Java三大框架之——Hibernate中的三种数据持久状态和缓存机制
Hibernate中的三种状态
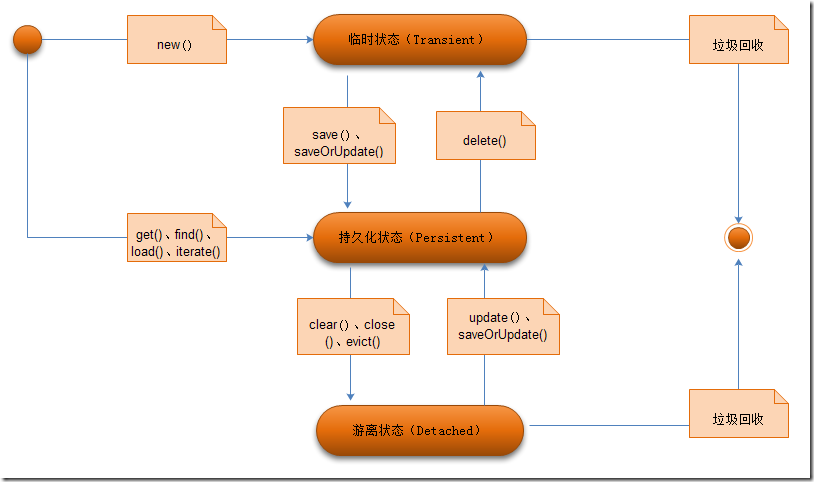
瞬时状态:刚创建的对象还没有被Session持久化、缓存中不存在这个对象的数据并且数据库中没有这个对象对应的数据为瞬时状态这个时候是没有OID。
持久状态:对象经过Session持久化操作,缓存中存在这个对象的数据为持久状态并且数据库中存在这个对象对应的数据为持久状态这个时候有OID。
游离状态:当Session关闭,缓存中不存在这个对象数据而数据库中有这个对象的数据并且有OID为游离状态。
注:OID为了在系统中能够找到所需对象,我们需要为每一个对象分配一个唯一的表示号。在关系数据库中我们称之为关键字,而在对象术语中,则叫做对象标识
(Object identifier-OID).通常OID在内部都使用一个或多个大整数表示,而在应用程序中则提供一个完整的类为其他类提供获取、操作。
Hibernate数据状态图:
需要注意的是:
当对象的临时状态将变为持久化状态。当对象在持久化状态时,它一直位于 Session 的缓存中,对它的任何操作在事务提交时都将同步到数据库,因此,对一个已经持久的对象调用 save() 或 update() 方法是没有意义的。
Student stu = new Strudnet(); stu.setCarId(“200234567”); stu.setId(“100”); // 打开 Session, 开启事务 //将stu对象持久化操作
session.save(stu); stu.setCardId(“20076548”); //再次对stu对象进行持久化操作
session.save(stu); // 无效 session.update(stu); // 无效 // 提交事务,关闭 Session
Hibernate缓存机制
什么是缓存?
缓存是介于应用程序和物理数据源之间,其作用是为了降低应用程序对物理数据源访问的频次,从而提高了应用的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据。
缓存有什么好处?
缓存的好处是降低了数据库的访问次数,提高应用性能,减少了读写数据的时间
什么时候适合用缓存?
程序中经常用到一些不变的数据内容,从数据库查出来以后不会去经常修改它而又经常要用到的就可以考虑做一个缓存,以后读取就从缓存来读取,而不必每次都去查询数据库。因为硬盘的速度比内存的速度慢的多。从而提高了程序的性能,缓存的出现就会为了解决这个问题
Hibernate中的缓存
Hibernate中的缓存包括一级缓存(Session缓存)、二级缓存(SessionFactory缓存)和查询缓存。
一级缓存(Session缓存)
由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。Session级缓存是必需的,不允许而且事实上也无法卸除。在Session级缓存中,持久化类的每个实例都具有唯一的OID。
当应用程序调用Session的save()、update()、savaeOrUpdate()、get()或load(),以及调用查询接口的list()、iterate()或filter()方法时,如果在Session缓存中还不存在相应的对象,Hibernate就会把该对象加入到第一级缓存中。
当清理缓存时,Hibernate会根据缓存中对象的状态变化来同步更新数据库。
Session为应用程序提供了两个管理缓存的方法:evict(Object obj):从缓存中清除参数指定的持久化对象。clear():清空缓存中所有持久化对象。
public static void testOneLeveCache(){
Session session=HibernateUtil.getSession();
//获取持久化对象Dept
Dept d1=(Dept)session.get(Dept.class, 10);
//再次获取持久化对象Dept
Dept d2=(Dept)session.get(Dept.class, 10);
session.close();
}
通过Session的get()方法获取到了Dept对象默认会将Dept对象保存到一级缓存中(Session缓存) 当第二次获取的时候会先从一级缓存中查询对应的对象(前提是不能清空或关闭Session否则一级缓存会清空或销毁)如果一级缓存中存在相应的对象就不会到数据库中查询 所以只执行一次查询的查询代码如下:
Hibernate:
select
dept0_.DEPTNO as DEPTNO0_0_,
dept0_.DNAME as DNAME0_0_,
dept0_.LOC as LOC0_0_
from
SCOTT.DEPT dept0_
where
dept0_.DEPTNO=?
如何清除一级缓存?
通过session.clear();//清除所有缓存
session.evict();//清除指定缓存
public static void testOneLeveCache(){
Session session=HibernateUtil.getSession();
SessionFactory sf = HibernateUtil.getSessionFactory();
//获取持久化对象Dept
Dept d1=(Dept)session.get(Dept.class, 10);
session.clear();//清除所有缓存
session.evict(d1);//清除指定缓存
//再次获取持久化对象Dept
Dept d2=(Dept)session.get(Dept.class, 10);
session.close();
}
使用session.evict(Object obj)会删除指定的Bean所以当你查询被你删除二级缓存的Bean时也会执行两条SQL语句
使用Session.clear()清除后会发现执行了两条SQL语句:
Hibernate:
select
dept0_.DEPTNO as DEPTNO0_0_,
dept0_.DNAME as DNAME0_0_,
dept0_.LOC as LOC0_0_
from
SCOTT.DEPT dept0_
where
dept0_.DEPTNO=?
Hibernate:
select
dept0_.DEPTNO as DEPTNO0_0_,
dept0_.DNAME as DNAME0_0_,
dept0_.LOC as LOC0_0_
from
SCOTT.DEPT dept0_
where
dept0_.DEPTNO=?
二级缓存(SessionFactory缓存)
由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。
save、update、saveOrupdate、load、get、list、query、Criteria方法都会填充二级缓存
get、load、iterate会从二级缓存中取数据session.save(user)
如果user主键使用“native”生成,则不放入二级缓存.
第二级缓存是可选的,是一个可配置的插件,默认下SessionFactory不会启用这个插件。Hibernate提供了org.hibernate.cache.CacheProvider接口,它充当缓存插件与Hibernate之间的适配器。
Hibernate的二级缓存策略的一般过程如下:
1) 条件查询的时候,总是发出一条select * from table_name where …. (选择所有字段)这样的SQL语句查询数据库,一次获得所有的数据对象。
2) 把获得的所有数据对象根据ID放入到第二级缓存中。
3) 当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;查不到,再查询数据库,把结果按照ID放入到缓存。
4) 删除、更新、增加数据的时候,同时更新缓存。
Hibernate的二级缓存策略,是针对于ID查询的缓存策略,对于条件查询则毫无作用。为此,Hibernate提供了针对条件查询的查询缓存(Query Cache)。
配置二级缓存(SessionFactory缓存):
在hibernate.cfg.xml中配置以下代码
<!-- 开启二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- 为hibernate指定二级缓存的实现类 -->
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
指明哪些类需要放入二级缓存,需要长期使用到的对象才有必要放入二级缓存放入二级缓存的方式有两种:
1.在hibernate.cfg.xml中配置
<class-cache class="entity.PetInfo" usage="read-only" /> //不允许更新缓存中的对象
<class-cache class="entity.PetInfo" usage="read-write" /> //允许更新缓存中的对象
2.在Bean.hbm文件中配置
<hibernate-mapping>
<class name="com.bdqn.entity.Dept" table="DEPT" schema="SCOTT" >
<cache usage="read-only"/>//将这个类放入二级缓存
<id name="deptno" type="java.lang.Integer">
<column name="DEPTNO" precision="2" scale="0" />
<generator class="assigned"></generator>
</id>
<property name="dname" type="java.lang.String">
<column name="DNAME" length="14" />
</property>
</class>
</hibernate-mapping>
在ehcache.xml配置文件中可以设置缓存的最大数量、是否永久有效、时间等
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
/>
如何清除二级缓存?
需要用SessionFactory来管理二级缓存代码如下:
sessionFactory.evict(Entity.class);//清除所有Entity sessionFactory.evict(Entity.class,id);//清除指定Entity
比如:
//用SessionFacotry管理二级缓存 SessionFactory factory=HibernateUtils.getSessionFactory(); //evict()把id为1的Student对象从二级缓存中清除. factory.evict(Student.class, 1);
//evict()清除所有二级缓存. factory.evict(Student.class);
什么样的数据适合存放到第二级缓存中?
1) 很少被修改的数据
2) 不是很重要的数据,允许出现偶尔并发的数据
3) 不会被并发访问的数据
4) 常量数据
不适合存放到第二级缓存的数据?
1) 经常被修改的数据
2) 绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发
3) 与其他应用共享的数据。
查询缓存(Query Cache)
hibernate的查询缓存是主要是针对普通属性结果集的缓存, 而对于实体对象的结果集只缓存id。
在一级缓存,二级缓存和查询缓存都打开的情况下作查询操作时这样的:
查询普通属性,会先到查询缓存中取,如果没有,则查询数据库;查询实体,会先到查询缓存中取id,如果有,则根据id到缓存(一级/二级)中取实体,如果缓存中取不到实体,再查询数据库。
在hibernate.cfg.xml配置文件中,开启查询缓存
<!-- 是否开启查询缓存,true开启查询缓存,false关闭查询缓存 -->
<property name="cache.use_query_cache">true</property>
开启查询缓存后还需要在程序中进行启用查询缓存
public static void testQueryCache(){
Session session=HibernateUtil.getSession();
String hql="from Emp as e";
Query query=session.createQuery(hql);
query.setCacheable(true);//启用查询缓存(二级缓存)
List<Emp> empList=query.list();
session.close();
}
查询缓存是基于二级缓存机制如果根据Bean的属性查询可以不开启二级缓存代码如下:
session = HibernateUtils.getSession();
t = session.beginTransaction();
Query query = session.createQuery("select s.name from Student s");
//启用查询缓存
query.setCacheable(true);
List<String> names = query.list();
for (Iterator<String> it = names.iterator(); it.hasNext();) {
String name = it.next();
System.out.println(name);
}
System.out.println("================================");
query = session.createQuery("select s.name from Student s");
//启用查询缓存
query.setCacheable(true);
//没有发出查询语句,因为这里使用的查询缓存
names = query.list();
for (Iterator<String> it = names.iterator(); it.hasNext();) {
String name = it.next();
System.out.println(name);
}
t.commit();
Java三大框架之——Hibernate中的三种数据持久状态和缓存机制的更多相关文章
- Hibernate中的三种数据状态
Hibernate中的三种数据状态(临时.持久.游离) 1.临时态(瞬时态) 不存在于session中,也不存在于数据库中的数据,被称为临时态. 比如:刚刚使用new关键字创建出的对象. 2.持久态 ...
- 浅谈Hibernate中的三种数据状态
Hibernate中的三种数据状态:临时.持久.游离 1.临时态(瞬时态) 不存在于session中,也不存在于数据库中的数据,被称为临时态. 数据库中没有数据与之对应,超过作用域会被JVM垃圾回收器 ...
- Java三大框架之——Hibernate关联映射与级联操作
什么是Hibernate中的关联映射? 简单来说Hibernate是ORM映射的持久层框架,全称是(Object Relational Mapping),即对象关系映射. 它将数据库中的表映射成对应的 ...
- java三大框架——Struts + Hibernate + Spring
Struts主要负责表示层的显示 Spring利用它的IOC和AOP来处理控制业务(负责对数据库的操作) Hibernate主要是数据持久化到数据库 再用jsp的servlet做网页开发的时候有个 w ...
- Java三大框架之——Hibernate
什么是Hibernate? Hibernate是基于ORM(O:对象,R:关系,M:映射)映射的持久层框架,是一个封装JDBC的轻量级框架,主要实现了对数据库的CUPD操作. 注:CRUD是指在做计算 ...
- java三大框架之一hibernate使用入门
综述:Hibernate的作用就是让实体类与数据库映射,使数据持久化,用于替代JDBC,使我们不致于写那么多sql语句代码. 1. 首先在官网www.hibernate.org下载hibernate包 ...
- Java_Web三大框架之Hibernate+jsp+selvect+HQL查询数据
俗话说:"好记性不如烂笔头".本人学习Hibernate也有一个星期了,对Hibernate也有一个初步的了解.下面对Hibernate显示数据做个笔记,使用租房系统的Hibern ...
- Java集合框架Collection(1)ArrayList的三种遍历方法
ArrayList是java最重要的数据结构之一,日常工作中经常用到的就是ArrayList的遍历,经过总结,发现大致有三种,上代码: package com.company; import java ...
- python网络爬虫数据中的三种数据解析方式
一.正则解析 常用正则表达式回顾: 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线 ...
随机推荐
- Android的Kotlin秘方(I):OnGlobalLayoutListener
春节后,又重新“开张”.各位高手请继续支持.谢谢! 原文标题:Kotlin recipes for Android (I): OnGlobalLayoutListener 原文链接:http://an ...
- [css]实现垂直居中水平居中的几种方式
转自博客 http://blog.csdn.net/freshlover/article/details/11579669 居中方式: 一.容器内(Within Container) 内容块的父容器设 ...
- BZOJ 3504: [Cqoi2014]危桥 [最大流]
3504: [Cqoi2014]危桥 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 1407 Solved: 703[Submit][Status] ...
- babel-loader-presets
babel-loader的presets的设置有一定的顺序.es2015必须出现在stage-0前面,我记得这是因为es2015是ES6的标准,state-0等是对ES7一些提案的支持, state- ...
- Jquery对网页高度、宽度的操作
Jquery获取网页的宽度.高度 网页可见区域宽: document.body.clientWidth 网页可见区域高: document.body.clientHeight 网页可见区域宽: doc ...
- Flux 普及读本
话说当时做 APP 时,三月不知肉味,再次将眼光投放前端,有种天上一天,地下一年的感觉. Flux 是一种思想 了解的最好方式当然是看Flux官方文档了.React 中文站点也能找到对应的翻译版本,但 ...
- HTML5 & CSS3初学者指南(2) – 样式化第一个网页
介绍 我们已经使用基本的 HTML 编写了一个网页.但是,写出来的 HTML 代码的网页看起来很平淡,没有吸引力. 如何改善这种很平淡的页面呢? 让我们开始使用网页的基本样式来改善页面效果,我们将会使 ...
- Android Studio 轻松整理字符串到string.xml中
昨天了解了Alt+Enter快捷键的大用处,今天又发现了一个快捷的方法,必须记下来.转载请注明出处http://www.cnblogs.com/LT5505/p/5466630.html 1.首先代码 ...
- Alcatraz 的安装和删除
Xcode 所有的插件都安装在目录: ~/Library/Application Support/Developer/Shared/Xcode/Plug-ins/ 你也可以手工切换到这个目录来删除插件 ...
- 新编码神器Atom使用纪要
Atom是 Github 专门为程序员推出的一个跨平台文本编辑器.她很大程度上继承了SublimeText的美,而又不仅如此.有费了蛮大力气总结了一篇关于SublimeText文章: 如何优雅地使用S ...