Python WebDriver + Firefox 文件下载

firefox可以通过 在地址栏输入:about:config 或about:aupport 来查看或修改配置信息。
这里有两种解决方式,
1、设置自动保存下载
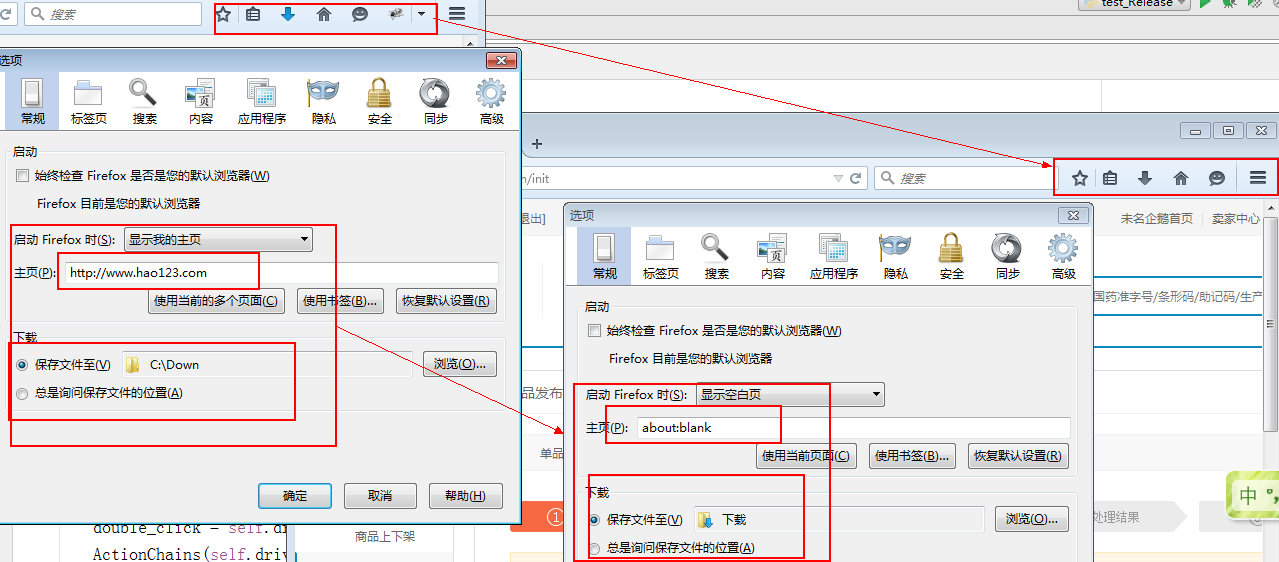
如下图勾选:以后自动采用相同的动作处理此类文件
这样下次在下载该类型的文件时就不会这样提醒了。

如果想修改设置可以在 浏览器选项中进行修改
如下图

这样设置完成后,但是程序启动时打开的浏览器并没有按照这种配置打开。
对比下图可以发现,通过webdriver打开的浏览器与手工打开的浏览器展示的不同,这是因为webdriver打开的浏览器没有按照浏览器设置的配置文件打开。如果想按照配置文件打开,在打开之前要先获取配置文件信息。
加入代码如下:
profile = webdriver.FirefoxProfile(r"C:\Users\Skyyj\AppData\Roaming\Mozilla\Firefox\Profiles\1rzh6139.default")
self.driver = webdriver.Firefox(profile)

2、第二种方法
就是在代码中加入配置信息
通过about:config
通过%APPDATA%\Mozilla\Firefox\Profiles\找到默认配置
找到mimeTypes.rdf目录,用其它方式打开,查找你刚刚保存的文件类型
mimeTypes.rdf 就存在上面 profile 的配置路径中
C:\Users\Skyyj\AppData\Roaming\Mozilla\Firefox\Profiles\1rzh6139.default 查找fileExtensions="xlsx"
NC:value="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"
NC:editable="true"
NC:fileExtensions="xlsx"
NC:description="xlsx File">

从文件中就可以得知我们需要的文件类型是什么
代码如下:
#profile = webdriver.FirefoxProfile(r"C:\Users\Skyyj\AppData\Roaming\Mozilla\Firefox\Profiles\1rzh6139.default")
profile = webdriver.FirefoxProfile() ##设置成0代表下载到浏览器默认下载路径;设置成2则可以保存到指定目录
profile.set_preference("browser.download.folderList", 2)
#这里设置与否不影响,没有发现有什么影响。
#profile.set_preference("browser.download.manager.showWhenStarting", False)
profile.set_preference("browser.download.dir", r"c:\Down")
profile.set_preference("browser.helperApps.neverAsk.saveToDisk", "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet")
#这里设置与否没有发现有什么影响
#profile.set_preference("browser.helperApps.alwaysAsk.force", False);
self.driver = webdriver.Firefox(profile)
建议使用第二种,这样不需要设置浏览器,可移植性好。
Python WebDriver + Firefox 文件下载的更多相关文章
- python webdriver firefox 登录126邮箱,先添加联系人,然后进入首页发送邮件,带附件。
代码:#encoding=utf-8from selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom ...
- python+selenium webdriver.firefox()方式配置浏览器设置
webdriver.firefox() 爬虫需求: (其实是输入参数可获取.zip/pdf 文件,然后点击下载) ——但是firefox浏览器有Bug,点击下载之后会有弹出窗口,需要你点击确定,这怎 ...
- 转:python webdriver API 之下载文件
webdriver 允许我们设置默认的文件下载路径.也就是说文件会自动下载并且存在设置的那个目录中.要想下载文件,首选要先确定你所要下载的文件的类型.要识别自动文件的下载类型可以使用 curl ,如图 ...
- Python WebDriver自动化测试
转载来自: http://www.cnblogs.com/fnng/p/3160606.html Webdriver Selenium 是 ThroughtWorks 一个强大的基于浏览器的开源自动化 ...
- 转:python webdriver API 之调用 JavaScript
当 webdriver 遇到没法完成的操作时,笔者可以考虑借用 JavaScript 来完成,比下下面的例子,通过 JavaScript 来隐藏页面上的元素.除了完成 webdriver 无法完成的操 ...
- 转:python webdriver API 之定位一组对象
webdriver 可以很方便的使用 find_element 方法来定位某个特定的对象,不过有时候我们却需要定位一组对象,WebElement 接口同样提供了定位一组元素的方法 find_eleme ...
- 转:python webdriver API 之设置等待时间
有时候为了保证脚本运行的稳定性,需要脚本中添加等待时间.sleep(): 设置固定休眠时间. python 的 time 包提供了休眠方法 sleep() , 导入 time 包后就可以使用 slee ...
- 转:python webdriver API 之操作测试对象
一般来说,所有有趣的操作与页面交互都将通过 WebElement 接口,包括上一节中介绍的对象定位,以及本节中需要介绍的常对象操作.webdriver 中比较常用的操作元素的方法有下面几个: cle ...
- 转:python webdriver API 之简单对象的定位
对象(元素)的定位和操作是自动化测试的核心部分,其中操作又是建立在定位的基础上的,因此元素定位就显得非常重要. (本书中用到的对象与元素同为一个事物)一个对象就像是一个人,他会有各种的特征(属性) , ...
随机推荐
- 【转】Java常量池详解
今天My partner问我一个让他头疼的Java question,求输出结果: /** * * @author DreamSea 2011-11-19 */ public class Intege ...
- 自己写了一个图片的马赛克消失效果(jQuery)
其中的一个效果: html代码: <h1>单击图片,产生效果</h1> <div class="box"></div> 插件代码: ...
- PyQt5系列教程(二)利用QtDesigner设计UI界面
软硬件环境 OS X EI Capitan Python 3.5.1 PyQt 5.5.1 PyCharm 5.0.1 前言 在PyQt5系列教程的第一篇http://blog.csdn.net/dj ...
- Wasserstein距离 和 Lipschitz连续
EMD(earth mover distance)距离: 在计算机科学与技术中,地球移动距离(EMD)是一种在D区域两个概率分布距离的度量,就是被熟知的Wasserstein度量标准.不正式的说,如果 ...
- 在VS2005编程中,有的时候DataGridView数据源有几个表的联合查询,而系统又有限制为一个表,怎么办?
在VS2005编程中,有的时候DataGridView数据源有几个表的联合查询,而系统又有限制为一个表,怎么办? 解决方法:在SqlServer的企业管理器里增加一个视图吧!!!!!!!!(从来没用过 ...
- 删除.svn 文件
新建一个delete_svn.bat文件 @echo on color 2f mode con: cols= lines= @REM @echo 正在清理SVN文件,请稍候...... @rem 循环 ...
- 使用openal与mpg123播放MP3,附带工程文件(转)
使用openal与mpg123播放MP3,附带工程文件 使用openal和mpg123播放MP3文件 使用静态编译,相关文件都在附件里 相关工程文件:openal_mpg123_player.7z 使 ...
- 3 MySQL数据库--初识sql语句
1.初识sql语句 服务端软件 mysqld SQL语句:后面的分号mysql -uroot -p123 操作文件夹(库) 增 create database db1 charset utf8; 查 ...
- 使用 Zend_Studio 开发
之前一直用vim 写PHP, 总觉得IDE的一大堆没有用的插件非常麻烦,所以一直避免使用Zend_Studio.不过随着PHP的发展和框架的发展,以及个人的发展,最后还是回到的IDE的时代. 在使用Z ...
- centos 使用windows7 存储
1. 在Windows7上创建一个带密码的用户,如disk 2. 创建一个文件夹,如 D:\centos-disk2 3. 选中此文件夹,点击上方的 共享 -> 特定用户, 添加disk用户, ...