【Python3爬虫】猫眼电影爬虫(破解字符集反爬)
一、页面分析
首先打开猫眼电影,然后点击一个正在热播的电影(比如:毒液)。打开开发者工具,点击左上角的箭头,然后用鼠标点击网页上的票价,可以看到源码中显示的不是数字,而是某些根本看不懂的字符,这是因为使用了font-face定义字符集,并通过unicode去映射展示,所以我们在网页上看到的是数字,但是在源码中看到的却是别的字符。

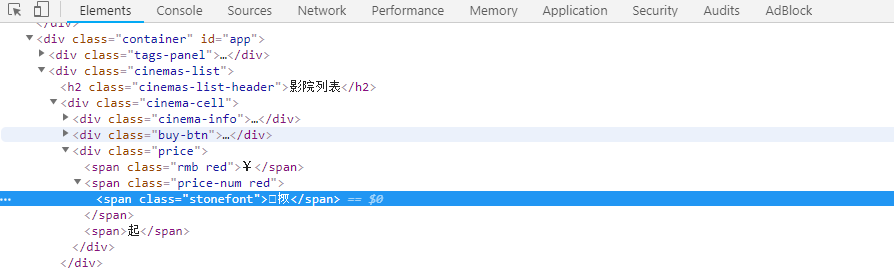
碰到这些根本看不懂的字符怎么办呢?不慌,右键选择查看网页源代码,然后找到相应的位置(如下图)。那么是不是“”映射出来就是28呢?

通过查看源码,可以找到如下内容, 而当我们访问这里面的链接的时候,就可以下载相应的字体文件,关于font-face可以点击这里查看了解:

当我下载好字体文件后,满心欢喜的双击想要点开的时候,却发现无法打开(T_T)。查阅资料之后知道了一个叫做FontCreator的软件,用这个软件可以打开我们下载的字体文件,没有安装这个软件的可以进入官网https://www.high-logic.com/下载安装,如果下载得很慢的可以用百度云下载(链接:https://pan.baidu.com/s/1ImxwPhKdzZo2g4bIjiGCZw ,提取码:m0yf )。下载好之后打开软件,看到如下界面,选择Use Evaluation Version,这个软件我们可以免费使用三十天。
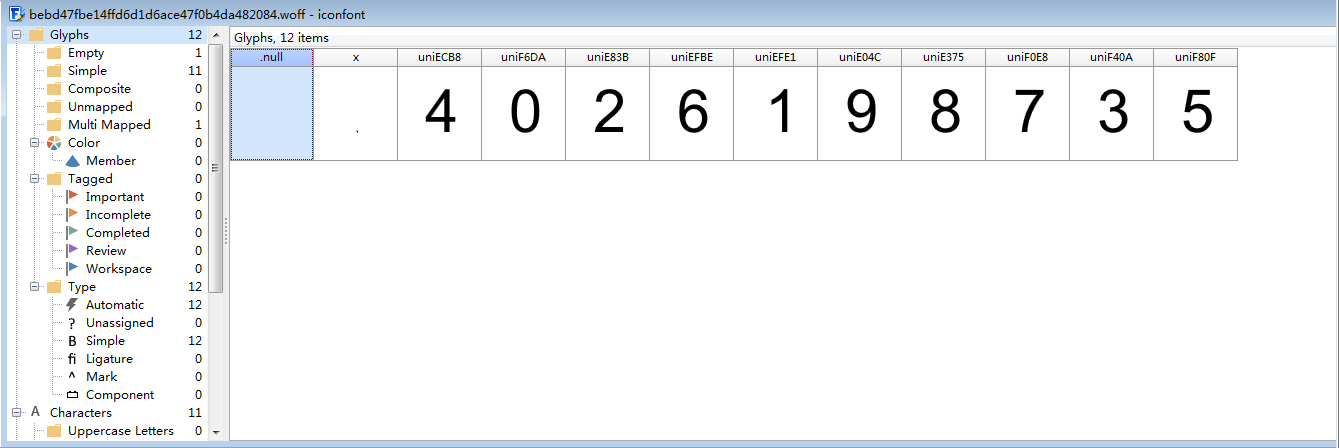
打开软件后,再打开我们下载的字体文件,可以看到数字2和8分别对应的是uniE83B和uniE375,和前面看到的编码是一致的。
那么我们下载好字符集之后,只要将其中的字符编码和数字对应的信息提取出来,再把网页源码中的字符编码替换掉,就能得到我们想要的数据了。这里要用到一个三方库fontTools,利用fontTools可以获取每一个字符对象,这个对象你可以简单的理解为保存着这个字符的形状信息,而且编码可以作为这个对象的id,具有一一对应的关系。不过这里还有一个问题,就是网页每次使用的字符集是随机变化的,我们也就无法使用一个固定的字符集去做到反爬。
解决思路如下:先保存一个字体文件(比如base.woff),然后解析其数字和编码的对应关系,然后爬取的时候把新的字体文件下载下来(比如online.woff),网页中的一个数字的编码(比如ABCD),我们先通过编码ABCD找到这个字符在online.woff中的对象,并且把它和base.woff中的对象逐个对比,直到找到相同的对象,然后获取这个对象在base.woff中的编码,再通过编码确认是哪个数字。
二、主要代码
解析下载的字体文件,由于字体文件中有多余的字符,需要舍弃掉。
# 解析字体库
def parse_ttf(font_name):
"""
:param font_name: 字体文件名
:return: 字符-数字字典
"""
base_nums = ['', '', '', '', '', '', '', '', '', '']
base_fonts = ['uniEB84', 'uniF8CA', 'uniEB66', 'uniE9DB', 'uniE03C',
'uniF778', 'uniE590', 'uniED12', 'uniEA5E', 'uniE172']
font1 = TTFont('base.woff') # 本地保存的字体文件
font2 = TTFont(font_name) # 网上下载的字体文件 uni_list = font2.getGlyphNames()[1:-1] # 去掉头尾的多余字符
temp = {}
# 解析字体库
for i in range(10):
uni2 = font2['glyf'][uni_list[i]]
for j in range(10):
uni1 = font1['glyf'][base_fonts[j]]
if uni2 == uni1:
temp["&#x" + uni_list[i][3:].lower() + ";"] = base_nums[j]
return temp
解析网页源码,把其中的编码替换成数字,这里选择把网页源码保存下来,这样的话编码就不会改变,也就能正确的解析。
# 解析网页得到数字信息
def get_nums(font_dict):
"""
:param font_dict: 字符-数字字典
:return: 由评分、评分人数、票房和票价组成的列表
"""
num_list = []
with open('html', 'r', encoding='utf-8') as f:
for line in f.readlines():
lst = re.findall('(&#x.*?)<', line)
if lst:
num = lst[0]
for i in font_dict.keys():
if i in num:
num = num.replace(i, font_dict[i])
num_list.append(num)
return num_list
三、运行结果

完整代码已上传到GitHub!
【Python3爬虫】猫眼电影爬虫(破解字符集反爬)的更多相关文章
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python之爬虫-猫眼电影
Python之爬虫-猫眼电影 #!/usr/bin/env python # coding: utf-8 import json import requests import re import ti ...
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- 【Python3爬虫】大众点评爬虫(破解CSS反爬)
本次爬虫的爬取目标是大众点评上的一些店铺的店铺名称.推荐菜和评分信息. 一.页面分析 进入大众点评,然后选择美食(http://www.dianping.com/wuhan/ch10),可以看到一页有 ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第六节:反爬策略研究
之前的章节也略有提及反爬策略,本节,我们就来系统的对反爬.反反爬的种种,做一个了结. 从防盗链说起: 自从论坛兴起的时候,网上就有很多人会在论坛里发布一些很棒的文章,与当下流行的“点赞”“分享”一样, ...
- python 爬虫 汽车之家车辆参数反爬
水平有限,仅供参考. 如图所示,汽车之家的车辆详情里的数据做了反爬对策,数据被CSS伪类替换. 观察 Sources 发现数据就在当前页面. 发现若干条进行CSS替换的js 继续深入此JS 知道了数据 ...
- 我去!爬虫遇到JS逆向AES加密反爬,哭了
今天准备爬取网页时,遇到『JS逆向AES加密』反爬.比如这样的: 在发送请求获取数据时,需要用到参数params和encSecKey,但是这两个参数经过JS逆向AES加密而来. 既然遇到了这个情况,那 ...
- python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests.BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名.图片.名称.演 ...
随机推荐
- 处理Python2.7读写文件中的中文乱码问题
1.设置默认编码 在Python代码中的任何地方出现中文,编译时都会报错,这时可以在代码的首行添加相应说明,明确utf-8编码格式,可以解决一般情况下的中文报错.当然,编程中遇到具体问题还需具体分析啦 ...
- Android EventBus技能点梳理
EventBus为Github上的开源项目,地址:https://github.com/greenrobot/EventBus 疑问:1. 现在都是Android Studio创建的项目,如何导入这些 ...
- tf.contrib.slim add_arg_scope
上一篇文章中我们介绍了arg_scope函数,它在每一层嵌套中update当前字典中参数形成新的字典,并入栈.那么这些参数是怎么作用到代码块中的函数的呢?比如说如下情况: with slim.arg_ ...
- Oracle DBLINK的相关知识整理
一.DBLINK(Database Link)概念 dblink,顾名思义就是数据库的链接.当我们要跨本地数据库访问另一个数据库中的表的数据时,在本地数据库中就必须要创建远程数据库的dblink,通过 ...
- window7环境下ZooKeeper的安装及运行
简介 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提 ...
- Spring源码学习-容器BeanFactory(二) BeanDefinition的创建-解析前BeanDefinition的前置操作
写在前面 上文 Spring源码学习-容器BeanFactory(一) BeanDefinition的创建-解析资源文件主要讲Spring容器创建时通过XmlBeanDefinitionReader读 ...
- 单点登录实现原理(SSO)
简介 单点登录是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统的保护资源,若用户在某个应用系统中进行注销登录,所有的应用系统都不能再直接访问保护资源,像一些知名的大型网站,如:淘 ...
- 常用输入的js验证
身份证 var idnub = document.getElementById('idnub').value; if(idnub.length > 1){ var reg = /(^\d{15} ...
- scrapy的基本语法
1.创建爬虫: scrapy genspider爬虫名 域名 注意:爬虫的名字不能和项目名相同 2. scrapy list --展示爬虫应用列表 scrapy crawl爬虫应用名称 ...
- leetcode-查找和替换模式
一.题目描述 你有一个单词列表 words 和一个模式 pattern,你想知道 words 中的哪些单词与模式匹配.如果存在字母的排列 p ,使得将模式中的每个字母 x 替换为 p(x) 之后,我 ...