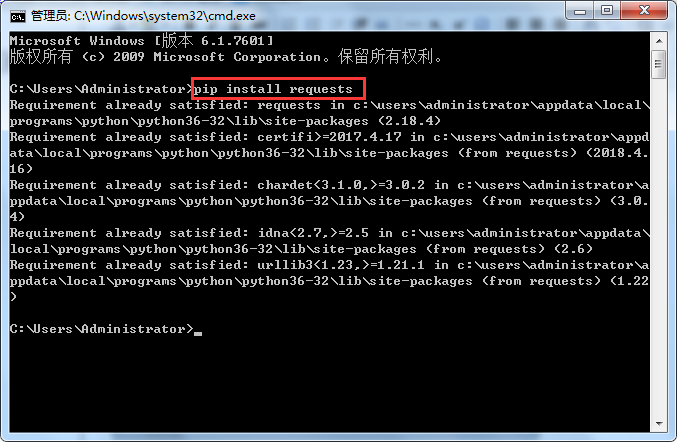
安装requests
输入pip install requests
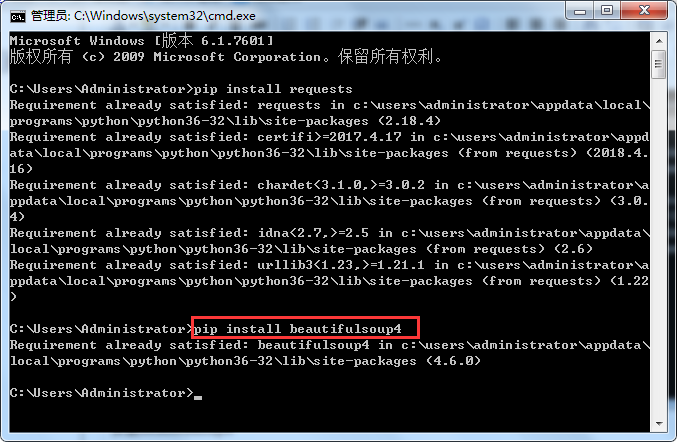
安装beautifulsoup4
输入pip install beautifulsoup4
安装lxml
输入pip install lxml

注意:pip安装的插件的位置在C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\Lib\site-packages
正式编程工作
新建一个.py文件,输入代码如下:
#!/usr/bin/env python3
#-*- coding:utf-8 -*- import requests #导入requests
from bs4 import BeautifulSoup #导入bs4中的BeautifulSoup
import os #导入os #浏览器的请求头(大部分网站没有这个请求头会报错,请务必加上)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1'}
all_url = 'http://www.mzitu.com/all' #开始的URL地址 ##使用requests中的get方法来获取all_url的内容 ,headers为上面设置的请求头,请参考requests的文档
start_html = requests.get(all_url, headers=headers)
##打印出start_html(请注意,打印网页内容请使用text,concent是二进制的数据,一般用于下载图片,视频,音频等多媒体内容时才使用)
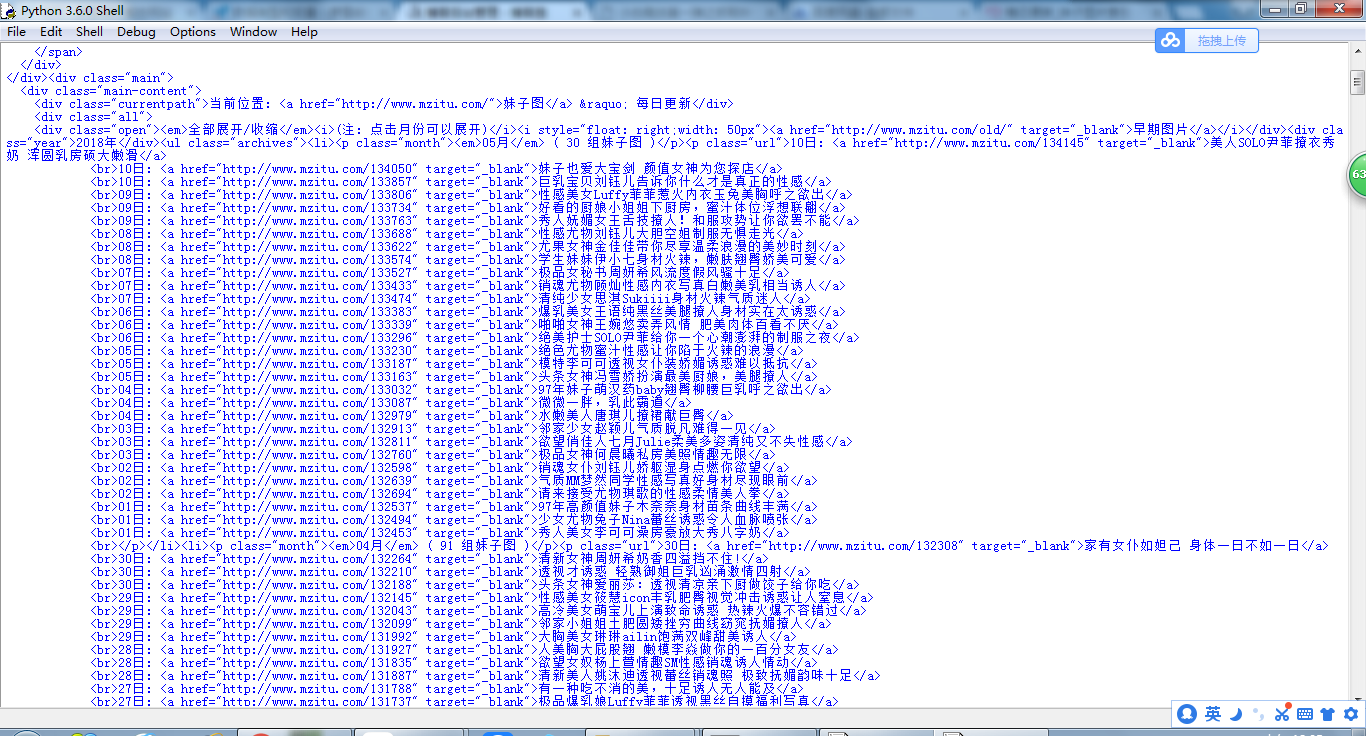
print(start_html.text)
运行一下就会得到网页的内容了,嘻嘻(*^__^*) 嘻嘻
Python——爬虫学习1的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- 基于SSH的客户关系管理系统CRM-JavaWeb项目-有源码
开发工具:Myeclipse/Eclipse + MySQL + Tomcat 项目简介: 项目的编译和运行:1 将数据库导入MysSql里 :打开HeidiSql这个图形化工具,新建一个数据库, 可 ...
- Java50道经典习题-程序17 猴子吃桃问题
题目:猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个 第二天早上又将剩下的桃子吃掉一半,又多吃了一个.以后每天早上都吃了前一天剩下的一半零一个.到第10天早上想再吃时,见只 ...
- Learning Rich Features from RGB-D Images for Object Detection and Segmentation论文笔记
相关工作: 将R-CNN推广到RGB-D图像,引入一种新的编码方式来捕获图像中像素的地心姿态,并且这种新的编码方式比单纯使用深度通道有了明显的改进. 我们建议在每个像素上用三个通道编码深度图像:水平视 ...
- 初探APT 攻击
作者:joe 所属团队:Arctic Shell 本文编写参考: https://www.freebuf.com/vuls/175280.html https://www.freebuf. ...
- iOS没你想的那么安全?
iOS应用由于直接运行在用户的手机上,而不是运行在后台服务器上,所以更容易被攻击. 任何系统都会有木马病毒的产生,不存在绝对的安全,iOS应用由于直接运行在用户的手机上,而不是运行在后台服务器上,所以 ...
- ElasticSearch基本查询
词条查询 这是一个简单查询.它仅 匹配给定字段中包含该词条的稳定,且是2未经分析的确切的词条. { “query” :{ “term”:{ “title”:”crime” } } } 多词条查询 匹配 ...
- [转] Foobar2000 DSP音效外挂元件-Part4
[转] Foobar2000 DSP音效外挂元件-Part4 在第1部分的文章里主要介绍了foobar2000预设的DSP音效调整,这些则示要介绍几个比较会用到的DSP外挂元件,在foobar2000 ...
- 根据现有PDF模板填充信息(SpringBoot)
根据现有PDF模板填充信息(SpringBoot+maven) 首先得有一个pdf模板,建立pdf模板需要下载工具 红色框为文本框,filename为域名.java需要根据域名赋值 pom 文件配置 ...
- 为阿里云域名配置免费SSL支持https加密访问简单教程
阿里云之前有免费ssl入口申请,现在已经关闭了.那么现在怎么为自己的域名配置https呢? 首先打开阿里云域名控制台,如以下界面.(这里暂且用我的这个域名讲解吧) 如上图点击ssl证书,点击单域名免 ...
- Python库大全
网络 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycurl). pycurl – 网络库(绑定libcurl). urllib3 – Pyth ...