(3)pyspark----dataframe观察
1、读取:
- sparkDF = spark.read.csv(path)
- sparkDF = spark.read.text(path)
2、打印:
sparkDF.show()【这是pandas中没有的】:打印内容
sparkDF.head():打印前面的内容
sparkDF.describe():统计信息
sparkDF.printSchema():打印schema,列的属性信息打印出来【这是pandas中没有的】
sparkDF.columns:将列名打印出来
3、选择列
【select函数,原pandas中没有】
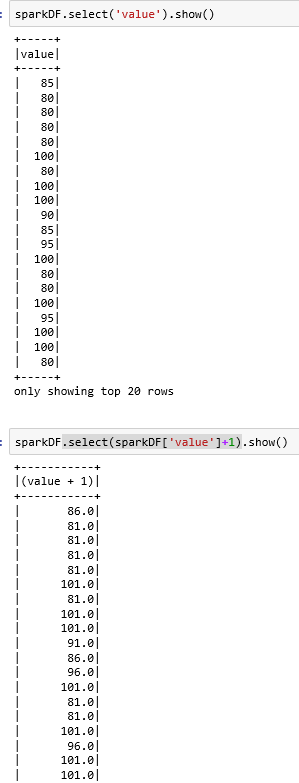
sparkDF.select('列名1','列名2‘).show():选择dataframe的两列数据显示出来
sparkDF.select ( sparkDF['列名1']+1 , '列名2' ).show():直接对列1进行操作(值+1)打印出来
4、筛选列:
filter【类似pandas中dataframe的采用列名来筛选功能】
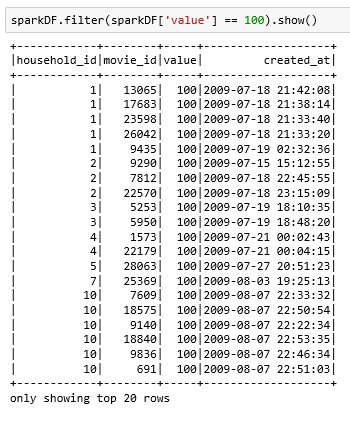
sparkDF.filter ( sparkDF['value'] == 100 ).show():将value这一列值为100的行筛选出来
5、计算不重复值以及统计dataframe的行数
distinct()函数:将重复值去除
sparkDF.count():统计dataframe中有多少行

将评分为100的电影数量统计出来:

(3)pyspark----dataframe观察的更多相关文章
- PySpark DataFrame 添加自增 ID
PySpark DataFrame 添加自增 ID 本文原始地址:https://sitoi.cn/posts/62634.html 在用 Spark 处理数据的时候,经常需要给全量数据增加一列自增 ...
- pyspark dataframe 格式数据输入 做逻辑回归
该方法好处是可以调节阈值,可调参数比其他形式模型多很多. [参照]http://blog.csdn.net/u013719780/article/details/52277616 [3种模型效果比较: ...
- pyspark dataframe 常用操作
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能.当然主要对类SQL的支持. 在实际工作中会遇到这样的情况,主要是会进行两个数据集的筛选.合并,重新入库. 首先加 ...
- Pyspark 使用 Spark Udf 的一些经验
起初开始写一些 udf 的时候感觉有一些奇怪,在 spark 的计算中,一般通过转换(Transformation) 在不触发计算(Action) 的情况下就行一些预处理.udf 就是这样一个好用的东 ...
- 如何在Windows上的Jupyter Notebook中安装和运行PySpark
When I write PySpark code, I use Jupyter notebook to test my code before submitting a job on the clu ...
- Pyspark常用API总结
DF 类似于二维表的数据结果 mame age 狗山石 23 获取df的列名: df.columns 显示当前值 打印 df.show() show(2) show括号里面传入参数可以显示查看几行 s ...
- SQL->Python->PySpark计算KS,AUC及PSI
KS,AUC 和 PSI 是风控算法中最常计算的几个指标,本文记录了多种工具计算这些指标的方法. 生成本文的测试数据: import pandas as pd import numpy as np i ...
- pyspark中的dataframe的观察操作
来自于:http://www.bubuko.com/infodetail-2802814.html 1.读取: sparkDF = spark.read.csv(path) sparkDF = spa ...
- PySpark的DataFrame处理方法
转:https://blog.csdn.net/weimingyu945/article/details/77981884 感谢! ---------------------------------- ...
- 将 数据从数据库 直接通过 pyspark 读入到dataframe
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Python Spark S ...
随机推荐
- sublime 自定义快捷生成代码块
菜单栏目选 Tools(工具) =>Developer(插件开发)=>New Snippet....(新建代码片段),如图: 接着会新开一个标签页,会附带一些内容:如图: 将“Hello, ...
- 处理问题:windows server 2016由于没有远程桌面授权服务器可以提供许可证,远程会话被中断。请跟服务器管理员联系
windows server可以多用户同时登陆,默认最大远程登录数量为2,如果有更多人需要同时远程登录,则需要安装远程桌面授权服务,第一次安装后,免费期为120天,超过则无法正常远程登录. 解决办法如 ...
- alsa-lib 交叉编译以及声卡驱动测试 (转)
l 下载alsa-utils, alsa-lib, 版本要一致 http://www.alsa-project.org/main/index.php/Download l 编译alsa-lib . ...
- 如何指定GCC的默认头文件路径
如何指定GCC的默认头文件路径 网上偶搜得之,以之为宝:)原地址:http://blog.chinaunix.net/u/28781/showart.php?id=401631============ ...
- 《代码敲不队》第八次团队作业:Alpha冲刺 第三天
项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 代码敲不队 作业学习目标 掌握软件编码实现的工程要求. 团队项目github仓库地址链接 GitH ...
- FansUnion:共同写博客计划终究还是“流产”了
首先说说我原本的计划:我和周围的同学.朋友.好友 共同维护一个博客. 我对其他人并没有过高的期待.我一个人的写作量 = 其他人的写作量. 现实是,其他人没有怎么写. 对于,这个结果,我非常低无奈.谩骂 ...
- 不可靠信号SIGCHLD丢失的问题
如果采用 void sig_chld(int signo) { pid_t pid; int stat; while((pid = waitp ...
- 在Eclipse中创建Maven多模块项目
在Eclipse中创建Maven多模块项目1,创建多模块项目选择File>New>Project,打开New Project窗口,选择Maven>Maven Project,选择下一 ...
- iOS多线程与网络开发之解析json数据
郝萌主倾心贡献,尊重作者的劳动成果,请勿转载. // 同步发送信息 2 NSData *data = [NSURLConnection sendSynchronousRequest:request r ...
- POJ 3180 Tarjan
题意:找强连通中点数大于2的强连通分量个数 思路:Tarjan // By SiriusRen #include <cstdio> #include <algorithm> u ...