HDFS中的读写数据流
1.文件的读取
在客户端执行读取操作时,客户端和HDFS交互过程以及NameNode和各DataNode之间的数据流是怎样的?下面将围绕图1进行具体讲解。
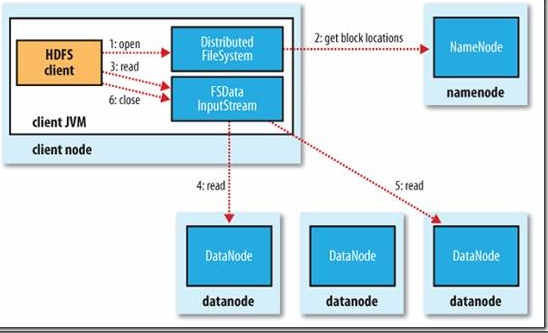
图 1 客户端从HDFS中读取数据
1)客户端通过调用FileSystem对象中的open()函数来读取它做需要的数据。FileSystem是HDFS中DistributedFileSystem的一个实例。
2)DistributedFileSystem会通过RPC协议调用NameNode来确定请求文件块所在的位置。
这里需要注意的是,NameNode只会返回所调用文件中开始的几个块而不是全部返回。对于每个返回的块,都包含块所在的DataNode地址。随后,这些返回的DataNode会按照Hadoop定义的集群拓扑结构得出客户端的距离,然后再进行排序。如果客户端本身就是一个DataNode,那么它就从本地读取文件。其次,DistributedFileSystem会向客户端返回一个支持文件定位的输入流对象FSDataInputStream,用于给客户端读取数据。FSDataInputStream包含一个DFSInputStream对象,这个对象用来管理DataNode和NameNode之间的IO。
3)当以上步骤完成时,客户端便会在这个输入流上调用read()函数。
4)DFSInputStream对象中包含文件开始部分数据块所在的DataNode地址,首先它会连接文件第一个块最近的DataNode。随后,在数据流中重复调用read()函数,直到这个块完全读完为止。
5)当第一个块读取完毕时,DFSInputStream会关闭连接,并查找存储下一个数据库距离客户端最近的DataNode。以上这些步骤对于客户端来说都是透明的。
6)客户端按照DFSInputStream打开和DataNode连接返回的数据流的顺序读取该块,它也会调用NameNode来检索下一组块所在的DataNode的位置信息。当完成所有文件的读取时,客户端则会在DFSInputStream中调用close()函数。
那么如果客户端正在读取数据时节点出现故障HDFS会怎么办呢?目前HDFS是这样处理的:如果客户端和所连接的DataNode在读取时出现故障,那么它就会去尝试连接存储这个块的下一个最近的DataNode,同时它会记录这个节点的故障,以免后面再次连接该节点。客户端还会验证从DataNode传送过来的数据校验和。如果发现一个损坏块,那么客户端将再尝试从别的DataNode读取数据块,向NameNode报告这个信息,NameNode也会更新保存的文件信息。
这里关注的一个设计要点是,客户端通过NameNode引导获取最合适的DataNode地址,然后直接连接DataNode读取数据。这样设计的好处在于,可以使HDFS扩展到更大规模的客户端并行处理,这是因为数据的流动是在所有DataNode之间分散进行的;同时NameNode的压力也变小了,使得NameNode只用提供请求块所在的位置信息就可以了,而不用通过它提供数据,这样就避免了NameNode随着客户端数量的增长而成为系统瓶颈。
2.文件的写入
那HDFS中文件的写入过程又是怎样的呢?以下将围绕图2来进行介绍。
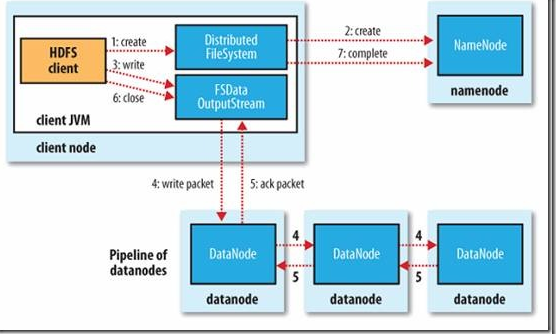
图2 客户端在HDFS中写入数据
1)客户端通过调用DistributedFileSystem对象中的create()函数创建一个文件。DistributedFileSystem通过RPC调用在NameNode的文件系统命名空间中创建一个新文件,此时还没有相关的DataNode与之相关。
2)NameNode会通过多种验证保证新的文件不存在文件系统中,并且确保请求客户端拥有创建文件的权限。当所有验证通过时,NameNode会创建一个新文件的记录,如果创建失败,则抛出一个IOException异常;如果成功,则DistributedFileSystem返回一个FSDataOutputStream给客户端用来写入数据。这里FSDataOutputStream和读取数据时的FSDataOutputStream一样都包含一个数据流对象DFSOutputStream,客户端将使用它来处理和DataNode及NameNode之间的通信。
3),4)当客户端写入数据时,DFSOutputStream会将文件分割成包,然后放入一个内部队列,我们称为“数据队列”。DataStreamer会将这些小的文件包放入数据流中,DataStreamer的作用是请求NameNode为新的文件包分配合适的DataNode存放副本。返回的DataNode列表形成一个“管道”,假设这里的副本数是3,那么这个管道中就会有3个DataNode。DataStreamer将文件包以流的方式传送给队列中的第一个DataNode。第一个DataNode会存储这个包,然后将它推送到第二个DataNode中,随后照这样进行,直到管道中的最后一个DataNode。
5)DFSOutputStream同时也会保存一个包的内部队列,用来等待管道中的DataNode返回确认信息,这个队列被称为确认队列(ask queue)。只有当所有的管道中的DataNode都返回了写入成功的信息文件包,才会从确认队列中删除。
当然HDFS会考虑写入失败的情况,当数据写入节点失败时,HDFS会作出以下反应.首先管道会被关闭,任何在确认通知队列中的文件包都会被添加到数据队列的前端,这样管道中失败的DataNode都不会丢失数据。当前存放于正常工作DataNode之上的文件块会被赋予一个新的身份,并且和NameNode进行关联,这样,如果失败的DataNode过段时间从故障中恢复过来,其中的部分数据块就会被删除。然后管道会把失败的DataNode删除,文件会继续被写到管道中的另外两个DataNode中。最后NameNode会注意到现在的文件块副本数没有到达配置属性要求,会在另外的DataNode上重新安排创建一个副本。随后的文件会正常执行写入操作。
当然,在文件块写入期间,多个DataNode同时出现故障的可能性存在,但是很小。只要dfs.replication.min的属性值(默认为1)成功写入,这个文件块就会被异步复制到其他DataNode中,直到满足dfs.replictaion属性值(默认值为3)。
6)客户端成功完成数据写入的操作后,就会调用close()函数关闭数据流。这步操作会在连接NameNode确认文件写入完全之前将所有剩下的文件包放入DataNode管道,等待通知确认信息。NameNode会知道哪些块组成一个文件(通过DataStreamer获得块的位置信息),这样NameNode只要在返回成功标志前等待块被最小量(dfs.replication.min)复制即可。
HDFS中的读写数据流的更多相关文章
- hadoop学习;大数据集在HDFS中存为单个文件;安装linux下eclipse出错解决;查看.class文件插件
sudo apt-get install eclipse 安装后打开eclipse,提示出错 An error has occurred. See the log file /home/pengeor ...
- [Hadoop]Hadoop章2 HDFS原理及读写过程
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统. HDFS有很多特点: ① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份. ② ...
- 关于oracle的缓冲区机制与HDFS中的edit logs的某些关联性的思考
可能大家会问,oracle和HDFS属于不同场景的存储系统,它们之间为什么会有联系呢?确实,从技术本身来看,他们确实无关联,但利用“整体学习”的思想,跳出技术本身,可以发现Oracle的缓冲区和HDF ...
- [转]Hadoop 读写数据流
Hadoop文件读取 1)客户端通过调用FileSystem对象中的open()函数来读取它做需要的数据.FileSystem是HDFS中DistributedFileSystem的一个实例. 2)D ...
- flink---实时项目----day03---1.练习讲解(全局参数,数据以parquet格式写入hdfs中) 2 异步查询 3 BroadcastState
1 练习讲解(此处自己没跑通,以后debug) 题目见flink---实时项目---day02 kafka中的数据,见day02的文档 GeoUtils package cn._51doit.flin ...
- [转]HDFS中JAVA API的使用
HDFS是一个分布式文件系统,既然是文件系统,就可以对其文件进行操作,比如说新建文件.删除文件.读取文件内容等操作.下面记录一下使用JAVA API对HDFS中的文件进行操作的过程. 对分HDFS中的 ...
- HDFS中JAVA API的使用
HDFS中JAVA API的使用 HDFS是一个分布式文件系统,既然是文件系统,就可以对其文件进行操作,比如说新建文件.删除文件.读取文件内容等操作.下面记录一下使用JAVA API对HDFS中的 ...
- C#中动态读写App.config配置文件
转自:http://blog.csdn.net/taoyinzhou/article/details/1906996 app.config 修改后,如果使用cofnigurationManager立即 ...
- php中并发读写文件冲突的解决方案(文件锁应用示例)
PHP(外文名: Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用开源脚本语言.语法吸收了C语言.Java和Perl的特点,入门门槛较低,易于学习,使用广泛,主要适 ...
随机推荐
- linux,crontab定时任务中为脚本指定使用参数,crontab的脚本中是否可以带参数
需求描述: 今天在写脚本的时候,脚本的运行需要给出几个参数,那么就考虑 在crontab写定时任务的时候,是否也是能够在脚本中,增加参数呢, 因为以前没有这么用过,所以呢,就进行一次测试. 测试过程: ...
- pcduino 无法打开usb摄像头。
1.sudo ./demon http://www.oschina.net/question/994181_118098 2.usb camera interfarce switch :http: ...
- Credential
https://www.cnblogs.com/Hawk-Hong/p/4293651.html 在项目开发,我们经常会使用WebService,但在使用WebService时我们经常会考虑以下问题: ...
- easyui------设置datagrid('getEditor')时焦点问题
代码: var dg = $(DataGrid.TableGridID); var row = { ID: "", UserName: "", Password ...
- python2.0_s12_day19_前端结合后端展示客户咨询纪录
接下来就是将后台视图与前端页面结合起来了完成后台系统了.实现前端展示用户列表1.先在base.html代码中把模版中Dashboard下面的内容清空,如下: 具体删除哪些html代码,自己找吧.2.我 ...
- python2.0 s12 day7
开发的第二阶段 网络编程阶段 之所以叫网络编程,是因为,这里面就不是你在一台机器中玩了.多台机器,CS架构.即客户端和服务器端通过网络进行通信的编程了. 首先想实现网络的通信,你得先学网络通信的一个基 ...
- NGUI在5.3打包失败问题
一.NGUI版本 NGUI是很好用的Unity UI插件. 当前使用版本NGUI Next-Gen UI v3.9.7 (Feb 10, 2016)和NGUI Next-Gen UI 3.9.0两个版 ...
- 更改嵌入式Linux中开机画面----左上角小企鹅图标
一直想给嵌入式仪表加个开机LOGO,但是没有找到更换的方法.最近在网上收集了一些文章,整理一下一共自己参考.目前也还没有试过这种方法究竟是否可以.但察看Kernel源代码可以知道,Linux-2.6的 ...
- cocos2dx游戏--欢欢英雄传说--添加攻击按钮
接下来添加攻击按钮用于执行攻击动作.同时修复了上一版移动时的bug.修复后的Player::walkTo()函数: void Player::walkTo(Vec2 dest) { if (_seq) ...
- JS-鼠标跟随块(一个小圆点跟着鼠标跑)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...