关于后缀数组的倍增算法和height数组
自己看着大牛的论文学了一下后缀数组,看了好久好久,想了好久好久才懂了一点点皮毛TAT
然后就去刷传说中的后缀数组神题,poj3693是进化版的,需要那个相同情况下字典序最小,搞这个搞了超久的说。
先简单说一下后缀数组。首先有几个重要的数组:
·SA数组(后缀数组):保存所有后缀排序后从小到大的序列。[即SA[i]=j表示排名第i的后缀编号为j]
·rank数组(名次数组):记录后缀的名次。[即rank[i]=j表示编号为i的后缀排名第j]
用倍增算法可以在O(nlogn)时间内得出这两个数组。
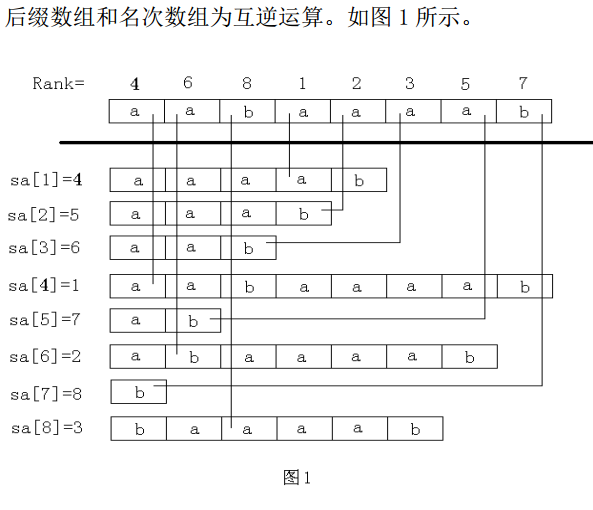
具体过程如下:

即每次长度增加一倍,直接用前面算出的排名作为关键字,问题转化为给有两个关键字的序列排序,这里可以用基数排序,每次排序时间为n,一共进行了logn次,所以总共时间复杂度为O(nlogn)。要注意如果一个字符串包含另一个字符串,长度小的较小,那就是说如果没有第二关键字,把第二关键字默认为0即可。具体如下:

数组y保存的是对第二关键字排序的结果
数组wr保存的是对第二关键字排序后的rank值
ln为当前子串的长度
rank值为排名,在这里即为关键字的值
排序时如果两个关键字相同即默认位置前的较小,那么我们先按照第二关键字排序,再按照第一关键字排序,最后排出来的就是第一第二关键字合并的结果(基数排序的方法)
下一步是计算新的rank值。这里要注意的是,可能有多个字符串的rank值是相同的,所以必须比较两个字符串是否完全相同,wr数组的值已经没有必要保存,为了节省空间,这里用wr数组保存rank值。

一直做到所有后缀的排名不同结束,时间复杂度为O(nlogn)。
后缀数组的大部分应用都跟一个很重要的height数组有关。
height数组定义:定义height[i]=suffix(sa[i-1])和suffix(sa[i])的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀。
对于j和k,不妨设rank[j]<rank[k],则有以下性质:
suffix(j)和suffix(k)的最长公共前缀为:
height[rank[j]+1], height[rank[j]+2], height[rank[j]+3], …, height[rank[k]]中的最小值。
h数组有以下性质: h[i]≥h[i-1]-1
证明:
设suffix(k)是排在suffix(i-1)前一名的后缀,则它们的最长公共前缀是h[i-1]。那么suffix(k+1)将排在suffix(i)的前面(这里要求h[i-1]>1,如果h[i-1]≤1,原式显然成立)并且suffix(k+1)和suffix(i)的最长公共前缀是h[i-1]-1,所以suffix(i)和在它前一名的后缀的最长公共前缀至少是h[i-1]-1。因此得证。(如图)

按照h[1],h[2],……,h[n]的顺序计算,并利用h数组的性质,时间复杂度可以降为O(n)。
实现的时候其实没有必要保存h数组,只须按照h[1],h[2],……,h[n]的顺序计算即可。

标程如下:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#define Maxn 11000
using namespace std; int sa[Maxn],rank[Maxn],y[Maxn],Rsort[Maxn];
int wr[Maxn],n,a[Maxn],height[Maxn]; //cmp 第一关键字且第二关键字相同
bool cmp(int k1,int k2,int ln){return wr[k1]==wr[k2] && wr[k1+ln]==wr[k2+ln];}
int mymax(int x,int q) {return x>q?x:q;} void get_sa(int m) //构建SA后缀数组
{
int i,k,p,ln; memcpy(rank,a,sizeof(rank));
//a数组:原字符串,rank名次数组 for (i=;i<=m;i++) Rsort[i]=;
for (i=;i<=n;i++) Rsort[rank[i]]++;
for (i=;i<=m;i++) Rsort[i]+=Rsort[i-];
for (i=n;i>=;i--) sa[Rsort[rank[i]]--]=i;
//以上四句为基数排序,不懂的看flash ln=; p=;
// ln为当前子串的长度,p表示有多少不相同的子串
while (p<n)
{
for (k=,i=n-ln+;i<=n;i++) y[++k]=i;
for (i=;i<=n;i++) if (sa[i]>ln) y[++k]=sa[i]-ln;
for (i=;i<=n;i++) wr[i]=rank[y[i]];//在这里rank表示一个值
//数组y保存的是对第二关键字排序的结果(2-sa)。
//数组wr保存的是对第二关键字排序后的rank值(rank即第一关键字)
//wr[i]->第二关键字排名为i的第一关键字的值
//以下为对第一关键字排序
for (i=;i<=m;i++) Rsort[i]=;
for (i=;i<=n;i++) Rsort[wr[i]]++;
for (i=;i<=m;i++) Rsort[i]+=Rsort[i-];
for (i=n;i>=;i--) sa[Rsort[wr[i]]--]=y[i]; memcpy(wr,rank,sizeof(wr));
p=; rank[sa[]]=;
for (i=;i<=n;i++)
{
if (!cmp(sa[i],sa[i-],ln)) p++;
rank[sa[i]]=p;
}
//得到新的rank数组
m=p; ln*=;//m个rank ln长度
}
a[]=; sa[]=;
} void get_he()
{
int i,j,kk=;
//height[i]表示排名为i的子串和比起前一位排名的子串的最长公共前缀
for (i=;i<=n;i++) //目前求的是位置为i的子串的height值
{
j=sa[rank[i]-];
if (kk) kk--; while (a[j+kk]==a[i+kk]) kk++;
height[rank[i]]=kk;
}
} int main()
{
int i,m=-;
char c;
n=;
while()
{
scanf("%c",&c);
if(c=='\n') break;
a[++n]=c-'a';
}
for (i=;i<=n;i++)
m=mymax(m,a[i]);
get_sa(m+);
for(i=;i<=n;i++)
printf("%d ",sa[i]); }
后缀数组
做poj3415的时候感觉上面那个代码有点小瑕疵诶~

还有一个地方:
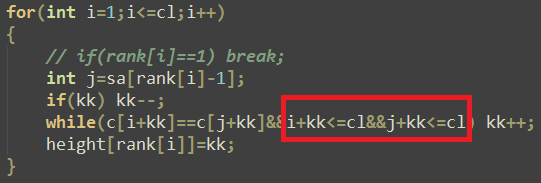
可以注意一下~~
关于后缀数组的倍增算法和height数组的更多相关文章
- 后缀数组入门(二)——Height数组与LCP
前言 看这篇博客前,先去了解一下后缀数组的基本操作吧:后缀数组入门(一)--后缀排序. 这篇博客的内容,主要建立于后缀排序的基础之上,进一步研究一个\(Height\)数组以及如何求\(LCP\). ...
- 后缀数组(SA)及height数组
最近感觉自己越来越蒟蒻了--后缀数组不会,费用流不会-- 看着别人切一道又一道的题,我真是很无奈啊-- 然后,我花了好长时间,终于弄懂了后缀数组. 后缀数组是什么? 后缀SASASA数组 给你一个字符 ...
- 【字符串匹配】KMP算法和next数组的c/c++实现
KMP算法基本思想有许多博客都写到了,写得也十分形象,不懂得可以参考下面的传送门,我就不解释基本思想了.本文主要给出KMP算法及next数组的计算方法(主要是很多网上的代码本人(相信应该是许多人吧)看 ...
- 【POJ2774】Long Long Message(后缀数组求Height数组)
点此看题面 大致题意: 求两个字符串中最长公共子串的长度. 关于后缀数组 关于\(Height\)数组的概念以及如何用后缀数组求\(Height\)数组详见这篇博客:后缀数组入门(二)--Height ...
- 后缀数组:倍增法和DC3的简单理解
一些定义:设字符串S的长度为n,S[0~n-1]. 子串:设0<=i<=j<=n-1,那么由S的第i到第j个字符组成的串为它的子串S[i,j]. 后缀:设0<=i<=n- ...
- 【后缀数组之height数组】
模板奉上 int rank[maxn],height[maxn]; void calheight(int *r,int *sa,int n) { ; ;i<=n;i++) rank[sa[i]] ...
- BZOJ2251 [2010Beijing Wc]外星联络 后缀数组 + Height数组
Code: #include <bits/stdc++.h> #define setIO(s) freopen(s".in", "r", stdin ...
- 后缀数组的一些性质----height数组
height数组:定义 height[i] = suffix[i-1] 和 suffix[i] 的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀.那么对于 j 和 k 不妨设 Rank[j] & ...
- 洛谷P2408 不同子串个数 后缀数组 + Height数组
## 题目描述: 给你一个长为 $N$ $(N<=10^5)$ 的字符串,求不同的子串的个数我们定义两个子串不同,当且仅当有这两个子串长度不一样 或者长度一样且有任意一位不一样.子串的定义:原字 ...
随机推荐
- 20160322 javaweb 学习笔记--response 重定向
//一般方法 response.setStatus(302); response.setHeader("Location", "/20160314/index.jsp&q ...
- ACM——简单排序
简单选择排序 时间限制(普通/Java):1000MS/3000MS 运行内存限制:65536KByte总提交:836 测试通过:259 描述 给定输入排序元素 ...
- [转] c# 数据类型占用的字节数
http://www.cnblogs.com/laozuan/archive/2012/04/24/2467888.html
- [linux] 系统管理常用命令
1.查看某个软件是否安装: rpm -qa|grep software_name 2.top命令,显示系统的动态视图,q退出 3.ps aux|grep process_name 显示正在运行的进程 ...
- 利用ORACLE ADV 功能完成SQL TUNING 调优(顾问培训) “让DBA失业还是解脱?”
oracle自动判断SQL性能功能. 11G的ADV,建议.SNAPSHOT,数据集合, 存储在oracle sys $_开头的表(10几条). 创建SNAPSHOT时选择天数, 默认14天. sq ...
- C#基础整理
元旦整理书架发现一本小册子——<C#精髓>中国出版社2001年出版的,粗略翻了下关于C#的知识点挺全的虽然内容谈得很浅也有很多过时的内容(话说这本书是我在旧书店花5块钱淘的)我保留原有章节 ...
- 注释玩转webapi
using System; using System.Collections.Generic; using System.Net.Http.Formatting; using System.Web.H ...
- 04_过滤器Filter_01_入门简述
[简述] Filter也称之为过滤器.通过Filter技术,对web服务器管理的所有资源(如:Jsp.Servlet.静态图片文件.静态HTML文件等)进行拦截,从而实现一些特殊的功能.例如实现URL ...
- HDU_2156 分数矩阵
Problem Description 我们定义如下矩阵: 1/1 1/2 1/3 1/2 1/1 1/2 1 ...
- C++指针学习笔记
本文参考http://www.prglab.com/cms/pages/c-tutorial/advanced-data/pointers.php 1.存储其它变量地址的变量(如下面例子中的addre ...