(转) 一致性Hash算法在Memcached中的应用
前言
大家应该都知道Memcached要想实现分布式只能在客户端来完成,目前比较流行的是通过一致性hash算法来实现.常规的方法是将 server的hash值与server的总台数进行求余,即hash%N,这种方法的弊端是当增减服务器时,将会有较多的缓存需要被重新分配且会造成缓 存分配不均匀的情况(有可能某一台服务器分配的很多,其它的却很少).
今天分享一种叫做”ketama”的一致性hash算法,它通过虚拟节点的概念和不同的缓存分配规则有效的抑制了缓存分布不均匀,并最大限度地减少服务器增减时缓存的重新分布。
实现思路
假设我们现在有N台Memcached的Server,如果我们用统一的规则对memcached进行Set,Get操作. 使具有不同key的object很均衡的分散存储在这些Server上,Get操作时也是按同样规则去对应的Server上取出object,这样各个 Server之间不就是一个整体了吗?
那到底是一个什么样的规则?
如下图所示,我们现在有5台(A,B,C,D,E)Memcached的Server,我们将其串联起来形成一个环形,每一台Server都代表圆环上的一个点,每一个点都具有唯一的Hash值,这个圆环上一共有2^32个点.
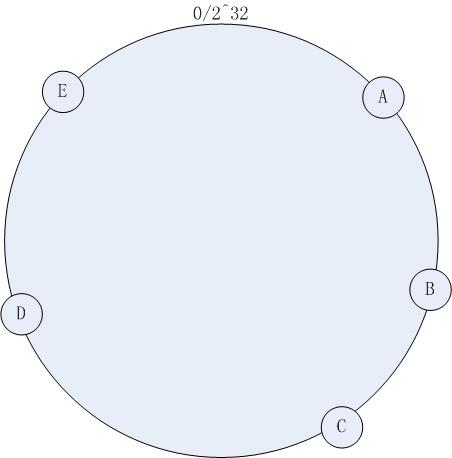
那么该如何确定每台Server具体分布在哪个点上? 这里我们通过”Ketama”的Hash算法来计算出每台Server的Hash值,拿到Hash值后就可以对应到圆环上点了.(可以用Server的IP地址作为Hash算法的Key.)
这样做的好处是,如下图当我新增Server F时,那么我只需要将hash值落在C和F之间的object从原本的D上重新分配到F上就可以了,其它的server上的缓存不需要重新分配,并且新增的Server也能及时帮忙缓冲其它Server的压力.

到此我们已经解决了增减服务器时大量缓存需要被重新分配的弊端.那该如何解决缓存分配不均匀的问题呢?因为现在我们的server只占据圆环上的6个点,而圆环上总共有2^32个点,这极其容易导致某一台server上热点非常多,某一台上热点很少的情况.
”虚拟节点”的概念很好的解决了这种负载不均衡的问题.通过将每台物理存在的Server分割成N个虚拟的Server节点(N通常根据物理 Server个数来定,这里有个比较好的阈值为250).这样每个物理Server实际上对应了N个虚拟的节点. 存储点多了,各个Server的负载自然要均衡一些.就像地铁站出口一样,出口越多,每个出口出现拥挤的情况就会越少.
代码实现:
//保存所有虚拟节点信息, key : 虚拟节点的hash key, value: 虚拟节点对应的真实server
private Dictionary<uint, string> hostDictionary = new Dictionary<uint, string>();
//保存所有虚拟节点的hash key, 已按升序排序
private uint[] ketamaHashKeys = new uint[] { };
//保存真实server主机地址
private string[] realHostArr = new string[] { };
//每台真实server对应虚拟节点个数
private int VirtualNodeNum = ; public KetamaVirtualNodeInit(string[] hostArr)
{
this.realHostArr = hostArr;
this.InitVirtualNodes();
} /// <summary>
/// 初始化虚拟节点
/// </summary>
private void InitVirtualNodes()
{
hostDictionary = new Dictionary<uint, string>();
List<uint> hostKeys = new List<uint>();
if (realHostArr == null || realHostArr.Length == )
{
throw new Exception("不能传入空的Server集合");
} for (int i = ; i < realHostArr.Length; i++)
{
for (int j = ; j < VirtualNodeNum; j++)
{
byte[] nameBytes = Encoding.UTF8.GetBytes(string.Format("{0}-node{1}", realHostArr[i], j));
//调用Ketama hash算法获取hash key
uint hashKey = BitConverter.ToUInt32(new KetamaHash().ComputeHash(nameBytes), );
hostKeys.Add(hashKey);
if (hostDictionary.ContainsKey(hashKey))
{
throw new Exception("创建虚拟节点时发现相同hash key,请检查是否传入了相同Server");
}
hostDictionary.Add(hashKey, realHostArr[i]);
}
} hostKeys.Sort();
ketamaHashKeys = hostKeys.ToArray();
}
一致性hash算法的分配规则
到此我们已经知道了所有虚拟节点的Hash值, 现在让我们来看下当我们拿到一个对象时如何存入Server, 或是拿到一个对象的Key时该如何取出对象.
Set一个对象时,先将对象的Key作为”Ketama”算法的Key,计算出Hash值后我们需要做下面几个步骤.
1:首先检查虚拟节点当中是否有与当前对象Hash值相等的,如有则直接将对象存入那个Hash值相等的节点,后面的步骤就不继续了.
2:如没有,则找出第一个比当前对象Hash值要大的节点,(节点的Hash值按升序进行排序,圆环上对应按照顺时针来排列),即离对象最近的节点,然后将对象存入该节点.
3:如果没有找到Hash值比对象要大的Server,证明对象的Hash值是介于最后一个节点和第一个节点之间的,也就是圆环上的E和A之间.这种情况就直接将对象存入第一个节点,即A.
代码实现:
/// <summary>
/// 根据hash key 获取对应的真实Server
/// </summary>
/// <param name="hash"></param>
/// <returns></returns>
public string GetHostByHashKey(string key)
{
byte[] bytes = Encoding.UTF8.GetBytes(key);
uint hash = BitConverter.ToUInt32(new KetamaHash().ComputeHash(bytes), ); //寻找与当前hash值相等的Server.
int i = Array.BinarySearch(ketamaHashKeys, hash); //如果i小于零则表示没有hash值相等的虚拟节点
if (i < )
{
//将i继续按位求补,得到数组中第一个大于当前hash值的虚拟节点
i = ~i; //如果按位求补后的i大于等于数组的大小,则表示数组中没有大于当前hash值的虚拟节点
//此时直接取第一个server
if (i >= ketamaHashKeys.Length)
{
i = ;
}
} //根据虚拟节点的hash key 返回对应的真实server host地址
return hostDictionary[ketamaHashKeys[i]];
}
Get一个对象,同样也是通过”Ketama”算法计算出Hash值,然后与Set过程一样寻找节点,找到之后直接取出对象即可.
那么这个”Ketama”到底长什么样呢,让我们来看看代码实现.
/// <summary>
/// Ketama hash加密算法
/// 关于HashAlgorithm参见MSDN链接
/// http://msdn.microsoft.com/zh-cn/library/system.security.cryptography.hashalgorithm%28v=vs.110%29.aspx
/// </summary>
public class KetamaHash : HashAlgorithm
{ private static readonly uint FNV_prime = ;
private static readonly uint offset_basis = ; protected uint hash; public KetamaHash()
{
HashSizeValue = ;
} public override void Initialize()
{
hash = offset_basis;
} protected override void HashCore(byte[] array, int ibStart, int cbSize)
{
int length = ibStart + cbSize;
for (int i = ibStart; i < length; i++)
{
hash = (hash * FNV_prime) ^ array[i];
}
} protected override byte[] HashFinal()
{
hash += hash << ;
hash ^= hash >> ;
hash += hash << ;
hash ^= hash >> ;
hash += hash << ;
return BitConverter.GetBytes(hash);
}
}
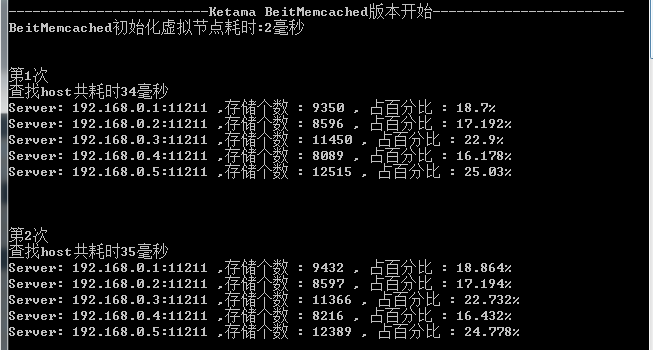
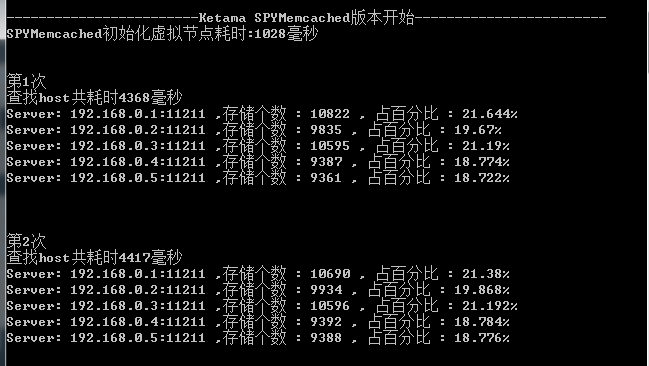
测试性能
最后我把自己参考BeitMemcached写的算法与老代(Discuz!代震军)参考SPYMemcached写的做了一下对比.
源码在后面有下载.
结果:查找5W个key的时间比老代的版本快了100多倍,但在负载均衡方面差了一些.
测试数据:
1:真实Server都是5台
2:随机生成5W个字符串key(生成方法直接拿老代的)
3:虚拟节点都是250个
我的版本:
老代的版本:
参考资料
老代: 一致性Hash算法(KetamaHash)的c#实现
(转) 一致性Hash算法在Memcached中的应用的更多相关文章
- 一致性Hash算法在Memcached中的应用
前言 大家应该都知道Memcached要想实现分布式只能在客户端来完成,目前比较流行的是通过一致性hash算法来实现.常规的方法是将server的hash值与server的总台数进行求余,即hash% ...
- 一致性hash算法在memcached中的使用
一.概述 1.我们的memcacheclient(这里我看的spymemcache的源代码).使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同.仅仅是对我们要存 ...
- 【转载】一致性hash算法释义
http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Karge ...
- 一致性Hash算法及使用场景
一.问题产生背景 在使用分布式对数据进行存储时,经常会碰到需要新增节点来满足业务快速增长的需求.然而在新增节点时,如果处理不善会导致所有的数据重新分片,这对于某些系统来说可能是灾难性的. 那 ...
- [转载] 一致性hash算法释义
转载自http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Ka ...
- 关于一致性Hash算法
在大型web应用中,缓存可算是当今的一个标准开发配置了.在大规模的缓存应用中,应运而生了分布式缓存系统.分布式缓存系统的基本原理,大家也有所耳闻.key-value如何均匀的分散到集群中?说到此,最常 ...
- 理解一致性Hash算法
简介 一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CAR ...
- OpenStack_Swift源代码分析——Ring基本原理及一致性Hash算法
1.Ring的基本概念 Ring是swfit中最重要的组件.用于记录存储对象与物理位置之间的映射关系,当用户须要对Account.Container.Object操作时,就须要查询相应的Ring文件( ...
- 一致性hash算法及java实现
一致性hash算法是分布式中一个常用且好用的分片算法.或者数据库分库分表算法.现在的互联网服务架构中,为避免单点故障.提升处理效率.横向扩展等原因,分布式系统已经成为了居家旅行必备的部署模式,所以也产 ...
随机推荐
- thinkphp5使用PHPMailler发送邮件
http://www.dawnfly.cn/article-1-350.html 想要了解thinkphp3.2版本发送邮件的,请点击此链接:http://www.dawnfly.cn/article ...
- 如何确定Hadoop中map和reduce的个数--map和reduce数量之间的关系是什么?
一般情况下,在输入源是文件的时候,一个task的map数量由splitSize来决定的,那么splitSize是由以下几个来决定的 goalSize = totalSize / mapred.map. ...
- hadoop中map和reduce的数量设置
hadoop中map和reduce的数量设置,有以下几种方式来设置 一.mapred-default.xml 这个文件包含主要的你的站点定制的Hadoop.尽管文件名以mapred开头,通过它可以控制 ...
- ReactNative生成android平台的bundle文件命令
ReactNative生成android平台的bundle文件命令 2016年11月03日 23:23:28 阅读数:4869 注:如果assets文件没有正确生成,需要手机创建或授权 网上的其它的很 ...
- com.sun.image.codec.jpeg在Eclipse中报错的解决办法
在Eclipse中处理图片,需要引入两个包:import com.sun.image.codec.jpeg.JPEGCodec;import com.sun.image.codec.jpeg.JPEG ...
- MySQL中特有的函数If函数
上面我们已经知道了case函数可以实现逻辑判断,可以是很复杂的逻辑判断,但是如果我们只想实现的是如果这个条件成立就返回A否则就返回B这样简单的逻辑如果用case的话,未免复杂了.我们可以使用if函数来 ...
- 利用ssh-copy-id复制公钥到多台服务器
http://www.cnblogs.com/panchong/p/6027138.html?utm_source=itdadao&utm_medium=referral # 连接新主机时,不 ...
- centOS下升级python版本,详细步骤
1.可利用linux自带下载工具wget下载,如下所示:( 笔者安装的是最小centos系统,所以使用编译命令前,必须安装wget服务,读者如果安装的是界面centos系统,或者使用过编译工具则可跳 ...
- Mac OS 终端下使用 Curl 命令下载文件
在 mac os下,如何通过命令行来下载网络文件?如果你没有安装或 wget 命令,那么可以使用 curl 工具来达到我们的目的. curl命令参数: curl 'url地址' curl [选项] ' ...
- ubuntu14.04 安装mono
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 3FA7E0328081BFF6A14DA29AA6A19B38D3D831 ...