spark读取mongodb数据写入hive表中
一 环境:
spark-2.2.; hive-1.1.; scala-2.11.; hadoop-2.6.-cdh-5.15.; jdk-1.8; mongodb-2.4.10;
二.数据情况:
MongoDB数据格式
{
"_id" : ObjectId("5ba0569cafc9ec432bd310a3"),
"id" : 7,
"name" : "7mongoDBi am using mongodb now",
"location" : "shanghai",
"sex" : "male",
"position" : "big data platform engineer"
}
Hive普通表 create table mgtohive_2(
id string,
name string,
age string,
deptno string
)row format delimited fields terminated by '\t'; create table mgtohive_2(
id int,
name string,
location string,
sex string,
position string
)
row format delimited fields terminated by '\t';
Hive分区表 create table mg_hive_external(
id int,
name string,
location string,
position string
)
PARTITIONED BY(sex string)
row format delimited fields terminated by '\t';
三.Eclipse+Maven+Java
3.1 依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.</artifactId>
<version>2.2.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.</artifactId>
<version>2.2.</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.6.</version>
</dependency>
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.</artifactId>
<version>2.2.</version>
</dependency>
3.2 代码:
package com.mobanker.mongo2hive.Mongo2Hive; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.hive.HiveContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import org.bson.Document; import com.mongodb.spark.MongoSpark; import java.io.File;
import java.util.ArrayList;
import java.util.List; public class Mongo2Hive {
public static void main(String[] args) {
//spark 2.x
String warehouseLocation = new File("spark-warehouse").getAbsolutePath();
SparkSession spark = SparkSession.builder()
.master("local[2]")
.appName("SparkReadMgToHive")
.config("spark.sql.warehouse.dir", warehouseLocation)
.config("spark.mongodb.input.uri", "mongodb://10.40.20.47:27017/test_db.test_table")
.enableHiveSupport()
.getOrCreate();
JavaSparkContext sc = new JavaSparkContext(spark.sparkContext()); // spark 1.x
// JavaSparkContext sc = new JavaSparkContext(conf);
// sc.addJar("/Users/mac/zhangchun/jar/mongo-spark-connector_2.11-2.2.2.jar");
// sc.addJar("/Users/mac/zhangchun/jar/mongo-java-driver-3.6.3.jar");
// SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkReadMgToHive");
// conf.set("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/test.mgtest");
// conf.set("spark. serializer","org.apache.spark.serializer.KryoSerialzier");
// HiveContext sqlContext = new HiveContext(sc);
// //create df from mongo
// Dataset<Row> df = MongoSpark.read(sqlContext).load().toDF();
// df.select("id","name","name").show(); String querysql= "select id,name,location,sex,position from mgtohive_2 b";
String opType ="P"; SQLUtils sqlUtils = new SQLUtils();
List<String> column = sqlUtils.getColumns(querysql); //create rdd from mongo
JavaRDD<Document> rdd = MongoSpark.load(sc);
//将Document转成Object
JavaRDD<Object> Ordd = rdd.map(new Function<Document, Object>() {
public Object call(Document document){
List list = new ArrayList();
for (int i = ; i < column.size(); i++) {
list.add(String.valueOf(document.get(column.get(i))));
}
return list; // return list.toString().replace("[","").replace("]","");
}
});
System.out.println(Ordd.first());
//通过编程方式将RDD转成DF
List ls= new ArrayList();
for (int i = ; i < column.size(); i++) {
ls.add(column.get(i));
}
String schemaString = ls.toString().replace("[","").replace("]","").replace(" ","");
System.out.println(schemaString); List<StructField> fields = new ArrayList<StructField>();
for (String fieldName : schemaString.split(",")) {
StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);
fields.add(field);
}
StructType schema = DataTypes.createStructType(fields); JavaRDD<Row> rowRDD = Ordd.map((Function<Object, Row>) record -> {
List fileds = (List) record;
// String[] attributes = record.toString().split(",");
return RowFactory.create(fileds.toArray());
}); Dataset<Row> df = spark.createDataFrame(rowRDD,schema); //将DF写入到Hive中
//选择Hive数据库
spark.sql("use datalake");
//注册临时表
df.registerTempTable("mgtable"); if ("O".equals(opType.trim())) {
System.out.println("数据插入到Hive ordinary table");
Long t1 = System.currentTimeMillis();
spark.sql("insert into mgtohive_2 " + querysql + " " + "where b.id not in (select id from mgtohive_2)"); System.out.println("insert into mgtohive_2 " + querysql + " "); Long t2 = System.currentTimeMillis();
System.out.println("共耗时:" + (t2 - t1) / + "分钟");
}else if ("P".equals(opType.trim())) { System.out.println("数据插入到Hive dynamic partition table");
Long t3 = System.currentTimeMillis();
//必须设置以下参数 否则报错
spark.sql("set hive.exec.dynamic.partition.mode=nonstrict");
//sex为分区字段 select语句最后一个字段必须是sex
spark.sql("insert into mg_hive_external partition(sex) select id,name,location,position,sex from mgtable b where b.id not in (select id from mg_hive_external)");
Long t4 = System.currentTimeMillis();
System.out.println("共耗时:"+(t4 -t3)/+ "分钟");
}
spark.stop();
}
}
工具类:
package com.mobanker.mongo2hive.Mongo2Hive; import java.util.ArrayList;
import java.util.List; public class SQLUtils {
public List<String> getColumns(String querysql){
List<String> column = new ArrayList<String>();
String tmp = querysql.substring(querysql.indexOf("select") + ,
querysql.indexOf("from")).trim();
if (tmp.indexOf("*") == -){
String cols[] = tmp.split(",");
for (String c:cols){
column.add(c);
}
}
return column;
} public String getTBname(String querysql){
String tmp = querysql.substring(querysql.indexOf("from")+).trim();
int sx = tmp.indexOf(" ");
if(sx == -){
return tmp;
}else {
return tmp.substring(,sx);
}
}
}
四 错误解决办法:
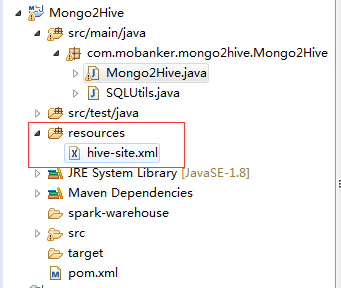
下载cdh集群Hive的hive-site.xml文件,在项目中新建resources文件夹,讲hive-site.xml配置文件放入其中:
五 执行情况:
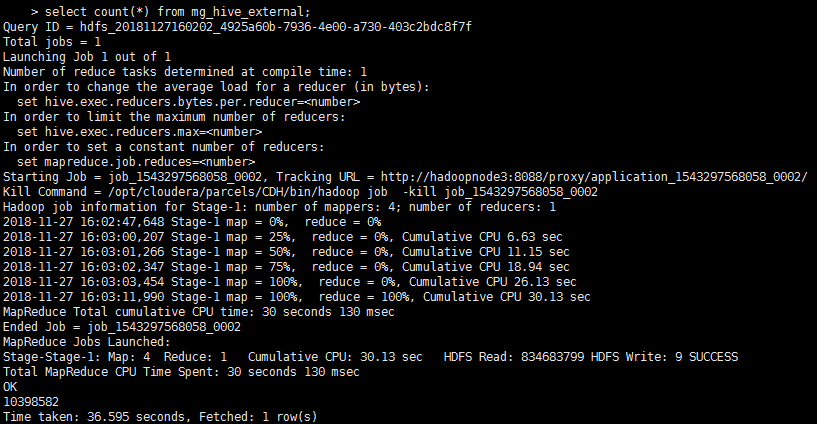
耗时14mins,写入hive表10398582条数据:
spark读取mongodb数据写入hive表中的更多相关文章
- spark 将dataframe数据写入Hive分区表
从spark1.2 到spark1.3,spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API.Da ...
- 通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来的Json数据写入数据库表中
摘自:http://blog.csdn.net/mazhaojuan/article/details/8592015 通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来 ...
- 《项目经验》--通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来的Json数据写入数据库表中
先看一下我要实现的功能界面: 这个界面的功能在图中已有展现,课程分配(教师教授哪门课程)在之前的页面中已做好.这个页面主要实现的是授课,即给老师教授的课程分配学生.此页面实现功能的步骤已在页面 ...
- sqoop导入数据到hive表中的相关操作
1.使用sqoop创建表并且指定对应的hive表中的字段的数据类型,同时指定该表的分区字段名称 sqoop create-hive-table --connect "jdbc:oracle: ...
- 将python的字典格式数据写入excei表中
上面的为最终结果 import requests import re import xlwt import json # 导入必须的包: xlwt,json,requests,re. headers ...
- 读取Excel数据到Table表中
方法一: try { List<DBUtility.CommandInfo> list = new List<DBUtility.CommandInfo>(); string ...
- 批量导入数据到hive表中:假设我有60张主子表如何批量创建导入数据
背景:根据业务需要需要把60张主子表批量入库到hive表. 创建测试数据: def createBatchTestFile(): Unit = { to ) { val sWriter = new P ...
- Hive 将本地数据导入hive表中
# 导入 load data local inpath '/root/mr/The_Man_of_Property.txt' insert into table article; # 提示 FAILE ...
- 将DataFrame数据如何写入到Hive表中
1.将DataFrame数据如何写入到Hive表中?2.通过那个API实现创建spark临时表?3.如何将DataFrame数据写入hive指定数据表的分区中? 从spark1.2 到spark1.3 ...
随机推荐
- java @XmlTransient与@Transient区别
1.@XmlTransient a.@XmlTransient 注解解决 JavaBean 属性名称与字段名称之间的名称冲突,或者用于防止字段/属性的映射 b.阻止将 JavaBean 属性映射到 X ...
- Kali-linux使用Nessus
Nessus号称是世界上最流行的漏洞扫描程序,全世界有超过75000个组织在使用它.该工具提供完整的电脑漏洞扫描服务,并随时更新其漏洞数据库.Nessus不同于传统的漏洞扫描软件,Nessus可同时在 ...
- virtualbox+vagrant学习-5-Boxes-1-简介
Boxes boxes是vagrant环境的包格式.在vagrant支持的任何平台上,任何人都可以使用一个box来创建一个相同的工作环境.vagrant box实用程序提供了管理boxes的所有功能. ...
- 结合cocos2d-x开发配置sublime text
开发cocos2d-x前端的非核心开发人员对于编辑器的选择,多数的选择有两个,一个是传统的ultraedit,另外的就是现在很流行的sublime text.以前我是比较喜欢用ultraedit的,但 ...
- HDFS的Write过程
hadoop中重要的组成部分HDFS,它所发挥的重要作用是进行文件的后端存储.HDFS针对的是低端的服务器,场景为读操作多.写操作少的情况.在分布式存储情况下,比较容易出现的情况是数据的损害,为了保证 ...
- 聊聊编程开发的数据库批量插入(sql)
这里的批量插入,主要是支持SQL的大型存储数据库,本文以Mysql,Oracle,SqlServer,postgresql4类来说明,这大概是国内应用比较多的了.其余的应该可以按照这些去找.提到编程的 ...
- CentOS7 更换OpenStack-queens源
根据官网的安装文档来对OpenStack搭建时碰到一个问题,安装完centos-release-openstack-queens后相当于是增加了一个OpenStack的源,但是因为这个源是在国外安装一 ...
- Ubuntu下配置MySql
安装mysql sudo apt-get install mysql-server 检查安装是否成功 sudo netstat -tap | grep mysql 登录mysql mysql -uro ...
- Web前端表单验证
表单选择器 :input(匹配所有input.textarea.select和button元素) :text(匹配所有单行文本框) :password(匹配所有密码框) :radio(匹配 ...
- jQuery 效果 - toggle() 方法切换元素的可见状态。
定义和用法 toggle() 方法切换元素的可见状态. 如果被选元素可见,则隐藏这些元素,如果被选元素隐藏,则显示这些元素. 语法 $(selector).toggle(speed,callback, ...