(3)pyspark----dataframe观察
1、读取:
- sparkDF = spark.read.csv(path)
- sparkDF = spark.read.text(path)
2、打印:
sparkDF.show()【这是pandas中没有的】:打印内容
sparkDF.head():打印前面的内容
sparkDF.describe():统计信息
sparkDF.printSchema():打印schema,列的属性信息打印出来【这是pandas中没有的】
sparkDF.columns:将列名打印出来
3、选择列
【select函数,原pandas中没有】
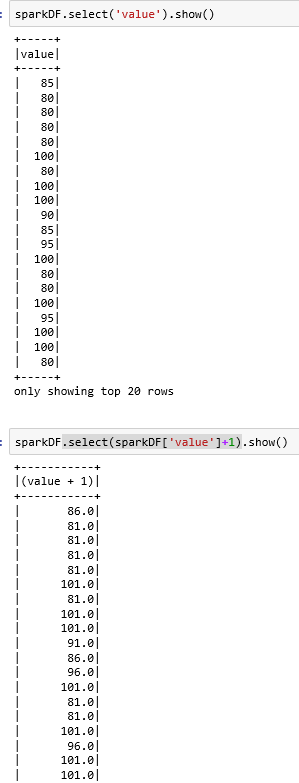
sparkDF.select('列名1','列名2‘).show():选择dataframe的两列数据显示出来
sparkDF.select ( sparkDF['列名1']+1 , '列名2' ).show():直接对列1进行操作(值+1)打印出来
4、筛选列:
filter【类似pandas中dataframe的采用列名来筛选功能】
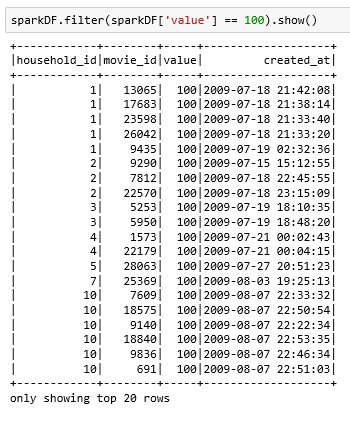
sparkDF.filter ( sparkDF['value'] == 100 ).show():将value这一列值为100的行筛选出来
5、计算不重复值以及统计dataframe的行数
distinct()函数:将重复值去除
sparkDF.count():统计dataframe中有多少行

将评分为100的电影数量统计出来:

(3)pyspark----dataframe观察的更多相关文章
- PySpark DataFrame 添加自增 ID
PySpark DataFrame 添加自增 ID 本文原始地址:https://sitoi.cn/posts/62634.html 在用 Spark 处理数据的时候,经常需要给全量数据增加一列自增 ...
- pyspark dataframe 格式数据输入 做逻辑回归
该方法好处是可以调节阈值,可调参数比其他形式模型多很多. [参照]http://blog.csdn.net/u013719780/article/details/52277616 [3种模型效果比较: ...
- pyspark dataframe 常用操作
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能.当然主要对类SQL的支持. 在实际工作中会遇到这样的情况,主要是会进行两个数据集的筛选.合并,重新入库. 首先加 ...
- Pyspark 使用 Spark Udf 的一些经验
起初开始写一些 udf 的时候感觉有一些奇怪,在 spark 的计算中,一般通过转换(Transformation) 在不触发计算(Action) 的情况下就行一些预处理.udf 就是这样一个好用的东 ...
- 如何在Windows上的Jupyter Notebook中安装和运行PySpark
When I write PySpark code, I use Jupyter notebook to test my code before submitting a job on the clu ...
- Pyspark常用API总结
DF 类似于二维表的数据结果 mame age 狗山石 23 获取df的列名: df.columns 显示当前值 打印 df.show() show(2) show括号里面传入参数可以显示查看几行 s ...
- SQL->Python->PySpark计算KS,AUC及PSI
KS,AUC 和 PSI 是风控算法中最常计算的几个指标,本文记录了多种工具计算这些指标的方法. 生成本文的测试数据: import pandas as pd import numpy as np i ...
- pyspark中的dataframe的观察操作
来自于:http://www.bubuko.com/infodetail-2802814.html 1.读取: sparkDF = spark.read.csv(path) sparkDF = spa ...
- PySpark的DataFrame处理方法
转:https://blog.csdn.net/weimingyu945/article/details/77981884 感谢! ---------------------------------- ...
- 将 数据从数据库 直接通过 pyspark 读入到dataframe
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Python Spark S ...
随机推荐
- [NoiPlus2016]换教室
flag++ //Writer : Hsz %WJMZBMR%tourist%hzwer #include <iostream> #include <cstdio> #incl ...
- linux 编译网卡驱动
将smsc7500网卡驱动拷贝到/drive/net/usb文件夹下 拷贝ioctl_7500.h smsc7500usbnet.c smsc7500version.h smsclan7500.h ...
- 手机上怎么去掉a 标签中的img点击时的阴影?
添加: <style type="text/css"> a { -webkit-tap-highlight-color: transparent; -webkit-to ...
- Cookie 工具类
一.导入 jar 包 <dependency> <groupId>javax.servlet</groupId> <artifactId>servlet ...
- [Web Worker] Introduce to Web Worker
What is web worker for? OK, read it docs to get full details idea. Or just a quick intro to web work ...
- string转utf8后解决TTS识别中文的问题
今天遇到string字符编码的问题,由于遇到了用TTS将文本转语音的一个API,里面的中文必须是utf8的,我传了一个uncode编码的中文进去,就一直不能正常读出来.后来才发现是编码的问题.这里在网 ...
- 2016.02.25,英语,《Vocabulary Builder》Unit 02
ag:来自拉丁语do.go.lead.drive,an agenda是要做事情的清单,an agent是代表他们做事的人,同时也是为他人做事的机构.拉丁语litigare包括词根lit,即lawsui ...
- ”危险“的RESTRICT与GCC的编译优化(编程者对编译器所做的一个“承诺”:使用restrict修饰过的指针,它所指向的内容只能经由该指针修改)
restrict是C99标准中新添加的关键字,对于从C89标准开始起步学习C语言的同学来说(包括我),第一次看到restrict还是相当陌生的.Wikipedia给出的解释如下: In the C p ...
- mysqil操作数据库
mysqil操作数据库 每次用到mysql_connect连接数据库的时候都会提示: 1 Deprecated: mysql_connect(): The mysql extension is dep ...
- lightoj--1354-- IP Checking(水题)
IP Checking Time Limit: 2000MS Memory Limit: 32768KB 64bit IO Format: %lld & %llu Submit Sta ...