Python——爬虫学习1
爬虫了解一下
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
Python的安装
本篇教程采用Python3 来写,所以你需要给你的电脑装上Python3才行。注意选择正确的版本,一般下载并且安装完成,pip也一起安装好了。
链接:https://pan.baidu.com/s/1xxM09dmiXjTIiqABsIZxTQ 密码:mjqc
安装过程就不在赘言。
python插件的安装
爬虫用到的插件可以通过强大的pip下载(一个用于下载插件的程序),位置在C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\Scripts\pip.exe
用到的插件包括lxml,beautifulsoup4,requests
按住win+r,输入cmd,安装插件的语法为:pip install 插件名称
运行cmd
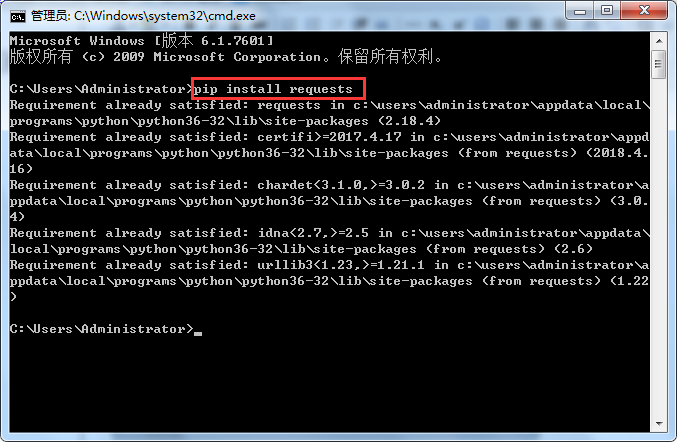
安装requests
输入pip install requests
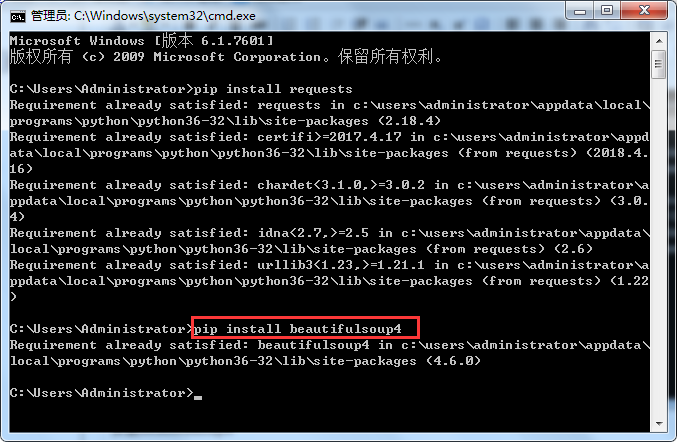
安装beautifulsoup4
输入pip install beautifulsoup4
安装lxml
输入pip install lxml

注意:pip安装的插件的位置在C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\Lib\site-packages
正式编程工作
新建一个.py文件,输入代码如下:
#!/usr/bin/env python3
#-*- coding:utf-8 -*- import requests #导入requests
from bs4 import BeautifulSoup #导入bs4中的BeautifulSoup
import os #导入os #浏览器的请求头(大部分网站没有这个请求头会报错,请务必加上)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1'}
all_url = 'http://www.mzitu.com/all' #开始的URL地址 ##使用requests中的get方法来获取all_url的内容 ,headers为上面设置的请求头,请参考requests的文档
start_html = requests.get(all_url, headers=headers)
##打印出start_html(请注意,打印网页内容请使用text,concent是二进制的数据,一般用于下载图片,视频,音频等多媒体内容时才使用)
print(start_html.text)
运行一下就会得到网页的内容了,嘻嘻(*^__^*) 嘻嘻
Python——爬虫学习1的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- sql performance Kill Lock
sp_who2 active sp_lock 76 select object_name(261575970,16) select %%lockres%%,* from SessionLock(nol ...
- JS 获取各个偶数之和!!
<html> <head> <meta charset="utf-8" /> <title>js& ...
- SpringMvc date数据传递处理
1.form表单提交date数据 form表单提交的date数据要在接收的字段上加入@DateTimeFormat注解 @DateTimeFormat(pattern = "yyyy-MM- ...
- [ActionScript 3.0] 模拟win7彩色气泡屏保效果
主文件: package { import com.views.BubbleView; import com.views.ColorfulBubble; import flash.display.Sp ...
- 【UI组件】——用jQuery做一个上拉刷新
技术要点: 1.jQuery的插件写法 2.上拉刷新步骤分解 3.css样式 jQuery的插件写法: $.fn.pluginName = function() { return this.each( ...
- python 之 爬普房网
from bs4 import BeautifulSoupimport reimport requestsimport pandas## pa pufangwangclass down(object) ...
- 回归到jquery
最近在做一个公司的老产品的新功能,使用原来的技术框架,jquery和一堆插件,使用jquery的话,灵活性是有了,但是对于一个工作了3年多的我来说,很low,没什么成就感,技术本身比较简单,但是业务的 ...
- STM32-RS232通信软硬件实现
OS:Windows 64 Development kit:MDK5.14 IDE:UV4 MCU:STM32F103C8T6/VET6 AD:Altium Designer 18.0.12 1.RS ...
- 第一站:CLion安装教程与环境配置
原文来自:http://www.sunmey.cn/thread-129-1-1.html 本人:找了很久才找到的CLion安装教程与环境配置,这里分享给大家~ 这里要说明的一点是CLion是要钱的, ...
- Kotlin Eclipse 环境搭建
Kotlin是JetBrains开发的基于JVM的语言.JetBrains是一家捷克的软件开发公司,该公司位于捷克的布拉格,研发了IntelliJ IDEA这款相对于Eclipse有较大改善的大名鼎鼎 ...